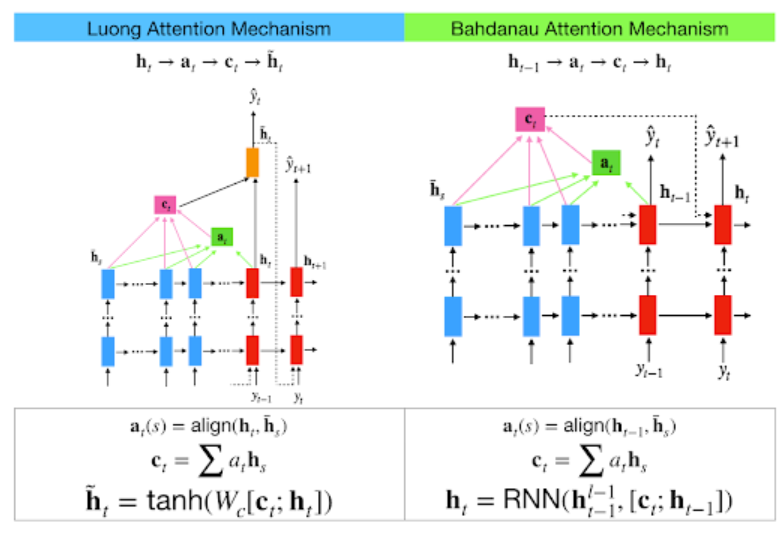
Bahdanau Attention !
Table Of Contents:
- What Is Attention Mechanism?
- What Is Bahdanau’s Attention?
- Architecture Of Bahdanau’s Attention?
(1) What Is Attention Mechanism?
- An attention mechanism is a neural network component used in various deep learning models, particularly in the field of natural language processing (NLP) and sequence-to-sequence tasks.
- It was introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017.

- The attention mechanism allows a model to focus on the most relevant parts of the input when generating an output, rather than treating the entire input sequence equally.
- This is particularly useful when the input and output sequences have different lengths, such as in machine translation or text summarization.
- The key idea behind the attention mechanism is to compute a weighted sum of the input sequence, where the weights are determined by the relevance of each input element to the current output being generated.
- This allows the model to dynamically focus on the most important parts of the input, which can improve the model’s performance and interpretability.
- The attention mechanism typically consists of the following steps:
- Compute a set of attention weights for each input element based on the current output and the input sequence.
- Apply the attention weights to the input sequence to obtain a weighted sum, which is then used as an additional input to the output generation process.
(2) What Is Bahdanau’s Attention?
- Bahdanau’s attention is a specific type of attention mechanism, introduced in the paper “Neural Machine Translation by Jointly Learning to Align and Translate” by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio in 2014.
- Bahdanau’s attention mechanism is designed for encoder-decoder models, where the encoder encodes the input sequence into a fixed-length vector representation, and the decoder generates the output sequence one token at a time.
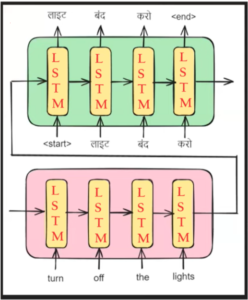
- Let us consider the above Encoder & Decoder architecture.
- Let’s apply the Bahdanau’s Attention mechanism in this model.
Mathematical Notation:
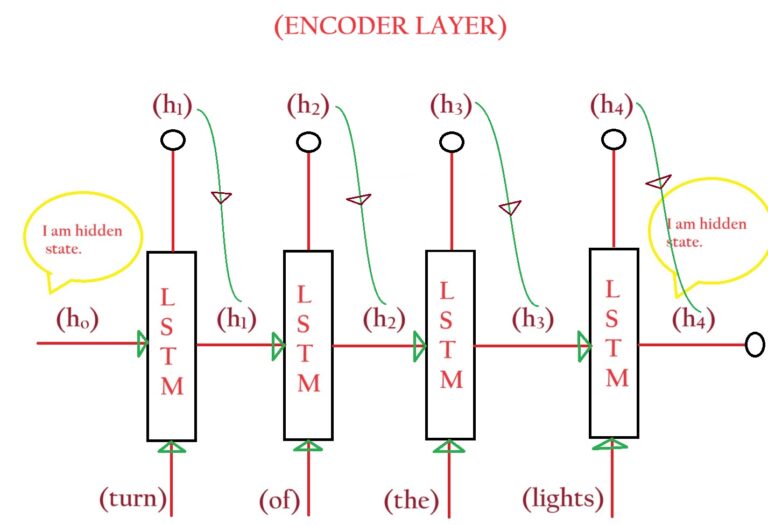
- We denote hidden states of the Encoder layer as (hi).
