Bias Vs Variance
Table Of Contents:
- Introduction.
- Errors In Machine Learning.
- What Is Bias?
- Why Does Bias Occurs In Model?
- Effect Of Bias In Our Model.
- Way To Reduce High Bias.
- What Is Variance?
- Why Does Variance Occurs In Model?
- Effect Of Variance In Our Model.
- Way To Reduce High Variance.
- What Is Bias Variance Trade-Off?
(1) Introduction.
- Bias and variance are two important concepts in machine learning that help in understanding the behaviour and performance of a model.
- They represent different sources of error in a machine learning algorithm and can provide insights into how well the model is generalizing to new, unseen data.
- Bias and Variance help us in parameter tuning and deciding better-fitted models among several built.
(2) Errors in Machine Learning?
- A supervised Machine Learning model aims to train itself on the input variables(X) in such a way that the predicted values(Y) are as close to the actual values as possible (Modafinil).
- This difference between the actual values and predicted values is the error and it is used to evaluate the model.
- The error for any supervised Machine Learning algorithm comprises 3 parts:

- Bias error
- Variance error
- The noise
- While the noise is the irreducible error that we cannot eliminate, the other two i.e. Bias and Variance are reducible errors that we can attempt to minimize as much as possible.
(1) Error Due To Bias.
- An error due to Bias is the distance between the predictions of a model and the true values.
- In this type of error, the model pays little attention to training data oversimplifies the model and doesn’t learn the patterns.
- The model learns the wrong relations by not taking into account all the features
(2) Error Due To Variance
- Variability of model prediction for a given data point or a value that tells us the spread of our data.
- In this type of error, the model pays a lot of attention to training data, memorizing it instead of learning from it.
- A model with a high variance error is not flexible enough to generalize the data it hasn’t seen before.
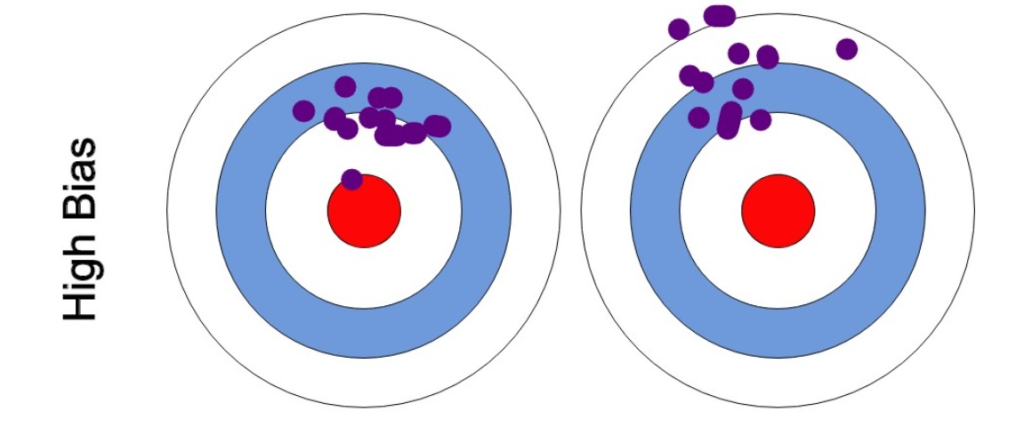
(3) What Is Bias ?
- Bias refers to the error introduced by the assumptions made by a model when trying to approximate the true underlying relationship between features and the target variable.
- A model with high bias tends to oversimplify the problem and make strong assumptions, leading to underfitting.
- In other words, the model is not able to capture the complexity of the data and has a high bias towards a particular set of assumptions.
- High bias can result in a model that consistently performs poorly on both the training and test data.

To make predictions, our model will analyze our data and find patterns in it.
Using these patterns, we can make generalizations about certain instances in our data.
Our model after training learns these patterns and applies them to the test set to predict them.
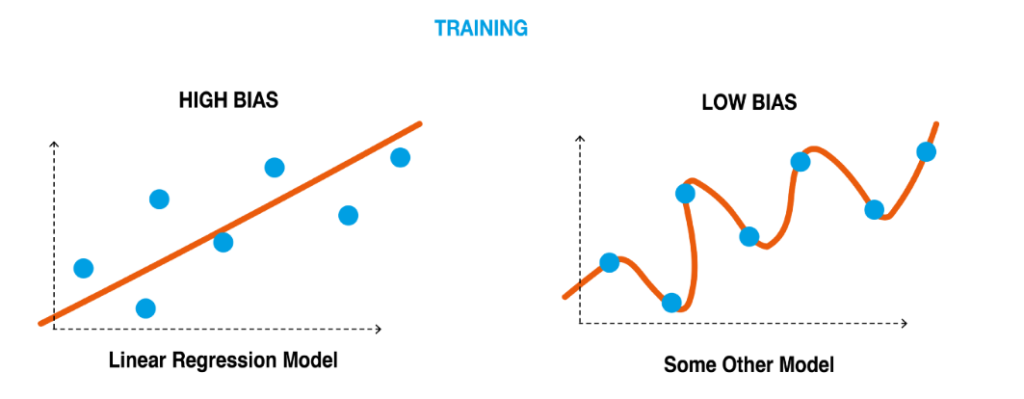
Bias is the difference between our actual and predicted values. Bias is the simple assumptions that our model makes about our data to be able to predict new data.

When the Bias is high, assumptions made by our model are too basic, and the model can’t capture the important features of our data.
This means that our model hasn’t captured patterns in the training data and hence cannot perform well on the testing data too.
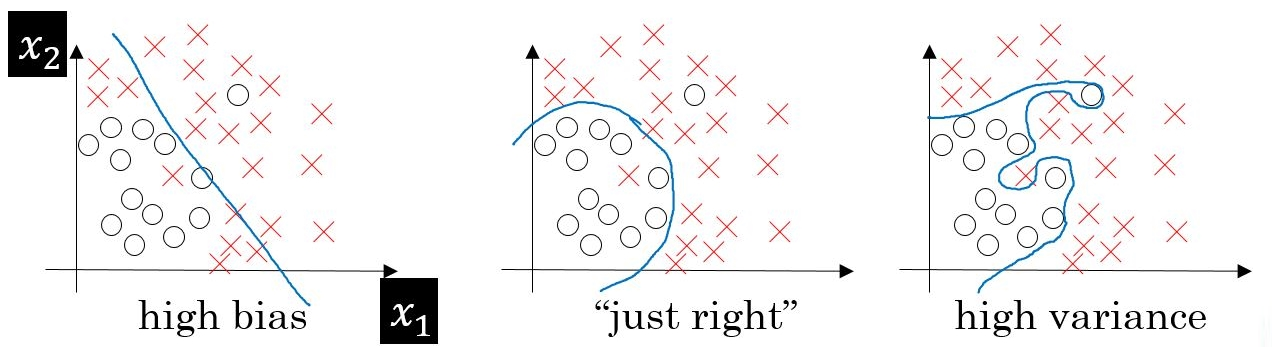
- If this is the case, our model cannot perform on new data and cannot be sent into production.
This instance, where the model cannot find patterns in our training set and hence fails for both seen and unseen data, is called Underfitting.

