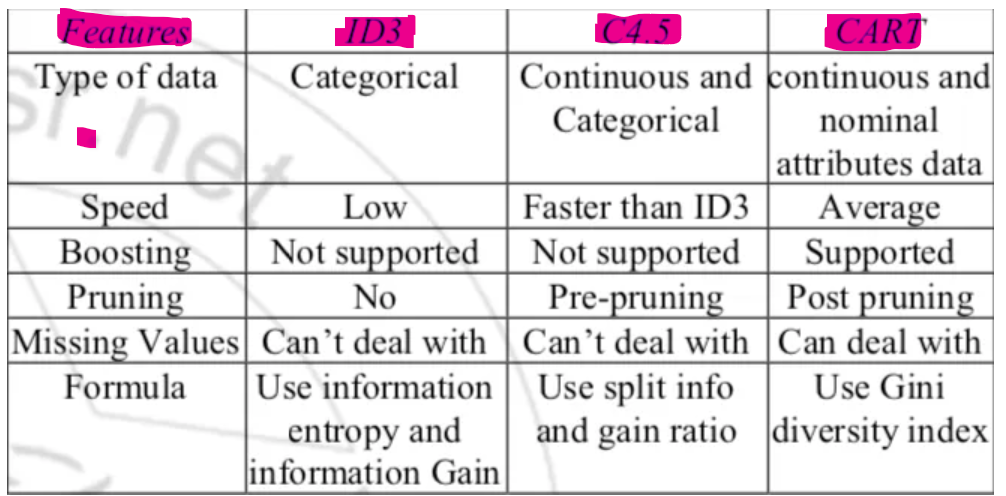
CART, C4.5, ID3 Algorithms
CART:
- CART (Classification and Regression Trees).
- CART is a versatile algorithm that can be used for both classification and regression tasks.
- It constructs binary decision trees, where each internal node represents a splitting criterion on a feature, and each leaf node represents a class label or a regression value.
- The splitting criterion in CART is determined by optimizing a cost function, such as the Gini index for classification or the mean squared error for regression.
- The algorithm recursively partitions the data based on the selected feature and splits, creating branches until a stopping condition is met.
- For classification, the majority class label in a leaf node is assigned to instances falling into that region, while for regression, the average value of instances in a leaf node is assigned.
- CART allows for pruning, where unnecessary branches are removed to reduce overfitting and improve generalization.
ID3:
- ID3 (Iterative Dichotomiser 3).
- ID3 is a decision tree algorithm primarily used for classification tasks.
- It constructs multi-way (non-binary) decision trees, where each internal node represents a splitting criterion on a feature, and each leaf node represents a class label.
- The splitting criterion in ID3 is based on the concept of information gain, which measures the reduction in entropy (or alternatively, the Gini index) achieved by a split.
- The algorithm follows a top-down, greedy approach, where it selects the feature with the highest information gain at each node to create splits.
- ID3 continues recursively until either all instances in a node belong to the same class, or there are no more features to split on.
- ID3 does not handle missing values well and can create overfit trees that are sensitive to noisy or irrelevant features.
C4.5:
- C4.5 algorithm is improved over the ID3 algorithm, where “C” shows the algorithm is written in C and the 4.5 specific version of the algorithm.
- splitting criterion used by C4.5 is the normalized information gain (difference in entropy).
- The attribute with the highest normalized information gain is chosen to make the decision.
- The C4.5 algorithm then recurses on the partitioned sub lists.