
How To Convert DataFrame To Pickle File?
Table Of Contents:
- Syntax ‘isna( )’ Method In Pandas.
- Examples ‘isna( )’ Method.
(1) Syntax:
DataFrame.to_pickle(path, compression='infer', protocol=5, storage_options=None)Description:
Convert DataFrame To Pickle File.
Parameters:
- path: str, path object, or file-like object – String, path object (implementing
os.PathLike[str]), or file-like object implementing a binarywrite()function. File path where the pickled object will be stored. - compression: str or dict, default ‘infer’ – For on-the-fly compression of the output data. If ‘infer’ and ‘path’ is path-like, then detect compression from the following extensions: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ or ‘.tar.bz2’ (otherwise no compression). Set to
Nonefor no compression. Can also be a dict with key'method'set to one of {'zip','gzip','bz2','zstd','tar'} and other key-value pairs are forwarded tozipfile.ZipFile,gzip.GzipFile,bz2.BZ2File,zstandard.ZstdCompressorortarfile.TarFile, respectively. As an example, the following could be passed for faster compression and to create a reproducible gzip archive:compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1}. - protocol: int – Int which indicates which protocol should be used by the pickler, default HIGHEST_PROTOCOL (see [1] paragraph 12.1.2). The possible values are 0, 1, 2, 3, 4, 5. A negative value for the protocol parameter is equivalent to setting its value to HIGHEST_PROTOCOL.
- storage_options: dict, optional – Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to
urllib.request.Requestas header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded tofsspec.open. Please seefsspecandurllibfor more details, and for more examples on storage options refer here.
(2) Examples Of to_pickle() Method:
Example-1:
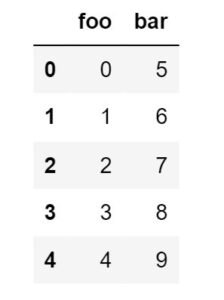
original_df = pd.DataFrame({"foo": range(5), "bar": range(5, 10)})
original_dfOutput:
# Pickling The DataFrame
original_df.to_pickle("./dummy.pkl") Output:
# UnPickling The DataFrame
unpickled_df = pd.read_pickle("./dummy.pkl")
unpickled_dfOutput: