
Activation Functions
Table Of Contents:
- What Is An Activation Function?
- Why To Use Activation Function?
- Why Should An Activation Function Be Differentiable?
- Types Of Activation Functions.
- Sigmoid(Logistic) Activation Function.
- Hyperbolic Tangent (tanh) Activation.
- Rectified Linear Unit (ReLU) Activation.
- Leaky ReLU Activation.
- Softmax Activation.
(1) What Is An Activation Function?
- An activation function is a mathematical function that determines the output of a neuron or a layer of neurons in a neural network.
- It introduces non-linearity into the network, allowing it to model complex relationships and make non-linear transformations of the input data.

(2) Why To Use Activation Function?
- Activation functions are used in neural networks for several important reasons:
Introducing Non-Linearity: Activation functions introduce non-linearity into the network, allowing it to model complex relationships and make non-linear transformations of the input data. Without activation functions, a neural network would be limited to representing only linear functions, greatly reducing its expressive power.
Capturing Complex Patterns: Many real-world problems are inherently non-linear, and activation functions enable neural networks to capture and learn complex patterns in the data. By applying non-linear transformations to the inputs, neural networks can discover and represent intricate relationships that would be difficult or impossible to capture with linear models.
Enhancing Network Expressiveness: Activation functions increase the expressive power of neural networks by enabling the composition of multiple layers and the formation of hierarchical representations. Each layer applies its activation function to build increasingly complex features and representations based on the previous layer’s outputs.
Decision Making and Classification: Activation functions help in making decisions and performing classification tasks. Depending on the problem, the output of a neural network may need to be interpreted as class probabilities or binary decisions. Activation functions such as softmax and sigmoid facilitate these interpretations by mapping network outputs to the desired output range (e.g., probabilities between 0 and 1).
Learning Complex Functions: Activation functions play a crucial role during the learning process. By introducing non-linearities, they help gradients flow through the network during backpropagation, allowing the network to adjust its weights and learn complex functions. Activation functions with well-behaved derivatives facilitate more stable and efficient training.
Neural Network Stability: Activation functions impact the stability and convergence of neural networks during training. Well-designed activation functions can mitigate issues like vanishing gradients, where the gradients become extremely small, hindering learning in deep networks. Activation functions like ReLU and its variants help alleviate these problems by maintaining non-zero gradients for positive inputs.
- In summary, activation functions are essential components of neural networks as they introduce non-linearity, capture complex patterns, enhance network expressiveness, facilitate decision-making and classification, enable learning of complex functions, and contribute to network stability during training.
- Choosing appropriate activation functions is crucial to ensure the network’s capacity to model and solve specific tasks effectively.
(3) Why Should An Activation Function Be Differentiable?
- The most important feature that the activation function should have is to be differentiable. Artificial neural networks learn using an algorithm called backpropagation.
- This algorithm essentially uses the model’s incorrect predictions to adjust the network in a way that will make it less incorrect, thereby improving the network’s predictive capabilities. This is done through differentiation.
- Therefore, in order for a network to be trainable, all its elements need to be differentiable, including the activation function.
- However, it doesn’t mean that the neural network will do its best during the training. There are more barriers that need to be passed to reach the goal.
- The differentiability creates other problems, especially in deep learning, such are “vanishing” and “exploding” gradients.

- In the “vanishing” gradient case from one hidden layer to another, the values of the gradient can be smaller and smaller that eventually become zero.
- The “exploding” gradient is the other side of the problem where from one hidden layer to another the values become bigger and bigger and reach infinity.
(3) Types Of Activation Function.
- The choice of activation function depends on the specific task and the properties desired in the network’s outputs.
- Here are some key functions and their characteristics:
Sigmoid (Logistic) Activation:
Formula:

Diagram:

Description:
- Maps the input to a value between 0 and 1.
- S-shaped curve.
- Used in the output layer of binary classification problems, where the output represents the probability of belonging to a class.
Where To Use Sigmoid Activation ?
Binary Classification: Sigmoid activations are often used in the output layer of neural networks for binary classification problems. The output of the sigmoid function can be interpreted as the probability of belonging to the positive class. By setting a threshold (e.g., 0.5), the network can make a binary decision based on the output value.
Multi-label Classification: Sigmoid activations can also be used in multi-label classification tasks where each input can belong to multiple classes simultaneously. In this case, each output neuron corresponds to a class, and the sigmoid function maps the output to a probability between 0 and 1 for each class independently.
Logistic Regression: Sigmoid activations are a natural choice for logistic regression models, where the goal is to estimate the probability of a binary outcome. In logistic regression, the sigmoid function is typically used as the link function to map the linear regression output to a probability.
Probability Estimation: Sigmoid activations can be used to estimate probabilities or probabilities-like values in various contexts. For example, in recommender systems, sigmoid activations can be used to model the likelihood of a user liking an item based on their preferences and item features.
Transfer Learning: Sigmoid activations can be useful in transfer learning scenarios, where a pre-trained model with sigmoid activations in the output layer is used as a feature extractor. The sigmoid activations provide a convenient probability representation for the pre-trained model’s outputs, which can then be used as input to another model for transfer learning tasks.
Hyperbolic Tangent (tanh) Activation:
Formula:

