Random Forest Algorithm
Table Of Contents:
- What Is Random Forest Algorithm?
- Working Principle Of Random Forest Algorithm.
- Essential Features Of Random Forest.
- Important Hyperparameters In Random Forest Algorithm.
- Difference Between Random Forest And Decision Tree.
- Advantages and Disadvantages Of Random Forest Algorithm.
(1) What Is Random Forest Algorithm?
- The Random Forest algorithm is an ensemble learning method that combines multiple decision trees to create a robust and accurate predictive model.
- Random forest is a Supervised Machine Learning Algorithm that is used widely in Classification and Regression problems.
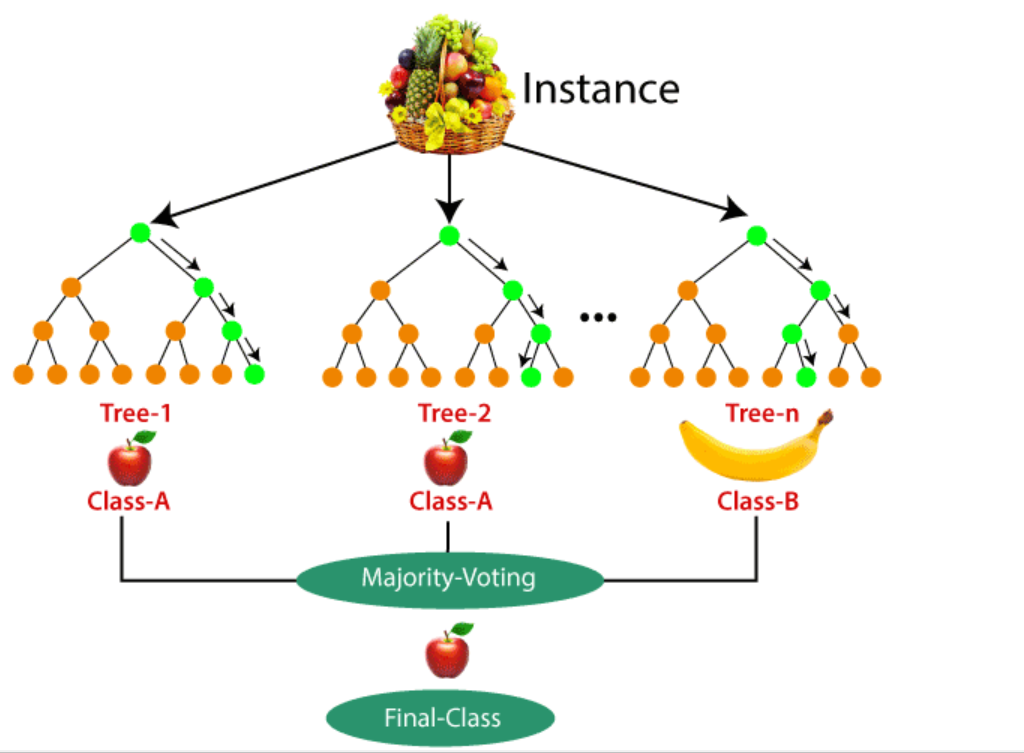
(2) How Random Forest Algorithm Works?
Step-1: Ensemble of Decision Trees:
- Random Forest builds an ensemble of Decision Trees by creating a set of individual trees, each trained on a random subset of the training data.
- Each Decision Tree is constructed independently, using a random selection of features from the dataset.
Step-2: Random Subset Selection:
- Random Forest applies a technique called “bagging” or bootstrap aggregating.
- It randomly selects subsets of the training data with replacement, meaning that some instances may appear multiple times in a subset, while others may be left out.
- This random sampling ensures diversity among the training sets for each decision tree.
Step-3: Random Feature Selection:
- For each decision tree in the forest, a random subset of features is selected at each split point.
- This random feature selection helps to reduce the correlation among the trees and allows each tree to make independent and diverse predictions.
Step-4: Tree Construction:
- Each decision tree in the Random Forest is constructed using a specific algorithm such as ID3, C4.5, or CART.
- The tree is grown by recursively partitioning the data based on the selected features until a stopping criterion is met, such as reaching a maximum depth or minimum number of instances per leaf.
Step-5: Voting and Prediction:
- Once the ensemble of decision trees is built, predictions are made by aggregating the individual tree predictions.
- For classification tasks, the Random Forest uses majority voting, where the class that receives the most votes from the individual trees is selected as the final prediction.
- For regression tasks, the Random Forest takes the average of the individual tree predictions as the final prediction.
(3) Essential Features Of Random Forest Algorithm.
- Diversity: Not all attributes/variables/features are considered while making an individual tree; each tree is different.
- Immune to the curse of dimensionality: Since each tree does not consider all the features, the feature space is reduced.
- Parallelization: Each tree is created independently out of different data and attributes. This means we can fully use the CPU to build random forests.
- Train-Test split: In a random forest, we don’t have to segregate the data for train and test as there will always be 30% of the data which is not seen by the decision tree.
- Stability: Stability arises because the result is based on majority voting/ averaging.
(4)Important Hyperparameters In Random Forest Algorithm.
Hyperparameters to Increase the Predictive Power
n_estimators: Number of trees the algorithm builds before averaging the predictions.
max_features: Maximum number of features random forest considers splitting a node.
mini_sample_leaf: Specifies the minimum number of samples required to be at a leaf node.
min_samples_split: Specify the minimum number of samples required to split an internal node,criterion: How to split the node in each tree? (Entropy/Gini impurity/Log Loss)
max_leaf_nodes: Maximum leaf nodes in each tree
Example:
- For instance, if
min_samples_split = 5, and there are 7 samples at an internal node, then the split is allowed. - But let’s say the split results in two leaves, one with 1 sample, and another with 6 samples.