- The below figure shows an example of Underfitting. As we can see, the model has found no patterns in our data and the line of best fit is a straight line that does not pass through any of the data points.
- The model has failed to train properly on the data given and cannot predict new data either.
(4) Why Does Bias Occurs In Model?
- Bias occurs in a model due to the simplifying assumptions made during the learning process, which can result in an underestimation or overestimation of the true relationship between the features and the target variable. Several factors contribute to the occurrence of bias:
Model Complexity: If a model is too simple or has limited capacity, it may not be able to capture the underlying patterns or complexities in the data. This can lead to a biased representation of the relationship between the features and the target variable.
Incorrect Assumptions: Models often make assumptions about the data or the relationship between features and the target variable. If these assumptions are incorrect or do not align with the true data generation process, bias can be introduced. For example, assuming a linear relationship when the true relationship is non-linear can lead to biased predictions.
Insufficient Features: If the model does not have access to sufficient or relevant features that provide a comprehensive representation of the data, it may result in bias. In such cases, the model lacks the necessary information to accurately capture the underlying relationships.
Overgeneralization: Bias can occur when a model generalizes too much from limited training data. If the training data does not fully represent the variations and complexities present in the overall population, the model may oversimplify the problem and introduce bias.
Sampling Bias: Bias can also arise from sampling issues, such as when the training data is not representative of the overall population. If the training data is skewed or contains systematic errors, the model may be biased towards the patterns present in the training data but not in the general population.
Data Quality: Biased or noisy data can lead to biased models. If the training data contains errors, outliers, or systematic biases, the model may learn to replicate or amplify these biases, resulting in biased predictions.
(5) Effect Of Bias In Our Model?
- The presence of bias in a model can have several effects on its performance and predictions:
Underfitting: Bias can lead to underfitting, where the model is too simplistic and fails to capture the underlying patterns and complexities in the data. An underfit model has high bias and performs poorly not only on the training data but also on new, unseen data. It may struggle to make accurate predictions and fail to capture important relationships between the features and the target variable.
Systematic Errors: Bias can introduce systematic errors in the model’s predictions. The model may consistently overestimate or underestimate the true values of the target variable. This can be problematic when making decisions or taking actions based on the model’s predictions, as the bias can lead to incorrect conclusions or suboptimal outcomes.
Lack of Generalization: A biased model may struggle to generalize well to new, unseen data. Since the model’s assumptions or simplifications do not align with the true data generation process, it may fail to capture the full complexity and variations present in the data. As a result, the model’s predictions may be inaccurate when applied to real-world scenarios or different datasets.
Poor Performance on Test Data: A biased model is likely to perform poorly on the test data, which represents unseen data. The model’s predictions may deviate significantly from the true values, leading to high errors and low accuracy. This indicates that the model is not effectively capturing the underlying relationships in the data and is limited in its predictive capabilities.
Lack of Robustness: Bias can make a model sensitive to changes in the input data or variations in the problem domain. The model’s predictions may be influenced by specific characteristics of the training data, leading to inconsistent or unstable results. This lack of robustness hinders the reliability and trustworthiness of the model’s predictions.
Inability to Capture Complex Relationships: Biased models may struggle to capture complex relationships between features and the target variable. They may oversimplify the problem or make strong assumptions that do not hold true in the real world. This limitation can lead to missed opportunities for more accurate predictions or insights into the underlying data patterns.
- It is important to address bias in a model to improve its performance and ensure reliable predictions.
- This can involve refining the model architecture, incorporating more relevant features, collecting diverse and representative data, and utilizing appropriate regularization techniques to find the right balance between bias and variance.
(6) How To Reduce Bias In Our Model?
- Reducing bias in a model involves several approaches and techniques that aim to capture more complex relationships and improve the model’s ability to generalize. Here are some strategies to reduce bias in your model:
Increase Model Complexity: If your model is too simple and exhibits high bias, consider increasing its complexity. This can involve using a more flexible model architecture that can capture non-linear relationships, such as deep learning models or ensemble methods.
Feature Engineering: Enhance the representation of your data by creating new features that capture additional information or transformations of existing features. Feature engineering can help the model better capture the underlying patterns in the data and reduce bias.
Collect More Data: Increasing the size of your training data can help mitigate bias. By collecting more diverse and representative data, you provide the model with a broader range of examples, reducing the chances of it overgeneralizing or making strong assumptions.
Reduce Noise and Outliers: Cleanse your data by identifying and handling noisy or erroneous data points, as they can introduce bias. Outliers or extreme values that do not reflect the typical behaviour of the data should be carefully analyzed and, if necessary, treated or removed appropriately.
Address Data Imbalance: If your data suffers from class imbalance (when one class has significantly more samples than the other), it can lead to biased predictions. Techniques such as oversampling the minority class or undersampling the majority class can help balance the data and reduce bias.
Regularization Techniques: Regularization methods like L1 or L2 regularization can help reduce bias by preventing the model from overfitting the training data. Regularization adds a penalty term to the loss function, encouraging the model to find a balance between fitting the data and keeping the coefficients small.
Cross-Validation: Utilize cross-validation techniques, such as k-fold cross-validation, to assess the model’s performance across multiple train-test splits of the data. This can help evaluate the model’s generalization ability and identify potential bias issues.
Model Selection: Consider alternative model architectures or algorithms that are known to handle bias better. For example, decision trees or random forests have the ability to capture complex relationships and handle bias to some extent.
Ensemble Methods: Combining multiple models through ensemble techniques, such as bagging or boosting, can help reduce bias. By aggregating the predictions of different models, the ensemble can capture a broader range of patterns and reduce the impact of biased individual models.
- It’s important to note that reducing bias often involves finding the right balance between bias and variance. Overcorrecting bias can lead to increased variance and the risk of overfitting. Regular monitoring and evaluation of model performance are necessary to ensure that bias reduction efforts are effective and do not compromise other aspects of model performance.
(7) What Is Variance ?
Variance is the very opposite of Bias. During training, it allows our model to ‘see’ the data a certain number of times to find patterns in it.
If it does not work on the data for long enough, it will not find patterns and bias will occur.
On the other hand, if our model is allowed to view the data too many times, it will learn very well from only that data.
It will capture most patterns in the data, but it will also learn from the unnecessary data present, or from the noise.
]We can define variance as the model’s sensitivity to fluctuations in the data. Our model may learn from noise. This will cause our model to consider trivial features as important.

