
Regularization In Machine Learning
Table Of Contents:
- What Is Regularization?
- Types Of Regularization Techniques.
- L1 Regularization (Lasso Regularization).
- L2 Regularization (Ridge Regularization).
- Elastic Net Regularization.
(1) What Is Regularization?
- Regularization in machine learning is a technique used to prevent overfitting and improve the generalization performance of a model.
- Overfitting occurs when a model learns to fit the training data too closely, capturing noise or irrelevant patterns that do not generalize well to new, unseen data.
- Regularization introduces additional constraints or penalties to the learning process to prevent the model from becoming too complex or sensitive to the training data.

(2) Types Of Regularization Technique.
- There are two common types of regularization techniques:
- L1 Regularization (Lasso Regularization).
- L2 Regularization (Ridge Regularization).
- Elastic Net Regularization.
(3) L1 Regularization
- LASSO(Least Absolute Shrinkage and Selection Operator).
- In L1 regularization, the model’s cost function is augmented with the sum of the absolute values of the model’s coefficients, multiplied by a regularization parameter (lambda).
- This encourages the model to shrink less important features’ coefficients to zero, effectively performing feature selection and promoting sparsity in the model.
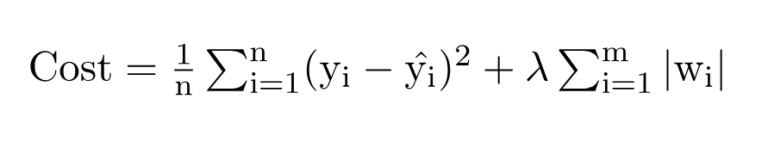
where,
- m – Number of Features
- n – Number of Examples
- w – Coefficients of Variables
- y_i – Actual Target Value
- y_i(hat) – Predicted Target Value
Limitations Of L1 Regularization:
Feature Selection Bias: L1 regularization tends to favour sparse solutions by driving some feature coefficients to exactly zero. While this can be advantageous for feature selection and model interpretability, it may also lead to a bias in feature selection. L1 regularization tends to favor one feature over another when they are highly correlated, leading to instability or arbitrary feature selection.
Lack of Stability: L1 regularization can be sensitive to small changes in the input data. This sensitivity can cause instability in feature selection, resulting in different subsets of features being selected for slightly different training sets. As a result, the model’s performance may vary significantly depending on the specific training data.
Limited Shrinkage: L1 regularization does not effectively shrink the coefficients of correlated features together. Each feature is penalized independently, leading to a lack of shrinkage for groups of correlated features. This can be problematic when dealing with datasets where many features are highly correlated, as L1 regularization may not effectively handle their collective impact.
Inconsistent Solutions: When multiple features are highly correlated, L1 regularization may produce inconsistent solutions. Small changes in the data or the optimization process can lead to different subsets of features being selected, resulting in different models and predictions.
Sensitivity to Scaling: L1 regularization is sensitive to the scale of features. Features with larger magnitudes can have a larger impact on the regularization term, potentially dominating the model’s coefficients. It is often necessary to standardize or normalize the features before applying L1 regularization to ensure fair treatment of all features.
Conclusion:
- Despite these limitations, L1 regularization remains a valuable technique for feature selection, sparsity, and interpretability.
- However, it is important to be aware of these limitations and consider alternative regularization methods, such as L2 regularization or Elastic Net, when dealing with highly correlated features or when stability and consistent solutions are critical.
(4) L2 Regularization
- In L2 regularization, the model’s cost function is augmented with the sum of the squared values of the model’s coefficients, multiplied by a regularization parameter (lambda).
- This encourages the model to distribute the impact of feature weights more evenly and reduces the impact of individual features, preventing them from dominating the model’s predictions.
