Transformers Neural Networks
Table Of Contents:
- What Is Transformer?
- Key Features Of Transformer?
- Applications Of Transformer?
- Key Features Of Transformer?
- How Do Transformers Handle The Issue Of Vanishing Gradients In Long-Term Dependencies?
(1) What Is Transformer?
- Transformers are a type of deep learning model architecture that have gained significant attention and popularity, particularly in natural language processing (NLP) tasks.
- Unlike traditional recurrent neural networks (RNNs), transformers rely on a self-attention mechanism to capture dependencies between different elements of the input sequence.
(2) Key Features Of Transformer?
Self-Attention Mechanism: The self-attention mechanism is the core component of transformers. It allows the model to weigh the importance of different elements in the input sequence when making predictions. By attending to relevant elements, transformers can capture both local and global dependencies, making them effective at modeling long-range dependencies.
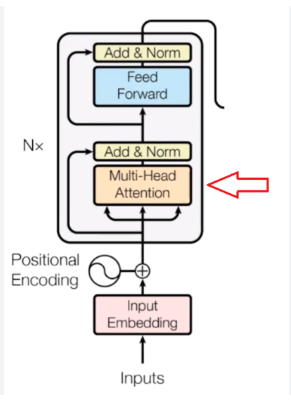
Encoder-Decoder Architecture: Transformers often follow an encoder-decoder architecture. The encoder processes the input sequence, while the decoder generates the output sequence. Each component consists of multiple layers of self-attention and feed-forward neural networks.
Positional Encoding: Since transformers do not have a recurrent structure that inherently captures sequential information, positional encoding is introduced to inform the model about the position or order of the elements in the input sequence. Positional encoding is typically added to the input embeddings and provides a way to represent the sequential nature of the data.
Multi-Head Attention: Transformers employ multi-head attention, where multiple attention heads are used to capture different dependencies in the input sequence. Each attention head learns to focus on different parts of the input, allowing the model to capture diverse information and improve its representational capacity.
Feed-Forward Neural Networks: Transformers contain feed-forward neural networks within each attention layer. These networks process the attended representations and apply non-linear transformations to capture complex patterns and relationships in the data.
Pretraining and Fine-Tuning: Transformers often benefit from pretraining on large-scale unsupervised tasks, such as language modeling or masked language modeling. This pretraining phase allows the model to learn general representations of the data. After pretraining, the model can be fine-tuned on specific downstream tasks, such as machine translation, text classification, or question-answering.
Applications in NLP: Transformers have achieved state-of-the-art performance in various NLP tasks, including machine translation (e.g., Google’s Transformer), language modeling (e.g., OpenAI’s GPT), question-answering (e.g., BERT), and text classification (e.g., XLNet). Their ability to capture long-range dependencies and process input sequences in parallel has contributed to their success in these tasks.
(3) Applications Of Transformer?
Transformers have also found applications in other domains beyond NLP, such as computer vision and speech processing. Vision Transformer (ViT) is an example of a transformer-based architecture applied to image classification tasks.
Overall, transformers have revolutionized the field of deep learning, particularly in NLP, by providing an effective and parallelizable architecture for modeling sequential data. They have achieved remarkable results on a wide range of tasks and continue to be an active area of research and development.
(4) Key Features Of Transformer?
Attention Mechanism: The attention mechanism is a fundamental component of transformers. It allows the model to assign different weights or attention scores to different elements in the input sequence based on their relevance to each other. The attention mechanism enables the model to focus on important elements and capture complex relationships, which is crucial for tasks like machine translation or understanding long-range dependencies.
Masked Language Modeling: Masked Language Modeling (MLM) is a technique used in pretraining transformers. In MLM, a certain percentage of the input tokens are randomly masked, and the model is trained to predict the original values of these masked tokens. This forces the model to learn contextual representations that can capture the meaning of the masked tokens based on the surrounding context. BERT (Bidirectional Encoder Representations from Transformers) is an example of a transformer model that uses MLM during pretraining.