- In the above figure, we can see that our model has learned extremely well for our training data, which has taught it to identify cats.
- But when given new data, such as the picture of a fox, our model predicts it as a cat, as that is what it has learned.
- This happens when the Variance is high, our model will capture all the features of the data given to it, including the noise, will tune itself to the data, and predict it very well but when given new data, it cannot predict on it as it is too specific to training data.

- In machine learning, variance refers to the amount of fluctuation or instability in the model’s predictions when trained on different subsets of the training data. It measures the model’s sensitivity to the randomness in the training data.
- More specifically, variance captures how much the predictions of a model vary when different training sets are used.


- Hence, our model will perform really well on testing data and get high accuracy but will fail to perform on new, unseen data.
- New data may not have the exact same features and the model won’t be able to predict it very well.
- This is called Overfitting.
(8) Why Does Variance Occurs In Model?
- A variance occurs in a model due to its sensitivity to the specific instances or noise present in the training data. Several factors contribute to the presence of variance:
Model Complexity: Models with high complexity, such as deep learning models or models with a large number of parameters, have a higher tendency to overfit the training data, resulting in higher variance. When the model is too flexible or complex, it can capture noise and random fluctuations, leading to high variability in its predictions.
Insufficient Training Data: When the training dataset is small, the model may not have enough examples to learn the underlying patterns effectively. This can result in overfitting and high variance, as the model tries to fit the noise, outliers, or specific instances in the limited data.
Lack of Diversity in Training Data: If the training data does not adequately represent the variations and complexities present in real-world scenarios, the model may struggle to generalize well. The model may become sensitive to the specific instances or characteristics of the training set, resulting in high variance when applied to new, unseen data.
Noise and Outliers: Noisy or erroneous data points, as well as outliers, can have a significant impact on the model’s predictions. If the model captures these noise or outlier patterns during training, it can lead to overfitting and high variance. The model may fail to generalize beyond these specific instances, resulting in unstable and inconsistent predictions.
Lack of Regularization: Insufficient or inadequate use of regularization techniques can contribute to higher variance. Regularization methods, such as L1 or L2 regularization, help control the complexity of the model and prevent overfitting. Without proper regularization, the model can become too flexible, leading to high variance.
Sampling Variability: When the training data is randomly sampled from a larger population, different training sets can lead to variations in the model’s predictions. The model’s performance can be influenced by the specific instances included in the training set, resulting in higher variance.
- Reducing variance requires techniques that aim to make the model less sensitive to the specific instances or noise in the training data.
- Regularization methods, cross-validation, ensemble techniques, and feature selection are some approaches to mitigate variance and improve the model’s generalization ability.
- Additionally, increasing the size and diversity of the training data can also help reduce variance by providing the model with a more comprehensive representation of the underlying patterns.
(9) Effect Of Variance In Our Model?
- The presence of variance in a model can have several effects on its performance and predictions:
Overfitting: High variance in a model often leads to overfitting, where the model fits the training data too closely and captures noise or random fluctuations. Overfitting occurs when the model becomes too complex or flexible, memorizing the training data instead of learning the underlying patterns. As a result, the model may have a low error on the training data but performs poorly on new, unseen data.
Poor Generalization: Models with high variance struggle to generalize well to unseen data. They have difficulty capturing the underlying patterns and relationships in the data beyond the specific instances or characteristics of the training set. This lack of generalization leads to inaccurate predictions and lower performance on test or validation data.
Inconsistency: Models with high variance can produce inconsistent results when trained on different subsets of the training data or when presented with slightly different inputs. The model’s predictions can vary significantly, indicating that it is highly sensitive to the specific instances in the training data. This inconsistency makes it challenging to rely on the model for consistent and reliable predictions.
Sensitivity to Noise and Outliers: Models with high variance are highly sensitive to noise and outliers in the data. They may fit these irregularities during training, resulting in predictions that are influenced by these specific instances. This sensitivity can lead to unstable and unreliable predictions, especially in the presence of noisy or outlier data points.
Lack of Robustness: Models with high variance are less robust to variations in the input data or changes in the problem domain. They can be highly affected by small perturbations or variations in the data, leading to different and unpredictable predictions. This lack of robustness hinders the reliability and trustworthiness of the model.
Difficulty in Model Selection: High variance can make it challenging to select the best model among multiple candidates. The model’s performance can vary significantly depending on the training data or specific instances, making it difficult to determine the most suitable model for the given problem.
- To address the issue of high variance, it is important to find the right balance between bias and variance.
- Techniques such as regularization, cross-validation, ensemble methods, and feature selection can help mitigate variance and improve the model’s generalization ability.
- It’s crucial to monitor the model’s performance, evaluate its behaviour on test or validation data, and fine-tune the model to achieve the desired balance and optimal performance.
(10) How To Reduce Variance In Our Model?
- Reducing variance in a model involves several strategies and techniques that aim to make the model less sensitive to the specific instances or noise in the training data.
- Here are some approaches to reduce variance in your model:
Increase Training Data: Providing a larger and more diverse training dataset can help reduce variance. More data allows the model to capture a broader range of patterns and reduces the impact of random fluctuations present in smaller datasets. Collecting additional data or utilizing data augmentation techniques can help increase the size and diversity of the training data.
Regularization: Regularization methods, such as L1 or L2 regularization, introduce a penalty term on the model’s coefficients during training. This helps control the complexity of the model and prevents it from overfitting the training data. Regularization encourages the model to generalize better, reducing variance.
Cross-Validation: Utilize cross-validation techniques, such as k-fold cross-validation, to assess the model’s performance across multiple train-test splits of the data. Cross-validation provides a more robust estimate of the model’s performance and helps identify potential issues related to variance. It helps evaluate the model’s generalization ability and can guide you in adjusting the model’s complexity.
Ensemble Methods: Ensemble techniques, such as bagging, random forests, or boosting, can help reduce variance by combining multiple models. By averaging or combining the predictions of different models, ensemble methods can smooth out the individual model’s fluctuations and provide more stable and reliable predictions.
Feature Selection: Removing irrelevant or noisy features from the input can help reduce the complexity of the model and mitigate variance. Feature selection techniques can identify the most informative features that contribute to the model’s performance. By focusing on relevant features, the model becomes less sensitive to noise and reduces variance.
Early Stopping: Implement early stopping during the training process to prevent the model from overfitting. Early stopping stops the training when the model’s performance on a validation set starts to deteriorate. It helps find the optimal point where the model achieves a good balance between bias and variance.
Model Simplification: If your model is overly complex, consider simplifying it by reducing the number of layers, nodes, or parameters. A simpler model with fewer degrees of freedom is less likely to overfit and can help reduce variance.
Hyperparameter Tuning: Properly tuning the hyperparameters of your model can help find the right balance between bias and variance. Experiment with different hyperparameter settings and use techniques like grid search or random search to identify the optimal values that reduce variance.
Regular Monitoring and Evaluation: Continuously monitor and evaluate the model’s performance on different datasets, including training, validation, and test sets. Regular evaluation helps you identify if the model is suffering from high variance and allows you to make adjustments accordingly.
- Remember that reducing variance often involves finding a balance between bias and variance. It is important to avoid overcorrecting variance, as it can lead to increased bias or underfitting. Regular monitoring, evaluation, and fine-tuning of the model are crucial to achieve the right balance and improve overall performance.
(11) What Is Bias and Variance Tradeoff?
- The bias-variance tradeoff is a fundamental concept in machine learning that refers to the relationship between the bias and variance of a model.
- It represents the tradeoff or balance between the model’s ability to capture the underlying patterns in the data (low bias) and its sensitivity to noise and random fluctuations (low variance).