- If
min_samples_leaf = 2, then the split won’t be allowed (even if the internal node has 7 samples) because one of the leaves will have less than the minimum number of samples required to be at a leaf node.
Hyperparameters to Increase the Speed
n_jobs: it tells the engine how many processors it is allowed to use. If the value is 1, it can use only one processor, but if the value is -1, there is no limit.
random_state: controls randomness of the sample. The model will always produce the same results if it has a definite value of random state and has been given the same hyperparameters and training data.
oob_score: OOB means out of the bag. It is a random forest cross-validation method. In this, one-third of the sample is not used to train the data; instead used to evaluate its performance. These samples are called out-of-bag samples.
(5) Difference Between Random Forest & Decision Tree.
| Decision trees | Random Forest |
| 1. Decision trees normally suffer from the problem of overfitting if it’s allowed to grow without any control. | 1. Random forests are created from subsets of data, and the final output is based on average or majority ranking; hence the problem of overfitting is taken care of. |
| 2. A single decision tree is faster in computation. | 2. It is comparatively slower. |
| 3. When a data set with features is taken as input by a decision tree, it will formulate some rules to make predictions. | 3. Random forest randomly selects observations, builds a decision tree, and takes the average result. It doesn’t use any set of formulas. |
(6) Advantages & Disadvantages Of Random Forest Algorithm.
Advantages:
- The Random Forest algorithm offers several advantages that contribute to its popularity and effectiveness in various machine learning tasks. Here are some key advantages of the Random Forest algorithm:
Robustness Against Overfitting: Random Forest is designed to mitigate overfitting, a common problem in machine learning. By aggregating predictions from multiple decision trees, each trained on different subsets of the data, Random Forest reduces the risk of overfitting and improves generalization performance.
High Accuracy: Random Forest tends to deliver high prediction accuracy across a wide range of tasks. It combines the predictions of multiple decision trees, which helps to reduce bias and variance, leading to more accurate and reliable predictions. Random Forest often outperforms individual decision trees and other machine learning algorithms.
Handling of High-Dimensional Data: Random Forest can effectively handle datasets with a large number of features (high dimensionality). The algorithm performs well even when the number of features is much greater than the number of instances. It automatically selects a random subset of features at each split, allowing it to capture relevant patterns and reduce the impact of irrelevant features.
Robustness to Outliers and Missing Data: Random Forest is relatively robust to outliers and missing data. The algorithm’s ensemble nature and the averaging of multiple tree predictions help to reduce the impact of noisy or missing values. Random Forest can handle varying types of data, including categorical and numerical features, without requiring extensive data preprocessing.
Feature Importance Estimation: Random Forest provides a measure of feature importance, indicating the relevance of each input variable in the prediction task. This information can be valuable for feature selection, identifying key factors driving predictions, and gaining insights into the underlying data relationships.
Parallelizable and Scalable: Random Forest can be easily parallelized, allowing for efficient computation on multicore processors and distributed computing frameworks. Each decision tree in the forest can be constructed independently, making Random Forest suitable for large-scale datasets and efficient utilization of computational resources.
Reduced Bias: Random Forest is less prone to bias compared to individual decision trees. By averaging the predictions of multiple trees, it reduces the risk of capturing idiosyncrasies or biases present in a single decision tree.
Dis-Advantages:
- While the Random Forest algorithm offers several advantages, it also has some limitations and potential drawbacks. Here are some disadvantages of the Random Forest algorithm:
Lack of Interpretability: Random Forests are considered to be “black box” models, meaning they are challenging to interpret compared to simpler models like decision trees. The ensemble nature of Random Forests makes it difficult to understand the specific relationships between features and predictions. While feature importance can be estimated, interpreting the entire model’s decision-making process can be complex.
Memory and Computational Requirements: Random Forests can be memory-intensive and computationally expensive, especially when dealing with a large number of trees and high-dimensional datasets. The need to train multiple decision trees and store them in memory can be resource-consuming, limiting the scalability of the algorithm.
Longer Training Time: Training a Random Forest model can take longer compared to simpler algorithms, such as logistic regression or decision trees. Constructing multiple decision trees and evaluating feature subsets for each tree adds computational overhead, which can be a disadvantage when dealing with large datasets or limited computing resources.
Biased Class Distribution: Random Forests may not perform well on imbalanced datasets where the class distribution is skewed. The majority class tends to dominate the decision-making process, potentially leading to biased predictions and reduced performance on minority classes. Additional techniques, such as class weighting or resampling methods, may be needed to address this issue.
Difficulty Handling Noisy Data: While Random Forests are generally robust to outliers and missing data, they may struggle with noisy or mislabeled instances. Noisy data can introduce instability in the decision tree construction process, impacting the overall performance of the Random Forest.
Non-Deterministic Feature Importance: The feature importance estimates provided by Random Forests are based on the average contribution of each feature across the ensemble of trees. However, these estimates can vary, and different runs of the algorithm may result in slightly different rankings of feature importance. Therefore, the feature importance measures from Random Forests should be interpreted with caution.
Limited Extrapolation Capability: Random Forests are known to be effective in interpolation tasks, meaning they can accurately predict within the range of observed data. However, they may not perform as well in extrapolation tasks, where predictions are made outside the range of training data. Random Forests may struggle to capture patterns or make reliable predictions beyond the observed data range.