- In our example, we have four hidden states, [h0, h1, h2, h3, h4].
- All of these are n-dimensional vectors.
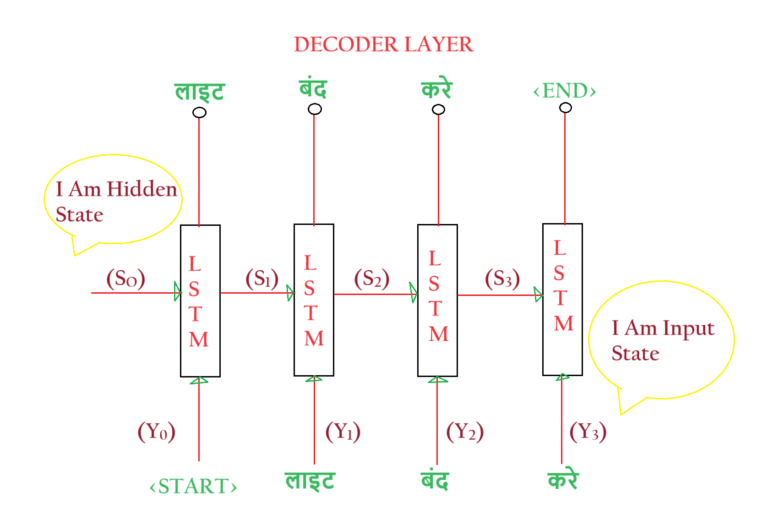
- We denote hidden states of the Decoder layer as (S0).
- The Input State of the decoder layer is denoted as (Y0).
- Our example has four hidden states, [So, S1, S2, S3, S4].
- All of these are n-dimensional vectors.
Implementing Attention Mechanism:
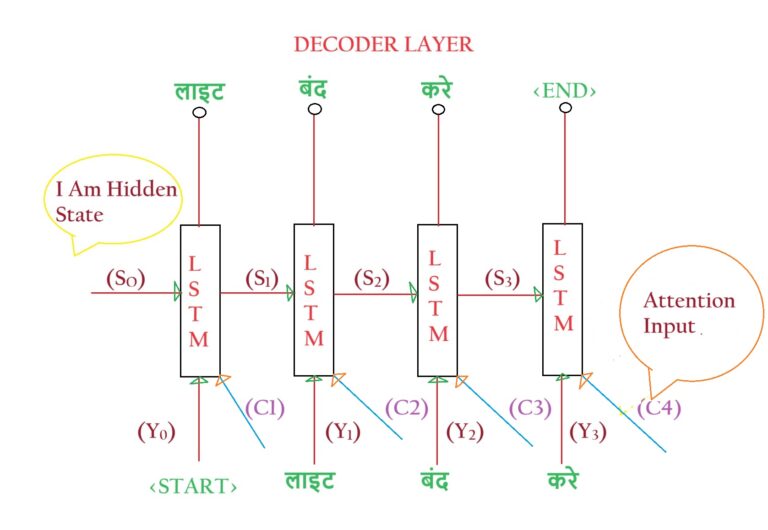
- In every time step of the Decoder layer, we must pass on which time steps of the encoder layer are useful.
- At time step 2, we need [S1, Y1] as an input. Hence at every time step, we need two pieces of information.
- But in the Attention Mechanism, we need to pass one more information, that is, which time step of the Encoder layer is important.
- While printing “लाइटें” we need to tell our Decoder layer to focus on the time step 4 of the Encoder layer.
- The third input which passes to the Decoder layer at every time step is called ‘Attention Input’.
- We denote all the Attention Input as (Ci). In our example, we have 4 Attention Inputs, [C1, C2, C3, C4]
- Hence at every time step of the Encoder layer, we need to give 3 inputs.
- Inputs = [Yi-1, Si-1, Ci]
- Where Yi-1 = Teacher Forcing Input.
- Si-1 = Hidden State Input.
- Ci = Attention Input.
Understanding Attention Input Ci:
What Is Ci ?
- Ci can be a Vector, Scalar or it can be a Matrix. If it is a Vector what is its dimension etc?
- While printing “लाइटें” we know that (h4) of the Encoder layer is important.
- Our task is to find out which Hidden state of the Encoder layer is important for printing “लाइटें”
- After that, we can pass that Hidden state of the Encoder layer as the Attention Input to the Decoder Layer.
- Now we understand that Ci is a vector because we are passing the Hidden State of the Encoder as Ci.
- Now the question is what is the dimension of Ci?
What Is Dimension Of Ci ?
- While printing “लाइटें” we need to tell our Decoder layer to focus on the time step 4 of the Encoder layer.