Transfer Learning and Fine-Tuning: Transformers have enabled effective transfer learning in NLP. Pretrained transformer models can be used as a starting point for various downstream tasks. By leveraging the knowledge learned during pretraining, fine-tuning can be performed on task-specific data to adapt the model to the specific task. This approach has significantly improved the efficiency and performance of NLP models.
Long-Range Dependencies: Transformers excel at capturing long-range dependencies in sequential data. Unlike RNNs, which have difficulty modeling long-term dependencies due to the vanishing gradient problem, transformers can directly attend to any position in the input sequence. This capability makes them well-suited for tasks requiring understanding of global context, such as document classification or document summarization.
Parallel Processing: Transformers are highly parallelizable, making them computationally efficient for training and inference. Unlike sequential processing in RNNs, transformers can process all elements of the input sequence in parallel, which is advantageous for tasks involving long sequences or large datasets.
Multi-modal Applications: Transformers are not limited to text-based tasks. They have been successfully applied to multi-modal tasks that involve multiple input modalities, such as images and text or audio and text. By encoding both textual and visual information using transformers, models can learn rich representations that capture the interactions between different modalities.
Architectural Variants: Since the introduction of transformers, several architectural variants have been proposed to improve their performance or address specific challenges. Examples include the Transformer-XL, which focuses on modeling longer-term dependencies, and the Reformer, which introduces techniques to handle long sequences more efficiently.
Open-Source Implementations: Due to their popularity, transformers have numerous open-source implementations and pre-trained models available, making it easier for researchers and practitioners to use and build upon this architecture. Libraries such as Hugging Face’s Transformers and Google’s TensorFlow Transformers provide extensive resources and pre-trained models for various transformer-based architectures.
(5) How Do Transformers Handle The Issue Of Vanishing Gradients In Long-Term Dependencies?
- Transformers address the issue of vanishing gradients in long-term dependencies through the use of self-attention mechanisms and skip connections. Although transformers are not inherently immune to vanishing gradients, their architectural design helps alleviate the problem in comparison to traditional recurrent neural networks (RNNs).
- Here’s how transformers handle the vanishing gradients problem:
Self-Attention Mechanism: The self-attention mechanism in transformers allows each position in the input sequence to attend to all other positions, capturing the relationships between them. This attention mechanism enables the model to directly propagate information from any position to any other position, regardless of the distance between them. As a result, transformers can capture long-range dependencies more effectively.
Skip Connections: Transformers employ skip connections, also known as residual connections, to mitigate the issue of vanishing gradients. Skip connections directly connect the input or intermediate representations to subsequent layers, bypassing the transformation layers. By adding these skip connections, the gradient signals can flow more easily during backpropagation, preventing them from vanishing or diminishing significantly.
Layer Normalization: Transformers typically use layer normalization after each sublayer, which helps stabilize the gradients during training. Layer normalization normalizes the inputs across the feature dimension, reducing the impact of input variations on the gradients. This normalization technique helps in mitigating the vanishing gradients problem.
Initialization and Regularization: Proper initialization and regularization techniques are crucial for training transformers effectively. Initialization methods like Xavier or He initialization can help ensure proper signal propagation during training, preventing gradients from vanishing or exploding. Regularization techniques such as dropout or weight decay can also be applied to prevent overfitting and stabilize the training process.
While transformers provide improvements in handling vanishing gradients compared to RNNs, they are not completely immune to the issue. Very deep transformer architectures or extremely long sequences can still pose challenges, and in some cases, gradient clipping may be necessary to further stabilize the training process.
It’s worth noting that the introduction of transformers has not only addressed the vanishing gradients problem but also brought about other benefits such as improved parallelization, better handling of long-range dependencies, and enhanced modeling capabilities for various tasks, particularly in natural language processing.