What Is Bias & Variance Tradeoff?
Table Of Contents:
- What Is Bias & Variance?
- Problem With High Bias & High Variance.
- Way To Reduce High Bias & Variance.
- What Is Bias & Variance Tradeoff?
(1) What Is Bias & Variance ?
Bias:
- Bias in collecting sample data set refers to the tendency of inclining towards particular group or community based on the preference of data collector.
- High bias in the data set will not accurately represents the entire population.
- Hence your statistical analysis will be wrong about the population.
Variance:
- Variance in the sample dataset refers to, how far the data points are there from the mean value and from each other.
- You will not be able to find the trend or commonness in the dataset if you have high variance in the dataset.
- Your statistical analysis will not be able to find any pattern or trend in the dataset, hence you will not be able to predict anything.
(2) Problem With High Bias & Variance ?
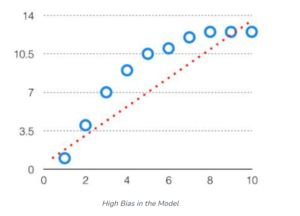
High Bias Problem:
- High bias in the dataset will not represent the entire population, hence will fail to give any correct statement about the population.
- If you have bias in your Machine Learning model it will cause you underfitting the training dataset.
- Because a High Bias model pays very little attention to the training data and oversimplifies the model.
- It always leads to high error on training and test data.
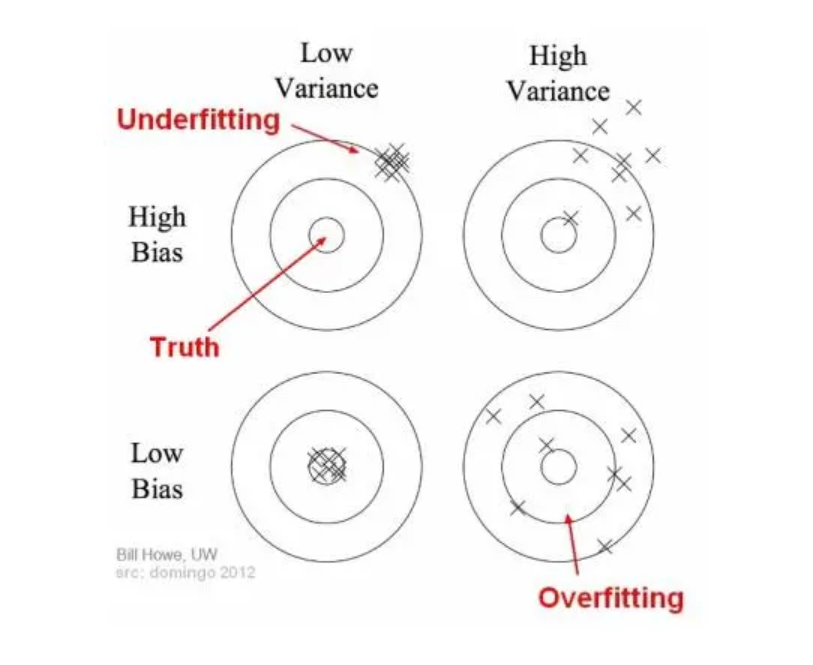
- Low Bias: A low bias model will make fewer assumptions about the form of the target function.
- High Bias: A model with a high bias makes more assumptions, and the model becomes unable to capture the important features of our dataset. A high bias model also cannot perform well on new data.
Characteristics of a High Bias Model:
Underfitting: A model with High Bias tends to underfit the data as it oversimplifies the solution by failing to learn how to train the data efficiently. This results in a linear function.
Oversimplification: Due to the model being too simple, the biased model is unable to learn complex features of a training data, thus, making it inefficient when solving complex problems.
Low Training Accuracy: Due to the inability to correctly process training data, the biased model shows high-training loss resulting in low-training accuracy.
Examples:
- Low Bias Models: Decision Trees, k-Nearest Neighbours and Support Vector Machines.
- High Bias Models: Linear Regression, Linear Discriminant Analysis and Logistic Regression.
High Variance Problem:
- High Variance in the dataset will effect your analysis by not able to find the trend or pattern in the dataset.
- High variance in sample data set means your data points are scattered all around the place.
- The model with high variance has a very complex fit to the training data and thus is not able to fit accurately on the data which it hasn’t seen before.
- As a result, such models perform very well on training data but have high error rates on test data.
- When a model is high on variance, it is then said to as Overfitting of Data.