- While printing “बंद” we need to tell our Decoder layer to focus on the time steps 1 & 2 of the Encoder layer.
- From this, you can see that there is no fixed size of the “Ci” vector.
- At first case Ci = [h4], but in second case Ci = [h1, h2].
- To answer this the Dimension of “Ci” should be the same as the Dimension of the “hi” vector.
- Now the question is what if we need to pass more hi to the Ci vector like in our second case?
- To answer this what we will do is take the weighted sum of all the hidden state inputs of the Encoder layer.
How To Calculate Ci ?
- If you are printing “लाइटें” and you need to know which Hidden state of the Encoder layer is most useful [h0, h1, h2, h3, h4]?
- The Attention Mechanism works by assigning weights to each hidden state of the Encoder layer.
- Let’s denote these weights as (αi).
- Alpha is called an Alignment Score.
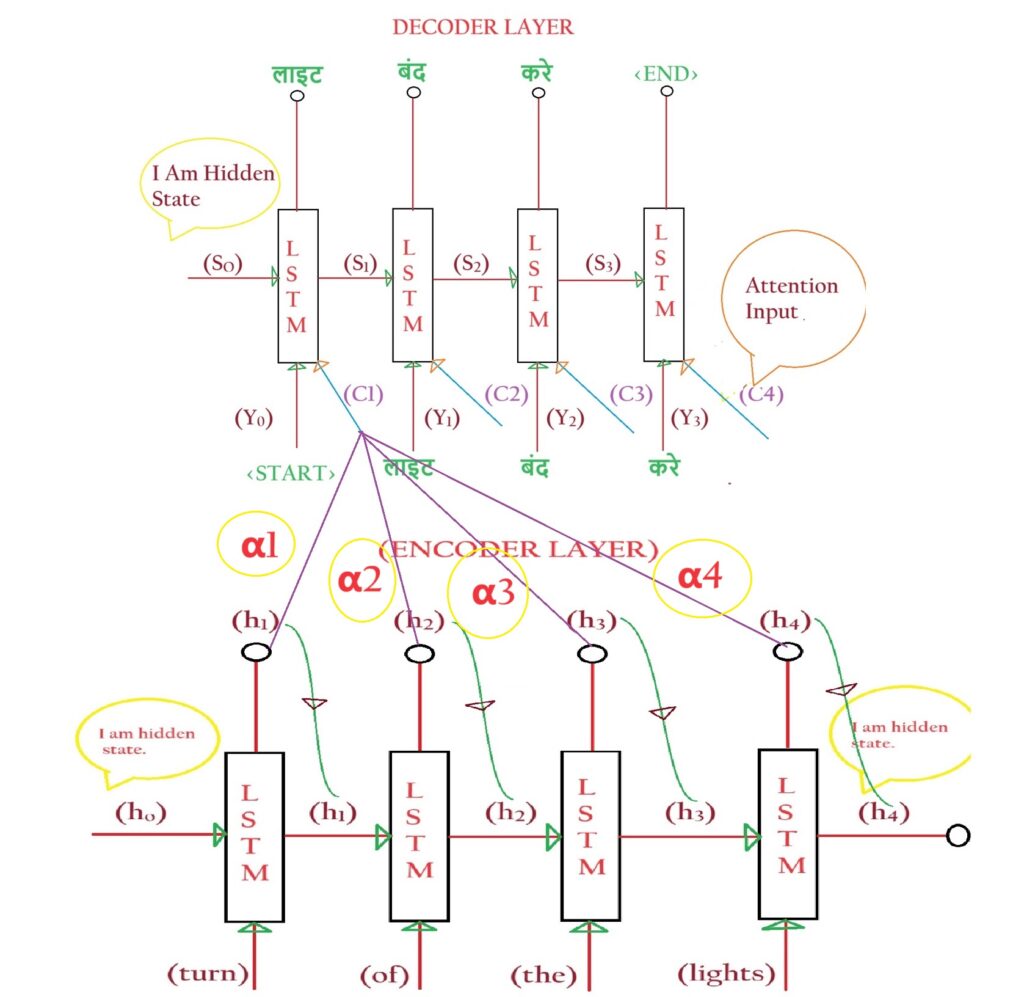
- Ci is the weighted sum of all the hidden state inputs of the Encoder.

