Confusion Metrix
Table Of Contents:
- What Is Confusion Metrix?
- Why We Need Confusion Metrix?
- Elements Of Confusion Metrix.
- Examples Of Confusion Metrix.
- Evaluation Matrixes.
(1) Why We Need Confusion Metrix?
In machine learning, Classification is used to split data into categories.
But after cleaning and preprocessing the data and training our model, how do we know if our classification model performs well?
That is where a confusion matrix comes into the picture.
A confusion matrix is used to measure the performance of a classifier in depth.
(2) What Is Confusion Metrix?
- A confusion matrix, also known as an error matrix, is a 2 * 2 table that allows the visualization and evaluation of the performance of a classification model.
- It is a common tool used in machine learning and statistics to assess the accuracy of a model’s predictions.
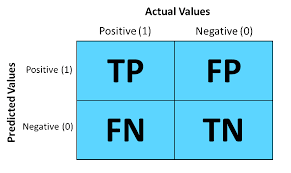
- A confusion matrix is typically constructed based on the predicted labels and the true labels of a set of data points.
- The matrix provides a summary of the counts of
- (TP) = True Positive,
- (TN) = True Negative,
- (FP) = False Positive, and
- (FN) = False Negative predictions made by the model.
(3) Elements Of Confusion Metrix.
It represents the different combinations of Actual vs. predicted values. Let’s define them one by one.
TP: True Positive: The values which were actually positive and were predicted positive.
FP: False Positive: The values which were actually negative but falsely predicted as positive. Also known as Type I Error.
FN: False Negative: The values which were actually positive but falsely predicted as negative. Also known as Type II Error.
TN: True Negative: The values which were actually negative and were predicted negative.
(4) Example Of Confusion Metrix.
- Let’s consider an example of a binary classification problem where we are predicting whether an email is spam (positive class) or not spam (negative class).
- We have a dataset of 100 emails, and we evaluate our model’s predictions using a confusion matrix.
- Here are the results:

In this confusion matrix:
- True Positive (TP): There are 35 emails that are actually spam (positive class) and correctly predicted as spam.
- True Negative (TN): There are 52 emails that are actually not spam (negative class) and correctly predicted as not spam.
- False Positive (FP): There are 8 emails that are actually not spam (negative class) but incorrectly predicted as spam.
- False Negative (FN): There are 5 emails that are actually spam (positive class) but incorrectly predicted as not spam.
Performance Metrix:
With these values in the confusion matrix, we can calculate various performance metrics:
- Accuracy: (TP + TN) / (TP + TN + FP + FN) = (35 + 52) / (35 + 52 + 8 + 5) ≈ 0.87 (or 87%)
- Precision: TP / (TP + FP) = 35 / (35 + 8) ≈ 0.81 (or 81%)
- Recall (Sensitivity): TP / (TP + FN) = 35 / (35 + 5) ≈ 0.88 (or 88%)
- Specificity: TN / (TN + FP) = 52 / (52 + 8) ≈ 0.87 (or 87%)
Conclusion:
- These metrics provide insights into the model’s performance.
- For example, the accuracy tells us that the model is correct in its predictions approximately 87% of the time.
- The precision indicates that out of the emails predicted as spam, around 81% are actually spam.
- The recall suggests that the model can identify around 88% of spam emails correctly.
- The specificity demonstrates that the model can identify around 87% of non-spam emails correctly.
- By analyzing the confusion matrix and associated metrics, we can assess the model’s strengths and weaknesses and make informed decisions about its performance and potential areas of improvement.
(5) Terms Explained.
True Positive:
- True positive is nothing but the case where the actual value, as well as the predicted value, are true.
- The patient has been diagnosed with cancer, and the model also predicted that the patient had cancer.

True Negative:
- This is the case where the actual value is false and the predicted value is also false.
- In other words, the patient is not diagnosed with cancer and our model predicted that the patient did not have cancer.
False Negative:
- In false negative, the actual value is true, but the predicted value is false, which means that the patient has cancer, but the model predicted that the patient did not have cancer.

False Positive:
- This is the case where the predicted value is true, but the actual value is false.
- Here, the model predicted that the patient had cancer, but in reality, the patient didn’t have cancer.
- This is also known as Type 1 Error.

(6) Evaluation Metrix.
- Basically, it is an extended version of the confusion matrix. There are measures other than the confusion matrix which can help achieve better understanding and analysis of our model and its performance.
Accuracy
Precision
Recall (TPR, Sensitivity)
Specificity (TNR)
- F1-Score
- FPR (Type I Error)
FNR (Type II Error)