Diagram:

Description:
- Maps the input to a value between -1 and 1.
- Similar to the sigmoid function but centred around zero.
- Commonly used in hidden layers of neural networks.
Where To Use Hyperbolic Tangent (tanh) Activation:
Hidden Layers of Neural Networks: The tanh activation function is often used in hidden layers of neural networks. It provides stronger non-linearity compared to sigmoid activations, allowing the network to capture and model more complex relationships in the data. The symmetric nature of the tanh function, with its output range between -1 and 1, helps in balancing the network’s representations and avoiding biases towards positive or negative values.
Recurrent Neural Networks (RNNs): Tanh activations are commonly used in the hidden states of recurrent neural networks. RNNs are effective in modeling sequential and temporal data, and the tanh activation helps capture and propagate contextual information over time. The symmetric nature of tanh aids in preserving the sign of the information flow through the recurrent connections.
Gradient Flow and Training Stability: The tanh activation function has steeper gradients compared to the sigmoid function, especially around the origin. This property can accelerate convergence during training, allowing the network to learn more quickly. The stronger gradients can help mitigate the vanishing gradient problem when training deep neural networks, making the tanh activation a suitable choice in such scenarios.
Image Processing: In certain image processing tasks, the tanh activation can be applied to the output layer of a neural network to normalize and scale pixel values between -1 and 1. This can help in tasks such as image denoising or image generation, where the network needs to produce pixel values that fall within a specific range.
GANs (Generative Adversarial Networks): Tanh activations are commonly used in the output layer of the generator network in GANs. GANs are used for generating realistic synthetic data, such as images or text. The tanh activation helps map the generator’s output to a range that is suitable for the desired data type, such as pixel intensities in the range of 0 to 255 for images.
Sigmoid Vs. Tanh Activation

