Evaluation Matrixes
Table Of Contents:
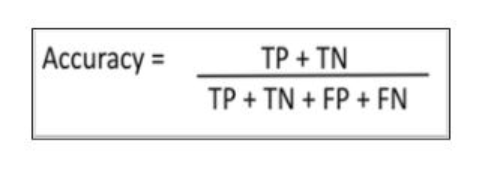
Accuracy
Precision
Recall (TPR, Sensitivity)
Specificity (TNR)
- F1-Score
- FPR (Type I Error)
FNR (Type II Error)
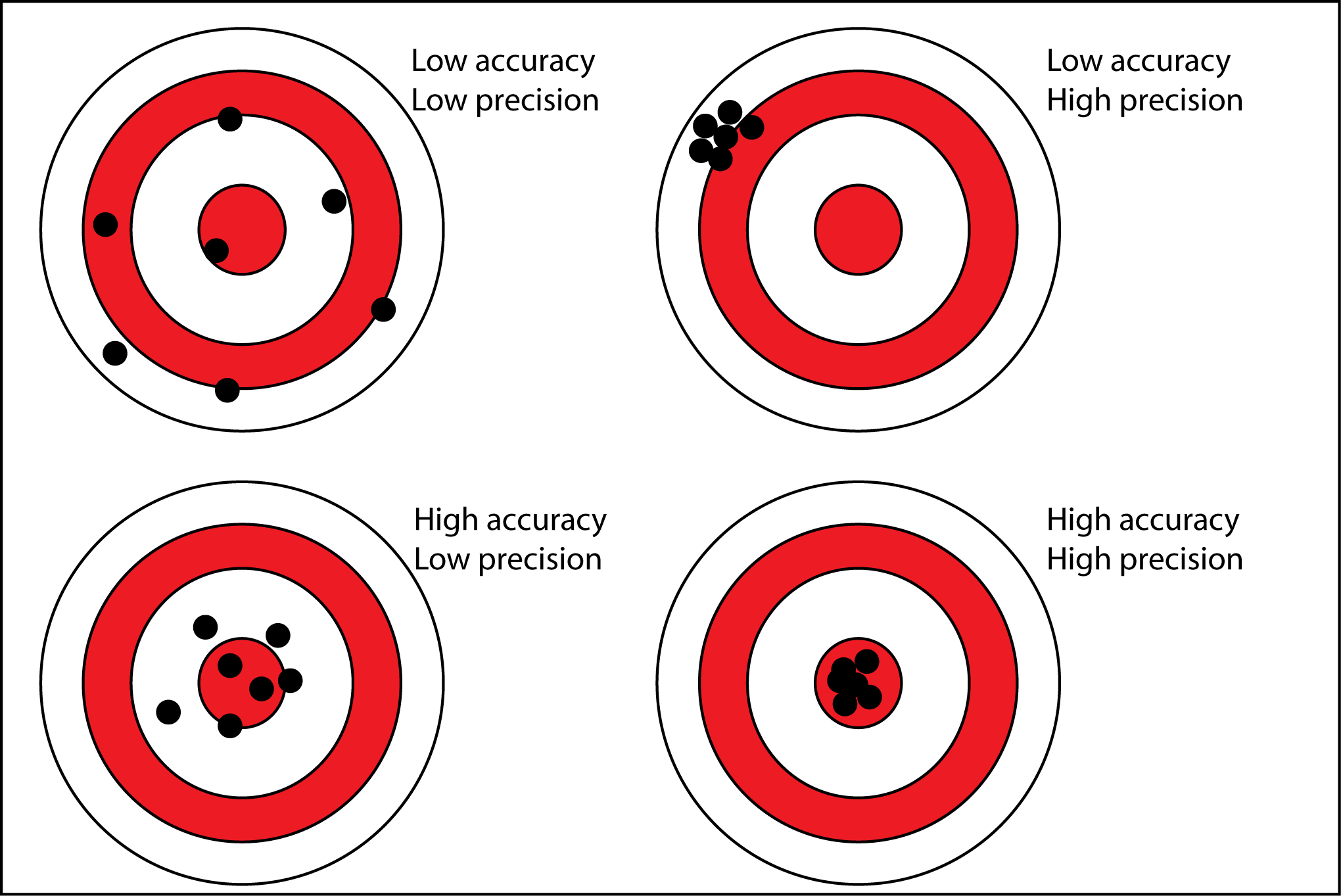
(1) Accuracy:
- Accuracy simply measures how often the classifier makes the correct prediction. It’s the ratio between the number of correct predictions and the total number of predictions.
- The accuracy metric is not suited for imbalanced classes. Accuracy has its own disadvantages, for imbalanced data, when the model predicts that each point belongs to the majority class label, the accuracy will be high. But, the model is not accurate.
- It is a measure of correctness that is achieved in true prediction. In simple words, it tells us how many predictions are actually positive out of all the total positive predicted.
- Accuracy is a valid choice of evaluation for classification problems which are well balanced and not skewed or there is no class imbalance.

