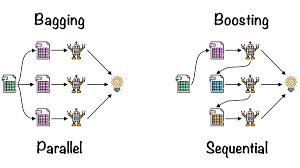
Bagging, Boosting & Stacking Technique
Introduction:
- Bagging and boosting are two ensemble learning techniques commonly used in machine learning.
- Both approaches aim to improve the predictive performance of individual models by combining multiple models together.
- However, they differ in how they construct and combine the models.
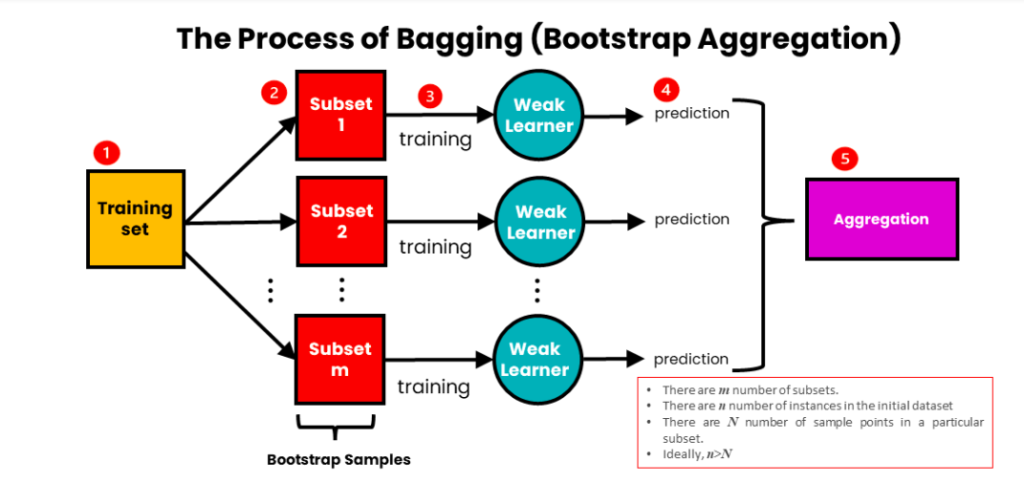
(1) Bagging Technique:(Bootstrap Aggregating):
- Bagging involves creating multiple copies of the original training dataset through a technique called bootstrapping.
- Bootstrapping randomly samples the training data with replacement, resulting in different subsets of data for each model.
- Each model in the ensemble is trained independently on one of the bootstrapped datasets.
- Bagging typically uses majority voting (for classification) or averaging (for regression) to combine the predictions of the individual models.
- The main goal of bagging is to reduce variance and improve the stability and robustness of the predictions.
Note:
- We use bagging for combining weak learners of high variance.
- Bagging aims to produce a model with lower variance than the individual weak models.
- These weak learners are homogenous, meaning they are of the same type.
Bootstrapping:
- Bootstrapping is a statistical resampling technique used to estimate the variability of a statistic or make inferences about a population based on a sample.
- It involves generating multiple “bootstrap samples” by randomly sampling from the original dataset with replacement.
- For each model, we need to take a sample of data, but we need to be very careful while creating these samples of data. Because if we randomly take the data, in a single sample we will end up with only one target class or the target class distribution won’t be the same. This will affect model performance.
- To overcome this we need a smart way to create these samples, known as bootstrapping samples.
- Bootstrapping is a statistical method to create sample data without leaving the properties of the actual dataset. The individual samples of data are called bootstrap samples.
- Each sample is an approximation for the actual data. These individual sample has to capture the underlying complexity of the actual data. All data points in the samples are randomly taken with replacement.
Here’s how the bootstrapping process works:
Starting with the original dataset: Suppose you have a dataset with a certain number of observations or data points.
Random sampling with replacement: The bootstrapping process involves randomly selecting observations from the original dataset, one at a time, to form a new sample. After each selection, the chosen observation is put back into the dataset, and the process is repeated. This sampling with replacement allows for the possibility of selecting the same observation multiple times or excluding others entirely.
Creating bootstrap samples: Repeat the random sampling process multiple times to create a set of bootstrap samples. Each bootstrap sample has the same number of observations as the original dataset, but some observations may be duplicated, while others may be left out.
Estimating statistics or making inferences: With the generated bootstrap samples, statistical analysis can be performed. For example, you can compute a statistic of interest (e.g., mean, median, standard deviation) for each bootstrap sample. These statistics represent estimates of the population parameter.
Assessing variability or constructing confidence intervals: By examining the distribution of the statistics obtained from the bootstrap samples, you can assess the variability or uncertainty associated with the estimated statistic. Confidence intervals can be constructed from the bootstrap distribution to provide a range within which the true population parameter is likely to fall.
Aggregating:
- The individual weak learners are trained independently from each other.
- Each learner makes independent predictions.
- The results of those predictions are aggregated at the end to get the overall prediction.
- The predictions are aggregated using either max voting or averaging.
Max Voting:
- It is commonly used for classification problems that consist of taking the mode of the predictions (the most occurring prediction).
- It is called voting because like in election voting, the premise is that ‘the majority rules’.
- Each model makes a prediction.
- A prediction from each model counts as a single ‘vote’.
- The most occurring ‘vote’ is chosen as the representative for the combined model.
Averaging:
- It is generally used for regression problems. It involves taking the average of the predictions.
- The resulting average is used as the overall prediction for the combined model.