- Sigmoid Activation: The sigmoid function maps the input to a value between 0 and 1. The output of sigmoid is always positive, and the midpoint is at 0.5. This makes sigmoid suitable for binary classification tasks or problems where the output represents a probability.
- Tanh Activation: The tanh function maps the input to a value between -1 and 1. The output of tanh is symmetric around zero, with the midpoint at 0. Tanh activations are often used in hidden layers of neural networks.
Problem With Sigmoid & Tanh Activation:
- A general problem with both the sigmoid and tanh functions is that they saturate. This means that large values snap to 1.0 and small values snap to -1 or 0 for tanh and sigmoid respectively.
- Further, the functions are only really sensitive to changes around their mid-point of their input, such as 0.5 for sigmoid and 0.0 for tanh.
- The limited sensitivity and saturation of the function happen regardless of whether the summed activation from the node provided as input contains useful information or not.
- Once saturated, it becomes challenging for the learning algorithm to continue to adapt the weights to improve the performance of the model.
Finally, as the capability of hardware increased through GPUs’ very deep neural networks using sigmoid and tanh activation functions could not easily be trained.
Layers deep in large networks using these nonlinear activation functions fail to receive useful gradient information. Error is back propagated through the network and used to update the weights.
The amount of error decreases dramatically with each additional layer through which it is propagated, given the derivative of the chosen activation function.
This is called the vanishing gradient problem and prevents deep (multi-layered) networks from learning effectively.
Although the use of nonlinear activation functions allows neural networks to learn complex mapping functions, they effectively prevent the learning algorithm from working with deep networks.
Workarounds were found in the late 2000s and early 2010s using alternate network types such as Boltzmann machines and layer-wise training or unsupervised pre-training.
Rectified Linear Unit (ReLU) Activation:
Formula:
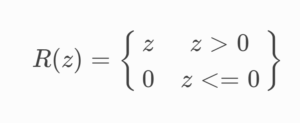
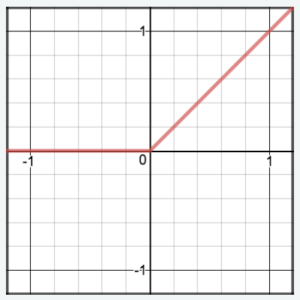
Diagram:
Description:
- Returns the input if it is positive; otherwise, outputs zero.
- Simple and computationally efficient.
- Popular in deep neural networks due to its ability to alleviate the vanishing gradient problem.
Where To Use Rectified Linear Unit (ReLU) Activation ?
- The Rectified Linear Unit (ReLU) activation function is widely used in neural networks, particularly in deep learning, due to its beneficial properties.
- Here are some scenarios where ReLU activation is commonly used:
Hidden Layers of Deep Neural Networks: ReLU activations are often employed in the hidden layers of deep neural networks. ReLU provides a simple and computationally efficient non-linearity by setting negative inputs to zero and leaving positive inputs unchanged. This sparsity-inducing property allows networks to learn sparse representations and promotes efficient computation during both forward and backward passes.
Addressing Vanishing Gradients: ReLU activations help mitigate the vanishing gradient problem, which can occur during backpropagation in deep networks. Since ReLU does not saturate for positive inputs, it allows gradients to flow more easily through the network, facilitating efficient training and convergence. By preventing the vanishing gradient problem, ReLU activations enable the training of deeper architectures.
Image and Computer Vision Tasks: ReLU activations have shown excellent performance in image and computer vision tasks. Convolutional neural networks (CNNs) leverage ReLU activations after convolutional and pooling layers to introduce non-linearity and learn complex hierarchical representations of images. The sparsity-inducing nature of ReLU helps in capturing edges and other image features effectively.
Natural Language Processing (NLP): ReLU activations are also employed in certain NLP tasks, such as text classification or sentiment analysis. In neural network architectures like recurrent neural networks (RNNs) or long short-term memory (LSTM) networks, ReLU activations can be used in the hidden layers to introduce non-linearity and model complex linguistic relationships.
Fast Training: ReLU activations allow for faster training compared to other activation functions, such as sigmoid or tanh, due to their computational efficiency and non-saturating nature. The absence of exponential functions in ReLU computations speeds up forward and backward passes, making it an attractive choice for large-scale deep learning models.
Advantages Of Rectified Linear Unit (ReLU) Activation .
- Sparsity: Sparsity arises when a ≤ 0. Sigmoids on the other hand are always likely to generate some non-zero value resulting in dense representations. The more such units that exist in a layer the sparser the resulting representation. Sparse representations seem to be more beneficial than dense representations.
- ReLU has the ability to produce sparse outputs, meaning that most of the activations are 0. This is useful because it reduces the number of parameters in the model, and therefore reduces overfitting.
- Avoiding the Vanishing Gradient Problem: ReLU can help to avoid the vanishing gradient problem, which is a common issue in deep neural networks. The vanishing gradient problem occurs when the gradients of the weights become too small during the backward propagation step, making it difficult for the optimizer to update the weights.
- The constant gradient of ReLUs (when the input is positive) allows for faster learning compared to sigmoid activation functions where the gradient becomes increasingly small as the absolute value of x increases. This results in more efficient training of deep neural networks and has been one of the key factors in the recent advances in deep learning.
- Non-linearity: Non-linear activation functions are necessary to learn complex, non-linear relationships between inputs and outputs.
- Computational Efficiency: ReLU is computationally efficient and requires only a threshold operation, which is much faster than other activation functions like sigmoid or hyperbolic tangent.
- Speed of Convergence: ReLU speeds up the convergence of neural networks, compared to other activation functions. This is because the gradient of ReLU is either 0 or 1, which makes it easier for the optimizer to make rapid updates.
Drawbacks Of Rectified Linear Unit (ReLU) Activation .
- The ReLU activation function can result in “dead neurons” during training, where the activation value becomes 0 and remains 0 for all future inputs. This means that the corresponding weights will never be updated, effectively rendering the neuron useless.
- Unbounded Outputs: ReLU has unbounded outputs, meaning that the activation can become very large, which can cause numeric instability and make the network difficult to train.
- Non-Differentiability: ReLU is not differentiable at 0, which means that the gradient of the function is undefined at this point. This can make optimization difficult and slow down convergence. Also, we talked about it in the previous section.
- Unsuitability for Certain Data Distributions: ReLU may not be suitable for data that has a large number of negative values, as it can produce a large number of “dead neurons.” In this case, alternative activation functions may use for it.
One response to “Activation Functions.”
Great goods from you, man. I have understand your stuff previous to and you are just too fantastic.
I actually like what you’ve acquired here, really like
what you are saying and the way in which you say it. You make it entertaining and you still care for
to keep it smart. I can not wait to read much more from you.
This is actually a terrific site.