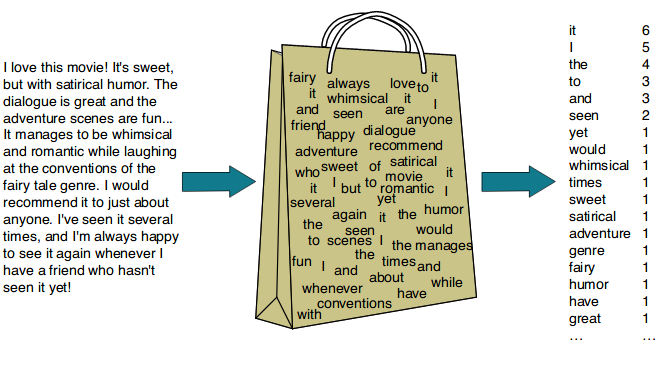
Bag Of Words
Table Of Contents:
- What Is Bag Of Words?
- Example Of Bag Of Words.
- Core Intuition Behind Bag Of Words?
- How Bag Of Words Capture the Semantic Meaning?
- Python Program.
(1) What Is Bag Of Words?
- Bag of Words (BoW) is a simple but widely used feature extraction technique in natural language processing (NLP).
- It is a way of representing text data as a numeric feature vector, where each feature corresponds to a unique word in the text corpus.
Steps:
Vocabulary Creation: The first step is to create a vocabulary of all the unique words or tokens present in the text data. This vocabulary serves as the set of features that will be used to represent the text.
Encoding: For each document or piece of text, a numeric feature vector is created. The length of the vector is equal to the size of the vocabulary. Each element in the vector corresponds to a word in the vocabulary and represents the frequency or occurrence count of that word in the document.
(2) Example Of Bag Of Words.
- Consider the below dataset.
- We will use ‘Bag Of Words’ technique to convert the sentences into vector.
Input Document:

Vocabulary Creation:
- Vocabulary is the unique collection of words in the corpus.
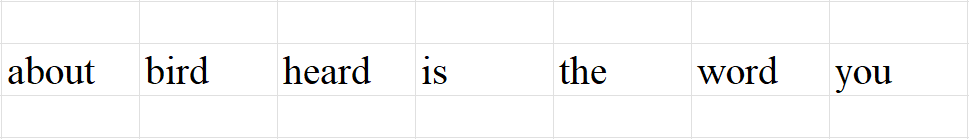
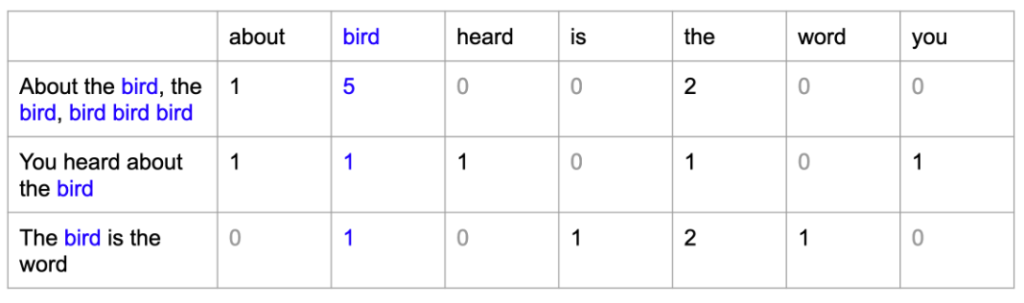
- Here we have arranged the words in alphabetic order.
Frequency Count:
- Take the vocabulary words and check in the sentences how many times it is present in that sentence.
- Write the count below the word.
- Likewise, you will encode each sentence.
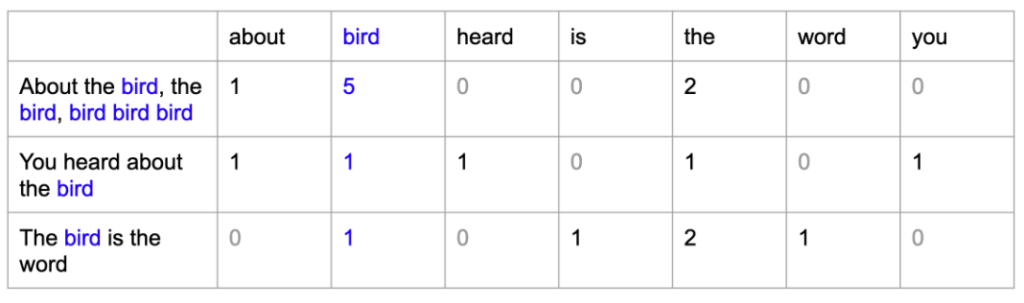
- For the first sentence, “about” is present 1 time, ‘bird’ is present 5 times., ‘heard’ is present 0 times etc.