(2) Precision:
- It is a measure of correctness that is achieved in true prediction. In simple words, it tells us how many predictions are actually positive out of all the total positive predicted.
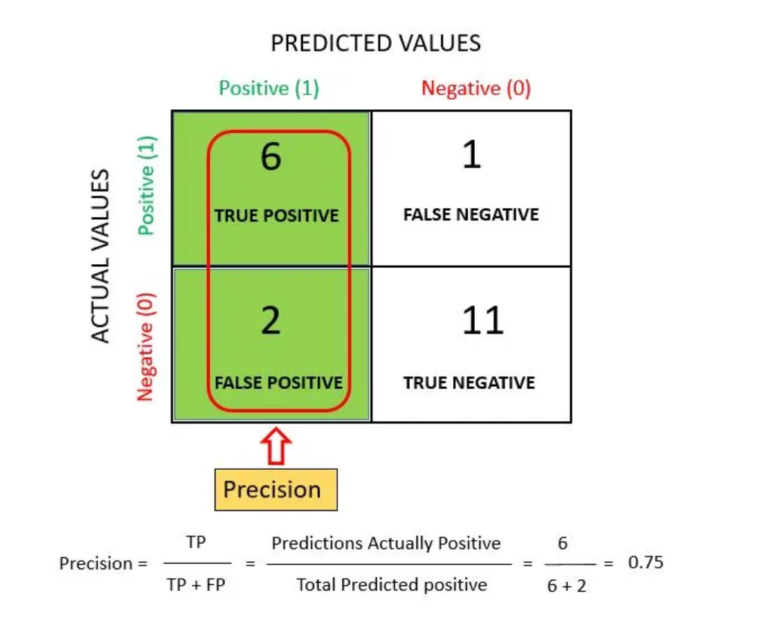
- Precision is defined as the ratio of the total number of correctly classified positive classes divided by the total number of predicted positive classes. Or, out of all the predictive positive classes, how much we predicted correctly. Precision should be high(ideally 1).
- “Precision is a useful metric in cases where False Positive is a higher concern than False Negatives”

Ex 1:- In Spam Detection : Need to focus on precision
Suppose mail is not a spam but model is predicted as spam : FP (False Positive). We always try to reduce FP.
Ex 2:- Precision is important in music or video recommendation systems, e-commerce websites, etc. Wrong results could lead to customer churn and be harmful to the business.
(3) Recall: (TPR, Sensitivity)
- It is a measure of actual observations which are predicted correctly, i.e. how many observations of positive class are actually predicted as positive.
- It is also known as Sensitivity.
- Recall is a valid choice of evaluation metric when we want to capture as many positives as possible.
- Recall is defined as the ratio of the total number of correctly classified positive classes divide by the total number of positive classes.
- Or, out of all the positive classes, how much we have predicted correctly.
- Recall should be high(ideally 1).
- “Recall is a useful metric in cases where False Negative trumps False Positive”


Ex 1:– suppose person having cancer (or) not? He is suffering from cancer but model predicted as not suffering from cancer
Ex 2:- Recall is important in medical cases where it doesn’t matter whether we raise a false alarm but the actual positive cases should not go undetected!
Recall would be a better metric because we don’t want to accidentally discharge an infected person and let them mix with the healthy population thereby spreading contagious virus. Now you can understand why accuracy was a bad metric for our model.
Trick to remember : Precision has Predictive Results in the denominator.
(4) Specificity (TNR)
- Specificity is the ratio of number of actual Nos correctly predicted to the total number of actual Nos.