- The importance of the hidden state vector (hi) at any time step depends on the corresponding weights (αi)
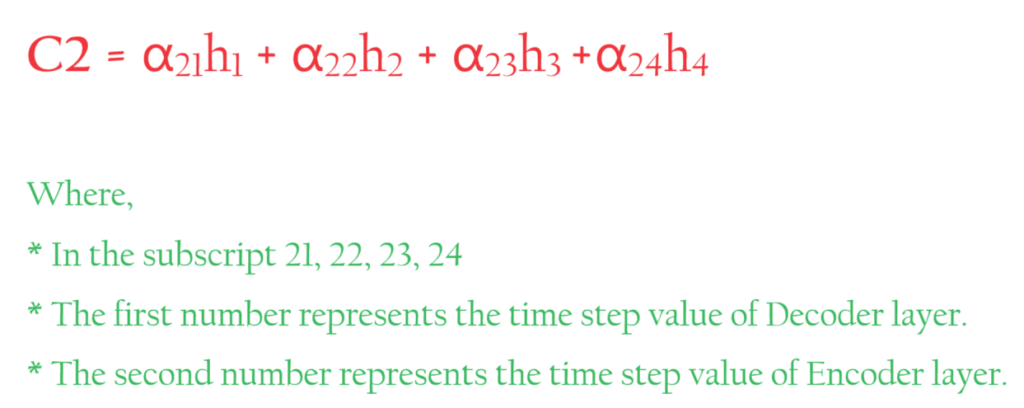
- The formula for Ci would be,
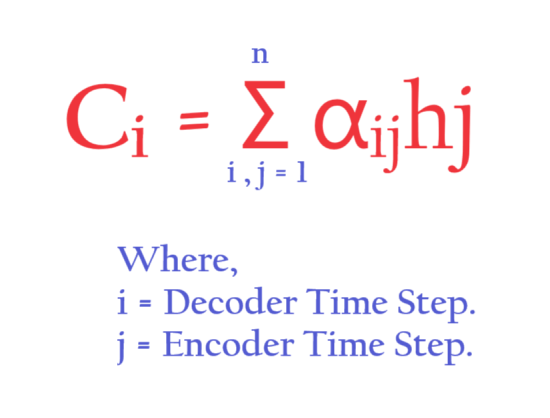
How To Calculate α ?:
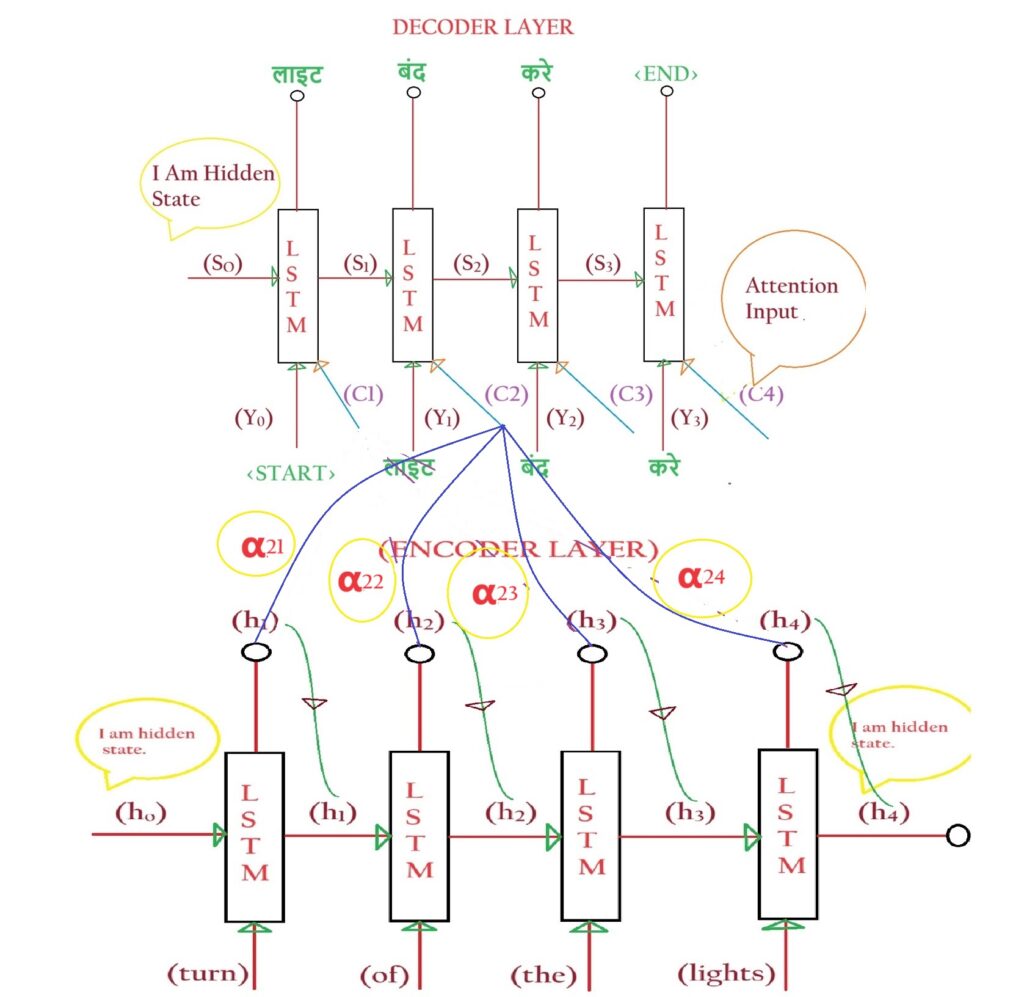
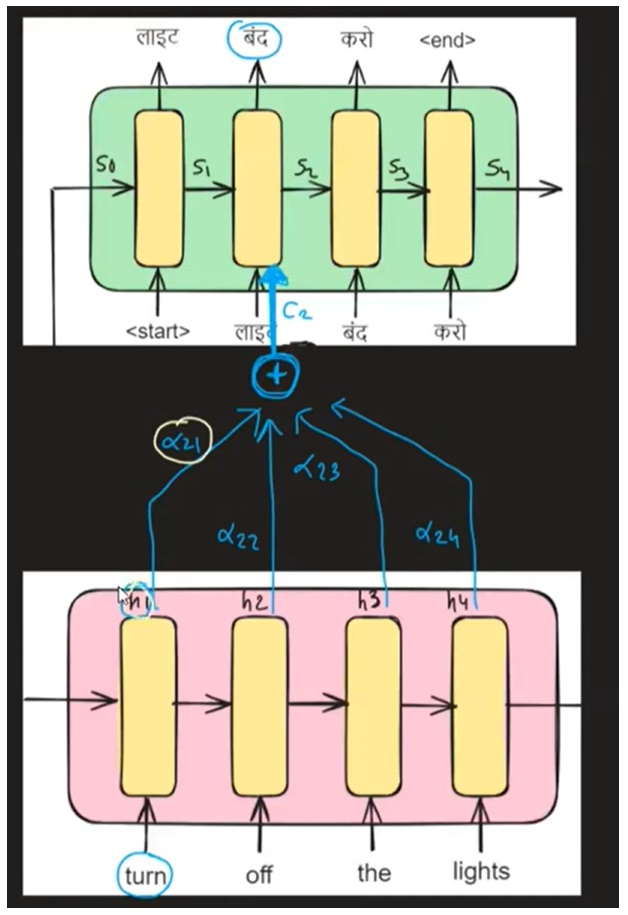
- Let us take the example of α21. And understand how to calculate it.
- We call α as similarity score or alignment score.
- First, we need to know on which factor the α depends.
- As α is the similarity score it finds out the similarity between the “बंद” and “h1” vector which represents ‘turn’.
- Hence α depends on the hidden state vector ‘hj’.
- α also depends on the previous hidden state of the Decoder layer which is denoted by Si vector.
- Let’s understand why α depends on the Si vector.
- So what we do with the Attention Mechanism is that “GIVEN WHAT EVER TRANSLATION WE HAVE DONE TILL NOW BY DECODER LAYER, WHAT IS THE IMPORTANCE OF THE HIDDEN STATE OUTPUT VECTOR TO OUTPUT THE NEXT WORD FROM DECODER LAYER”.
- In our example given “लाइट”, what is the importance of the hidden state vector “h1” which represents the “turn” word?
- Hence α depends on the hidden state vector ‘hj’. and Si.
- This means α depends on “लाइट” and “turn” two words.
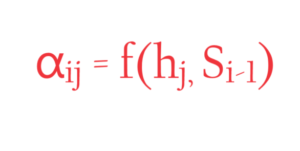
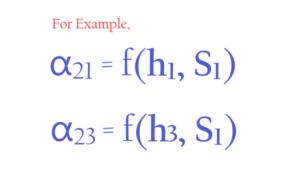
- Now the question is what is this function ‘f’?
- How to derive the function ‘f’?
- One approach is to try out different mathematical functions and see the results of each function, if a function is giving better results use that.
- But it will be super time-consuming.
- What the researchers did is they found a smarter way.
- We already have the power of Artificial Neural Network (ANN), which is called Universal Function Approximation.
- If we provide enough data to the ANN we can use it to approximate any function.
- ANN will adjust weights accordingly so that it will approximate any functions.
- But we can’t see that function. It will be created inside the Architecture.



- How this Neural Network will be trained?
- The answer is that along with the training of the Encoder & Decoder layer the Neural Network will also get trained.