(3) Core Intuition Behind Bag Of Words?
- Bag Of Words depends on the count of words in a sentence.
- Two sentences are said to be similar if most of the words present in both sentences are similar.
- In this technique order of the word does not matter only matters whether the word is present or not and how many times the word is present.
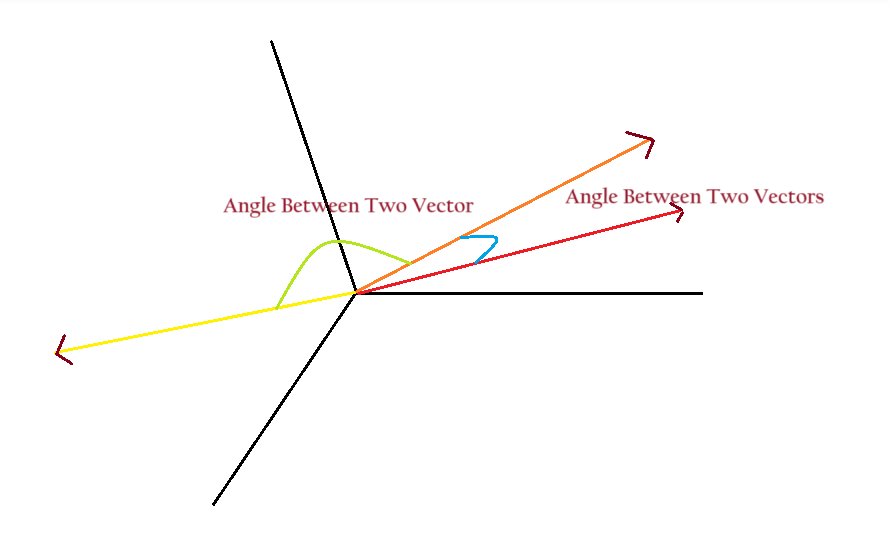
(4) How Bag Of Words Captures The Semantic Meaning?
- We will convert each sentence into a V-dimensional vector.
- Here V = Unique Vocabulary Count.
- Plot all the vectors into V – Dimensional space
- If two vectors are said to be similar, the angle between them will be less.
- If two vectors are dissimilar then the angle between them will be more.
(5) Python Program
import pandas as pd
import numpy as npdf = pd.DataFrame({'text':['about the bird, the bird, bird, bird, bird',
'you heared about the bird',
'the bird is the word'],
'output':[1,1,0]})
df
Fitting The Count Vectorizer:
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
bag_of_words = cv.fit_transform(df['text'])
bag_of_words
Printing The Vocabulary Items:
print(cv.vocabulary_)
Sorting The Vocabulary Items:
sorted_dict = sorted(cv.vocabulary_.items(), key=lambda x: x[1])
sorted_dict
Printing Vector Form Of The Sentences:
print(bag_of_words[0].toarray())
print(bag_of_words[1].toarray())
print(bag_of_words[2].toarray())
cv.transform(['I watched the bird and it is beautiful and i liked it.']).toarray()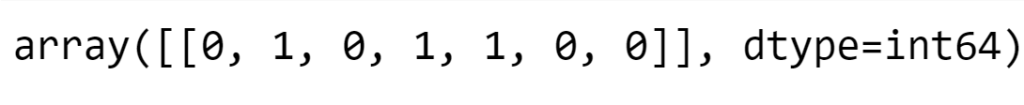
Note:
- cv.transform() method is used to transform the given text into vector format.
- In the above example we can see that as we have trained our CountVectorizer(cv) with 7 unique words, it will vectorize a text of any length to 7 dimensional vector only.
(6) Pros & Cons Of Bag Of Words.
Advantages:
- Simple and Intuitive in nature.
- It solves variable input size problems by only considering the unique vocabulary words. This means whatever input text length comes while prediction it will only count the unique vocabulary words created while training.
- It also handles Out-of-vocabulary problems by considering only unique vocabulary words.
- It somewhat captures the semantic meaning of the sentence if we plot the sentences into vector space the similar sentences will have the smaller angle between them.
Dis-advantages:
- Sparsity Vector issue. In real-world datasets we can get a unique word count say 50000.
- Hence we have to create a vector of size 50000, which is huge in size and causes overfitting.
- If some new words come during prediction, we ignore them as we only consider the unique vocabulary words created while training.
- It ignores the order of the words in the sentence by considering the alphabetical ordering of the vocabulary words.
- Suppose take an example,
- (1) This is a very good movie.
- (2) This is not a very good movie.
- As per the Bag Of Words technique, these two sentences are similar as the words present in both sentences are similar.
- But in reality, both are opposite to each other. In this case our Bag Of Words technique fails.