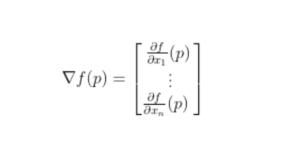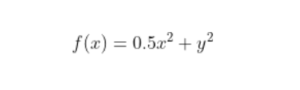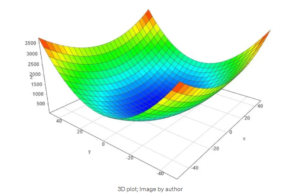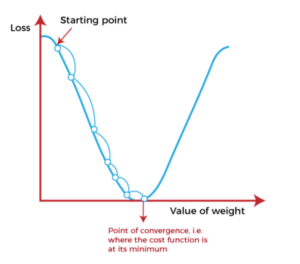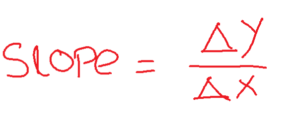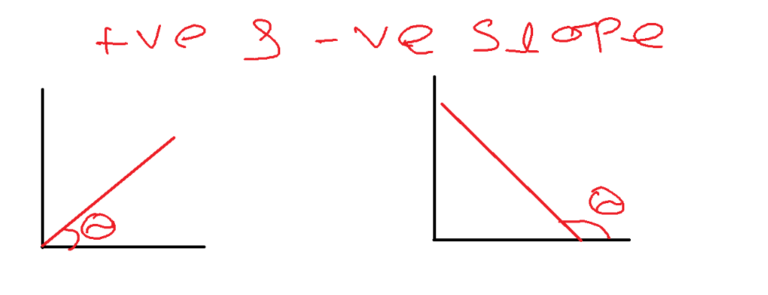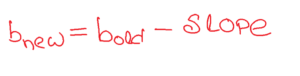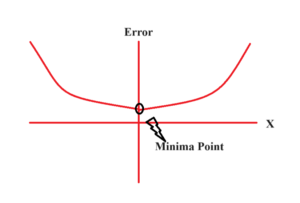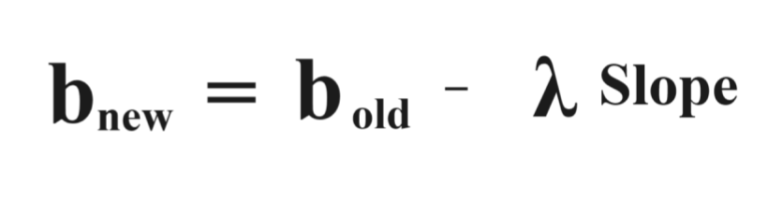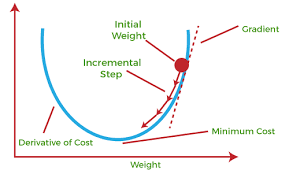
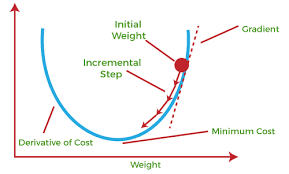


- In simple terms, a function is convex if, for any two points within its domain, the line segment connecting those points lies entirely above or on the graph of the function.
- In simple terms, a convex function refers to a function whose graph is shaped like a cup ∪ (or a straight line like a linear function), while a concave function‘s graph is shaped like a cap ∩.