- In the above figure, we can see that when bias is high, the error in both testing and training sets is also high.
- If we have a high variance, the model performs well on the testing set, we can see that the error is low but gives high error on the training set.
- We can see that there is a region in the middle, where the error in both training and testing set is low and the bias and variance is in perfect balance.
Trade-off:
- The bias-variance tradeoff arises because reducing one source of error (bias or variance) often leads to an increase in the other.
- This tradeoff occurs due to the inherent complexity of real-world problems and the limitations of the model.

When a model is too simple or has high bias, it may not capture the underlying patterns and relationships in the data. It tends to underfit and has low variance, meaning its predictions are consistent but inaccurate. Increasing the complexity of the model can reduce bias but may increase variance, making it more sensitive to noise and specific instances in the training data.
On the other hand, when a model is too complex or has high variance, it captures noise and random fluctuations in the training data. It tends to overfit and has low bias, meaning it fits the training data closely. Reducing variance often requires simplifying the model, which may increase bias and result in underfitting.
Conclusion:
The goal is to find the right balance between bias and variance that minimizes the overall error on both the training and test data. The optimal model strikes a balance where it captures the underlying patterns in the data without being overly influenced by noise or specific instances.
Achieving the right balance often involves techniques such as regularization, cross-validation, and ensemble methods. Regular monitoring, evaluation, and fine-tuning of the model are crucial to navigate the bias-variance tradeoff and improve the model’s performance.