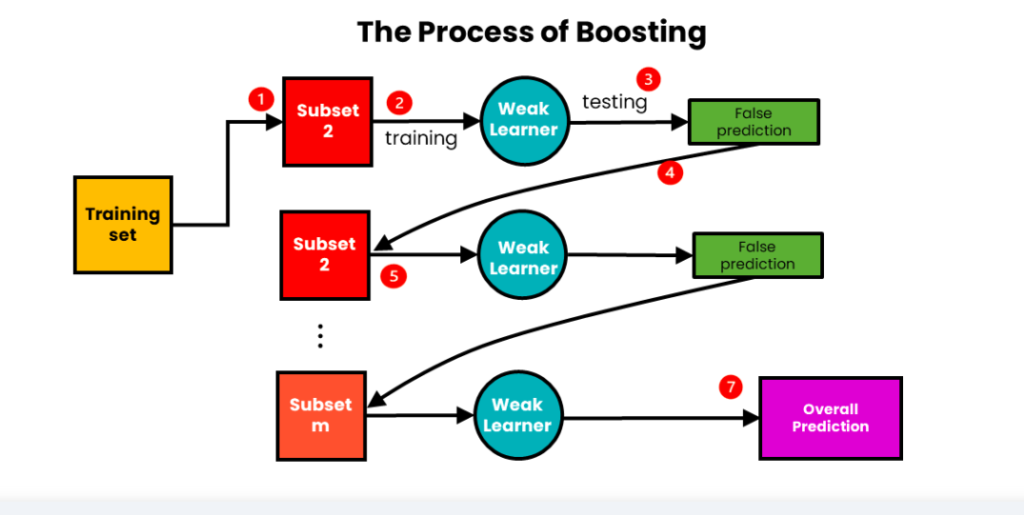
(2) Boosting Technique:
- Boosting is an iterative technique that builds a sequence of models, where each subsequent model focuses on correcting the mistakes made by the previous models.
- The training instances are assigned weights, and initially, each instance has equal weight.
- During each iteration, the algorithm places more emphasis on the misclassified instances from previous iterations by adjusting the weights.
- The subsequent models are trained to prioritize the misclassified instances based on the updated weights.
- Boosting combines the predictions of all the models using weighted voting (for classification) or weighted averaging (for regression).
- The main goal of boosting is to reduce bias and improve the overall accuracy of the ensemble by iteratively learning from the mistakes of previous models.
Note:
- We use Boosting to combine weak learners with high bias.
- Boosting aims to produce a model with a lower bias than that of the individual models.
- Like in bagging, the weak learners are homogeneous.
Weighted Averaging:
- Weighted averaging involves giving all models different weights depending on their predictive power.
- In other words, it gives more weight to the model with the highest predictive power.
- This is because the learner with the highest predictive power is considered the most important.
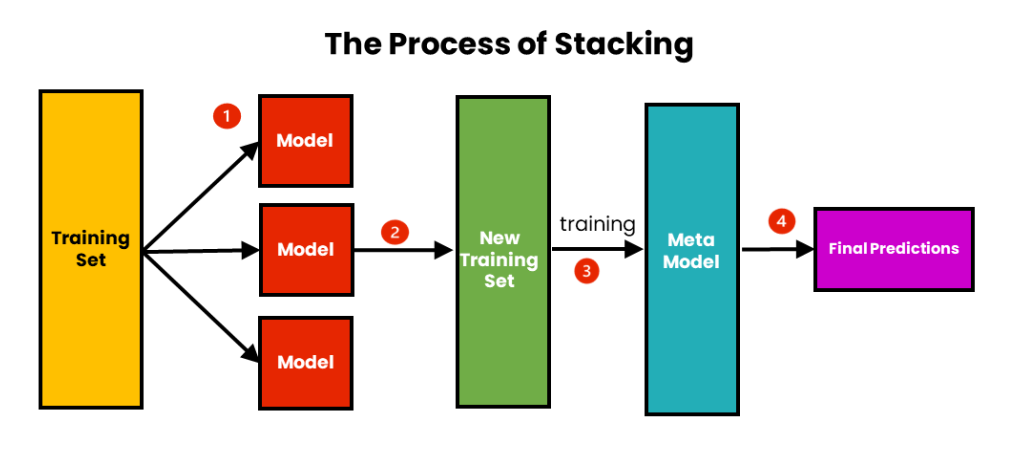
(3) Stacking Technique:
- We use stacking to improve the prediction accuracy of strong learners.
- Stacking aims to create a single robust model from multiple heterogeneous strong learners.
- Stacking, also known as stacked generalization, is an ensemble learning technique that combines multiple predictive models to improve overall performance.
- It involves training a meta-model that learns how to best combine the predictions of the individual models.
Data Split:
- The original dataset is typically divided into two or more subsets: the training set and the holdout set (also known as the validation set or test set).
- The training set is further divided into K-folds for cross-validation purposes.
Base Models:
- Several diverse base models are selected to form the initial ensemble.
- Each base model is trained independently on the K-1 folds of the training set and evaluated on the remaining fold.
Generate Predictions:
- After training the base models, predictions are generated for each fold in the training set and the holdout set.
- For the training set, predictions from the base models are obtained for each fold. These predictions are used as features for the meta-model.
- For the holdout set, predictions from the base models are directly used for evaluation.
Meta-Model:
- A meta-model (also called a blender or aggregator) is trained using the predictions from the base models on the training set.
- The meta-model takes the base model predictions as features and learns how to combine them effectively to make the final prediction.
- The meta-model is trained to minimize the overall error or maximize performance on the holdout set.
Final Prediction:
- Once the meta-model is trained, it can be used to make predictions on new, unseen data.
- The base models generate predictions for the new data, which are then fed into the meta-model for the final prediction.