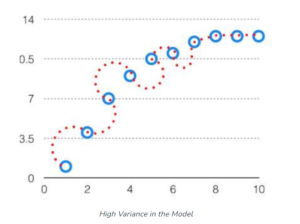
- The variance is an error from sensitivity to small fluctuations in the training set.
- High variance may result from an algorithm modeling the random noise in the training data (overfitting).
- Low Variance: means there is a small variation in the prediction of the target function with changes in the training data set..
- High Variance: shows a large variation in the prediction of the target function with changes in the training dataset.
Characteristics of a High Variance Model:
Overfitting: A model with High Variance tends to overfit the data as it overcomplicates the solution and fails to generalize new test data. This results in a non-linear function.
Overcomplication: Due to the model being too complex, the model learns a much more complex curve and fails to work efficiently on simple problems.
Low Testing Accuracy: Although these models tend to work well on training data with high accuracy, they fail to efficiently work on test data where they will show a huge test data loss.
Examples:
- Low Bias Models: Linear Regression, Logistic Regression, and Linear discriminant analysis.
- High Bias Models: Decision tree, Support Vector Machine, and K-nearest neighbors.
- Nonlinear Machine Learning algorithms often have high variance due to their high flexibility.
(3) Way To Reduce High Bias & Variance ?
Way To Reduce High Bias:
- Increase the input features as the model is under-fitted.
- Decrease the regularization term.
- Use more complex models, such as including some polynomial features.
Way To Reduce High Variance:
- Reduce the input features or a number of parameters as a model is overfitted.
- Do not use a complex model.
- Increase the training data.
- Increase the Regularization term.
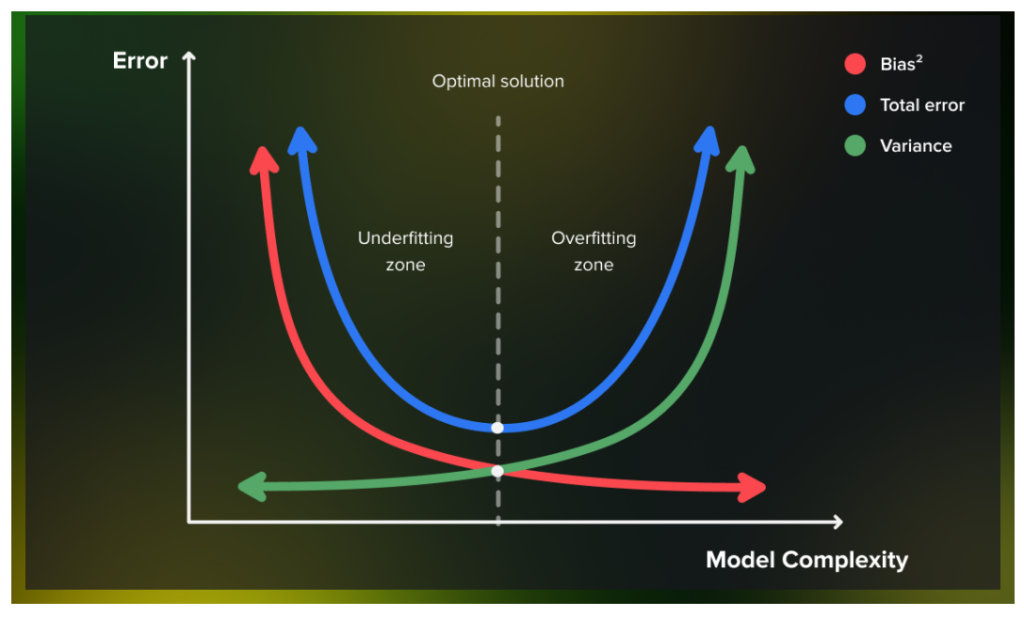
(4) What Is Bias & Variance Tradeoff ?
- As seen above, if the algorithm is too simple, it will have a high bias and a low variance.
- Similarly, if the algorithm is too complex, it will have a high variance and a low bias. Therefore, it is clear that:
- “Bias and variance are complements of each other”.
- The increase of one will result in the decrease of the other and vice versa.
- Hence, finding the right balance of values is known as the Bias-Variance Tradeoff.
(5) Conclusion
- The combination of low bias and low variance shows an ideal machine-learning model.
- However, it is not possible practically.
- Bias-Variance trade-off is about finding the sweet spot to make a balance between bias and variance errors.
- An ideal algorithm should neither underfit nor overfit the data.
- The end goal of all Machine Learning Algorithms is to produce a function that has both low-bias and low-variance.
- But, in the real world, achieving it is very difficult due to an unknown best target function.
- The goal is to find an iterative process through which we can keep improving our Machine Learning Algorithm so that its predictions will improve.