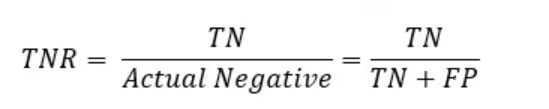
(5) F1-Score
- The F1 score is a number between 0 and 1 and is the harmonic mean of precision and recall. We use harmonic mean because it is not sensitive to extremely large values, unlike simple averages.
- F1 score sort of maintains a balance between the precision and recall for your classifier. If your precision is low, the F1 is low and if the recall is low again your F1 score is low.
- There will be cases where there is no clear distinction between whether Precision is more important or Recall. We combine them!
- In practice, when we try to increase the precision of our model, the recall goes down and vice-versa. The F1-score captures both the trends in a single value.


- F1 score is a harmonic mean of Precision and Recall. As compared to Arithmetic Mean, Harmonic Mean punishes the extreme values more. F-score should be high(ideally 1).
(6) FPR(Type-1 Error)
- In a confusion matrix, a Type I error represents the situation where the model incorrectly classifies a negative instance as positive.
- It means the model predicted the presence of a condition or event when, in reality, it does not exist.
- It is also known as a false positive.

Example:

- In this confusion matrix, the Type I error corresponds to the false positives (FP).
- In other words, it represents the instances that were actually not spam (negative class) but were incorrectly predicted as spam.
- In the example, the Type I error is 8, indicating that the model falsely classified 8 non-spam emails as spam.
- Type I errors are important to consider, especially in situations where the cost or consequences of false positives are significant.
- For instance, in medical testing, a Type I error would occur if a healthy individual is mistakenly identified as having a disease, leading to unnecessary treatment or stress.
- By evaluating Type I errors and other metrics in a confusion matrix, we can assess the performance of a classification model and make informed decisions based on the specific requirements and costs associated with false positives.
(7) FNR(Type-II Error)
- In a confusion matrix, a Type II error represents the situation where the model incorrectly classifies a positive instance as negative.
- It means the model fails to predict the presence of a condition or event when, in reality, it does exist.
- It is also known as a false negative.

Example:
- In this confusion matrix, the Type II error corresponds to the false negatives (FN).
- It represents the instances that were actually spam (positive class) but were incorrectly predicted as not spam.
In the example, the Type II error is 5, indicating that the model falsely classified 5 spam emails as not spam.
Type II errors are important to consider, especially in situations where the consequences of missing positive instances are significant.
For example, in medical testing, a Type II error would occur if a person with a disease is mistakenly identified as healthy, potentially leading to a delayed diagnosis and treatment.
- Evaluating Type II errors and other metrics in a confusion matrix helps assess the performance of a classification model, particularly its ability to correctly identify positive instances.
- It is crucial to strike a balance between minimizing Type II errors and considering other performance metrics, such as precision, recall, and specificity, depending on the specific requirements and costs associated with false negatives.
(8) Is it necessary to check for recall (or) precision if you already have a high accuracy?
- We can not rely on a single value of accuracy in classification when the classes are imbalanced.
- For example, we have a dataset of 100 patients in which 5 have diabetes and 95 are healthy.
- However, if our model only predicts the majority class i.e. all 100 people are healthy even though we have a classification accuracy of 95%.
(9) When to use Accuracy / Precision / Recall / F1-Score?
a. Accuracy is used when the True Positives and True Negatives are more important. Accuracy is a better metric for Balanced Data.
b. Whenever False Positive is much more important use Precision.
c. Whenever False Negative is much more important use Recall.
d. F1-Score is used when the False Negatives and False Positives are important. F1-Score is a better metric for Imbalanced Data.