Cat Boost Algorithms
Table Of Contents:
- What is the CatBoost Algorithm?
- Features Of CatBoost Algorithm.
- Is tuning required in CatBoost?
- When and When Not to Use CatBoost
(1) What Is The Cat Boost Algorithm?
The term CatBoost is an acronym that stands for “Category” and “Boosting.” Does this mean the “Category’ in CatBoost means it only works for categorical features?
The answer is, “No.”
According to the CatBoost documentation, CatBoost supports numerical, categorical, and text features but has a good handling technique for categorical data.
The CatBoost algorithm has quite a number of parameters to tune the features in the processing stage.
“Boosting” in CatBoost refers to the gradient boosting machine learning. Gradient boosting is a machine learning technique for regression and classification problems.
Which produces a prediction model in an ensemble of weak prediction models, typically decision trees.
Gradient boosting is a robust machine learning algorithm that performs well when used to provide solutions to different types of business problems such as
- Fraud detection,
- Recommendation system,
- Forecasting.
- Again, it can return an outstanding result with relatively less data. Unlike other machine learning algorithms that only perform well after learning from extensive data.
- We would suggest you read the article How the gradient boosting algorithms works if you want to learn more about the gradient boosting algorithms functionality.
(2) Features Of Cat Boost Algorithm?
- CatBoost is a gradient boosting algorithm that is specifically designed to work well with categorical features.
- It incorporates several key features and optimizations to handle categorical variables effectively.
- Here are some important features of the CatBoost algorithm:
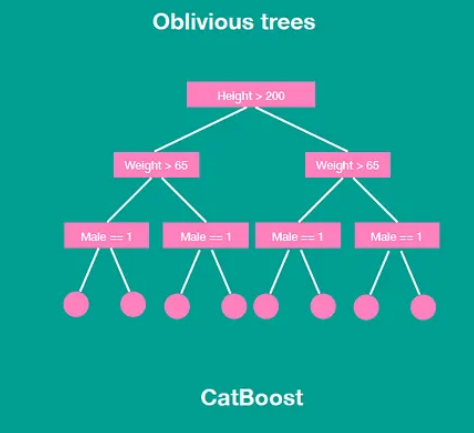
Handling Categorical Features: CatBoost can directly handle categorical features without requiring explicit preprocessing, such as one-hot encoding or label encoding. It internally converts categorical variables into numerical representations using various techniques, including target statistics encoding and combinations of target and frequency encoding.
Ordered Boosting: CatBoost utilizes an ordered boosting algorithm that incorporates permutations of the feature values during tree construction. This helps to reduce the bias caused by the sequential nature of the boosting process and improves the model’s generalization ability.
GPU Support: CatBoost provides GPU support, allowing you to leverage the computational power of GPUs for faster model training and inference. This is particularly beneficial when working with large datasets and complex models.
Automatic Handling of Missing Values: CatBoost has built-in handling for missing values in both categorical and numerical features. It automatically learns how to handle missing values during the training process, eliminating the need for explicit imputation techniques.
Robust to Overfitting: CatBoost incorporates various techniques to combat overfitting, including L2 regularization, random permutations during tree construction, and early stopping based on a holdout dataset. These techniques help prevent the model from memorizing noise and improve its generalization ability.
Feature Importance: CatBoost provides feature importance scores based on how much each feature contributes to reducing the loss function. The importance scores can help identify the most influential features in the dataset and guide feature selection or engineering.
Cross-Validation: CatBoost supports efficient cross-validation with built-in functionality. It offers different types of cross-validation strategies, such as k-fold and stratified k-fold, to evaluate the model’s performance and tune hyperparameters effectively.
Multiclass Classification: CatBoost handles multiclass classification tasks naturally and efficiently. It can directly optimize the multi-log loss objective function, taking advantage of the categorical features’ handling capabilities.
Integration with Scikit-Learn: CatBoost provides a scikit-learn compatible API, making it easy to integrate with the scikit-learn ecosystem. You can use familiar scikit-learn functions, such as
fit(),predict(), andGridSearchCV(), with CatBoost models.