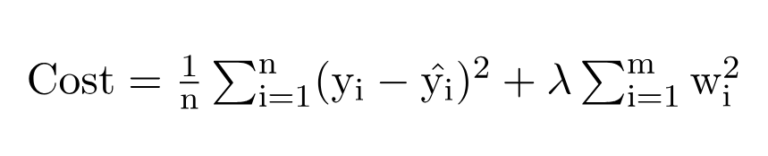
where,
- m – Number of Features
- n – Number of Examples
- w – Coefficients of Variables
- y_i – Actual Target Value
- y_i(hat) – Predicted Target Value
Limitations Of L2 Regularization:
- Inability to Perform Feature Selection: Unlike L1 regularization, L2 regularization does not drive coefficients exactly to zero. It only shrinks the coefficients towards zero without eliminating any features entirely. Consequently, L2 regularization does not inherently perform feature selection, which means all features contribute to the model, albeit with reduced magnitudes.
- Limited Ability to Handle Irrelevant Features: L2 regularization can reduce the impact of irrelevant features by shrinking their coefficients, but it does not completely eliminate their influence. In cases where there are a large number of irrelevant features, L2 regularization may not be as effective as L1 regularization in removing them from the model.
Sensitivity to Feature Scale: L2 regularization assumes that all features are on a similar scale. If the features have significantly different scales, features with larger magnitudes can dominate the regularization term and have a disproportionate impact on the model’s coefficients. It is generally recommended to normalize or standardize the features before applying L2 regularization to ensure fair regularization across all features.
Limited Ability to Handle Correlated Features: L2 regularization does not explicitly handle the issue of correlated features. Unlike L1 regularization, which tends to select one feature from a group of highly correlated features, L2 regularization does not differentiate between them and assigns similar weights to all of them. This can result in unstable and inconsistent solutions when dealing with highly correlated features.
Bias Towards Small Coefficients: L2 regularization tends to shrink all coefficients towards zero, but it does not encourage sparsity or favour solutions with a small number of non-zero coefficients. This can be a limitation when dealing with high-dimensional datasets, as L2 regularization does not inherently provide a sparse solution.
Conclusion:
- It’s important to consider these limitations when deciding whether to use L2 regularization in a particular machine-learning task.
- Depending on the specific requirements of the problem, alternative regularization techniques, such as L1 regularization or Elastic Net, may be more suitable.
(5) Elastic Net Regularization
- Elastic Net regularization is a technique in machine learning that combines both L1 (Lasso) and L2 (Ridge) regularization methods. It is used to handle situations where there are many correlated features in a dataset and helps address some limitations of using only L1 or L2 regularization individually.
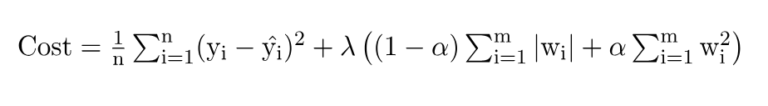
where,
- m – Number of Features
- n – Number of Examples
- w – Coefficients of Variables
- y_i – Actual Target Value
- y_i(hat) – Predicted Target Value
The Elastic Net regularization adds a penalty term to the model’s cost function that combines both the L1 and L2 regularization terms. The cost function is augmented with two hyperparameters: alpha and lambda.
The term alpha controls the balance between the L1 and L2 regularization. A value of 1 represents pure L1 regularization, while a value of 0 represents pure L2 regularization. Intermediate values between 0 and 1 allow for a combination of L1 and L2 regularization.
- The term lambda, similar to the regularization parameter in L1 and L2 regularization, controls the overall strength of regularization. A higher lambda value increases the amount of shrinkage applied to the model’s coefficients.
Advantages Of Elastic Net Regularization
Feature Selection: Like L1 regularization, Elastic Net can perform feature selection by driving some feature coefficients to zero. This is useful when dealing with high-dimensional datasets with many correlated features.
Handling Correlated Features: Elastic Net addresses the issue of correlated features that can cause instability in L1 regularization. The L2 regularization component helps to group correlated features together, preventing them from being excessively penalized.
Flexibility: By adjusting the alpha hyperparameter, Elastic Net allows for a flexible balance between the benefits of L1 and L2 regularization. It can capture both sparse and dense feature representations.
Conclusion:
- Elastic Net regularization is commonly used in regression problems, such as linear regression or logistic regression, where the goal is to find a suitable set of coefficients for the model. It offers a versatile regularization approach that combines the strengths of L1 and L2 regularization, providing a balance between feature selection and handling correlated features.