- CatBoost has gained popularity for its ability to handle categorical features effectively, its strong performance on various machine learning tasks, and its user-friendly API. It is available in multiple programming languages, including Python, R, and C++, making it accessible to a wide range of users and developers.
(3) Is Tuning Required In Cat Boost Algorithm?
- Tuning hyperparameters is an essential step in optimizing any machine learning algorithm, including CatBoost.
- While CatBoost provides default hyperparameter values that work reasonably well, tuning the hyperparameters can often lead to improved performance and better model generalization.
- Here are a few reasons why tuning hyperparameters in CatBoost is beneficial:
learning_rate: Controls the step size at each boosting iteration. It determines the impact of each tree on the final prediction. A smaller learning rate makes the model more conservative but may require more iterations to converge.n_estimators: Specifies the maximum number of trees (iterations) in the ensemble. Increasing this value can improve model performance, but it also increases training time.depth: Determines the maximum depth of each decision tree. Deeper trees can capture more complex interactions but may lead to overfitting.subsample: Specifies the fraction of instances to be used for training each tree. It controls the randomness of the training process and helps prevent overfitting.colsample_bylevel: Controls the fraction of features (columns) to be randomly selected at each level of each tree. It introduces randomness and helps reduce overfitting.l2_leaf_reg: Regularization parameter that applies L2 regularization to the leaf weights. It helps to prevent overfitting by adding a penalty for large weights.random_strength: Controls the degree of randomness in feature selection for splits. Higher values result in more randomness and can help the model generalize better.one_hot_max_size: Specifies the maximum number of unique categorical feature values to use one-hot encoding for. Larger values increase memory usage but can capture more information.bagging_temperature: Controls the strength of the temperature parameter for the Softmax function in multiclass classification. Higher values make the model more conservative.border_count: Controls the number of splits considered for categorical features. Higher values increase training time but can improve accuracy.scale_pos_weight: Helps to handle class imbalance by scaling the weights of positive instances.
(4) When and When Not to Use CatBoost
- CatBoost is a powerful gradient boosting algorithm that performs well in a variety of machine learning tasks, particularly when working with categorical features. However, there are certain scenarios where CatBoost may be more or less suitable. Here are some considerations for when to use CatBoost and when to explore other options:
When to use CatBoost:
Categorical Features: CatBoost excels in handling categorical features without explicit preprocessing. If your dataset contains categorical variables, CatBoost’s built-in handling of categorical features can save you preprocessing time and potentially improve model performance.
Large Datasets: CatBoost is designed to handle large-scale datasets efficiently. It implements data parallelism and distributed computing, allowing it to train on datasets that exceed the memory capacity of a single machine.
High-Dimensional Data: CatBoost can handle high-dimensional data well, making it suitable for tasks with a large number of features. It incorporates feature importance ranking, which can help identify the most influential features in your dataset.
Multiclass Classification: CatBoost natively supports multiclass classification tasks and can optimize the multi-logloss objective function. It can handle multiple classes effectively and provide accurate predictions.
Interpretability: CatBoost provides feature importance scores, which can aid in interpreting the model and understanding the impact of different features on the predictions.
When to consider other options:
Small Datasets: While CatBoost can handle small datasets, it may not always provide significant performance improvements over other gradient boosting algorithms like XGBoost or LightGBM. In such cases, it’s worth exploring these alternatives to check if they meet your requirements.
Time and Resource Constraints: CatBoost, like other gradient boosting algorithms, can be computationally expensive, especially with a large number of trees or complex hyperparameter search. If you have strict time or resource constraints, you may consider faster alternatives or optimize the training process.
Streaming Data: CatBoost is primarily designed for batch training, and it doesn’t have built-in support for online or streaming learning. If your data arrives in a streaming fashion, other algorithms like online gradient boosting may be more suitable.
GPU Availability: While CatBoost supports GPU training, if you don’t have access to GPUs or your dataset is relatively small, the performance gain from using GPUs may not justify the additional complexity and resource requirements.
- Ultimately, the choice of whether to use CatBoost or explore other options depends on your specific requirements, dataset characteristics, available resources, and trade-offs between model performance and training time.
- It’s recommended to experiment with different algorithms and evaluate their performance on your task before making a final decision.