
Cost Functions
Table Of Contents:
- What Is A Cost Function?
- Mean Squared Error (MSE) Loss.
- Binary Cross-Entropy Loss.
- Categorical Cross-Entropy Loss.
- Custom Loss Functions.
- Loss Functions for Specific Tasks.
- Loss Functions for Imbalanced Data.
- Loss Function Selection.
(1) What Is A Cost Function?
- A cost function, also known as a loss function or objective function, is a mathematical function used to measure the discrepancy between the predicted output of a machine learning model and the actual or target output.
- The purpose of a cost function is to quantify how well the model is performing and to guide the optimization process during training.
- The choice of a cost function depends on the specific task and the nature of the data. The cost function assigns a numerical value, often referred to as the “cost” or “loss,” to each prediction made by the model.
- The goal of the optimization process is to minimize this cost function, indicating a better fit between the predicted values and the true values.
- In supervised learning, where the model learns from labeled examples, the cost function evaluates the difference between the predicted outputs and the true labels.
- The optimization algorithm (e.g., gradient descent) then adjusts the model’s parameters to minimize this difference or cost. By iteratively minimizing the cost function, the model aims to improve its ability to make accurate predictions.
- The specific form of the cost function depends on the type of problem being addressed. For regression problems, where the goal is to predict continuous values, common cost functions include mean squared error (MSE) and mean absolute error (MAE). For classification problems, where the goal is to assign input samples to discrete classes, common cost functions include binary cross-entropy and categorical cross-entropy.
- The choice of a suitable cost function is essential, as it affects the behavior of the optimization algorithm during training and the model’s ability to generalize to new, unseen data. A well-designed cost function should accurately capture the performance objective of the problem, be differentiable (for gradient-based optimization), and provide meaningful gradients that guide the learning process.
- It’s worth noting that the terms “cost function,” “loss function,” and “objective function” are often used interchangeably in the literature and may vary depending on the context or specific field. However, their underlying purpose remains the same: to quantify the discrepancy between model predictions and true values and guide the optimization process in machine learning.
(2) Mean Square Error Loss.
- Mean Squared Error (MSE) loss is a commonly used cost function for regression problems. It measures the average squared difference between the predicted output values and the true target values. The MSE loss function is computed as follows:

- The MSE loss calculates the squared difference between each predicted value and its corresponding true value, sums up these squared differences across all samples, and finally averages the result by dividing by the number of samples.
- The squared term in MSE amplifies the errors, giving more weight to larger errors compared to smaller errors. By squaring the differences, the MSE loss penalizes larger deviations more strongly, making it sensitive to outliers or extreme values. Consequently, minimizing the MSE loss encourages the model to reduce both small and large errors.
- The advantages of using MSE loss include its smoothness, differentiability, and the fact that it has a unique global minimum. These properties make it well-suited for optimization algorithms like gradient descent.
- However, it’s important to note that MSE loss may not be appropriate for all regression problems, especially in cases where the distribution of the target variable is skewed or contains outliers. In such situations, alternative loss functions like mean absolute error (MAE) or Huber loss may be more suitable.
(3) Binary Cross Entropy Loss.
- Binary Cross-Entropy (BCE) loss is a commonly used cost function for binary classification problems, where the goal is to assign input samples to one of two classes. The BCE loss measures the dissimilarity between the predicted probabilities and the true binary labels.
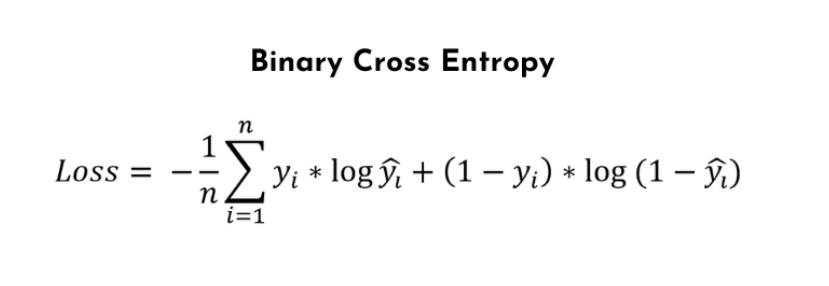

Or

- The BCE loss consists of two terms. The first term, y_true * log(y_pred), penalizes the model when the predicted probability, y_pred, deviates from the true positive class label, y_true = 1. The second term, (1 – y_true) * log(1 – y_pred), penalizes the model when the predicted probability deviates from the true negative class label, y_true = 0. The loss is averaged over all samples in the dataset.
- The log function is used to amplify the errors and penalize larger deviations more strongly. It guarantees that the loss is always non-negative and approaches zero when the predicted probabilities align perfectly with the true labels.
- By minimizing the BCE loss during training, the model learns to assign high probabilities to the correct class (either 0 or 1) and low probabilities to the incorrect class. The BCE loss is commonly used in logistic regression models and neural networks with sigmoid activation functions in the output layer.
It’s important to note that BCE loss assumes that the classes are mutually exclusive (i.e., each sample belongs to only one class). If the problem involves multi-class classification instead of binary classification, the Categorical Cross-Entropy (CCE) loss is typically used.
In summary, BCE loss is a widely used cost function for binary classification problems. It quantifies the dissimilarity between predicted probabilities and true binary labels, and minimizing the BCE loss helps the model converge towards accurate class predictions.
(4) Categorical Cross Entropy Loss.
- Categorical Cross-Entropy (CCE) loss is a widely used cost function for multi-class classification problems. It measures the dissimilarity between the predicted class probabilities and the true class labels.
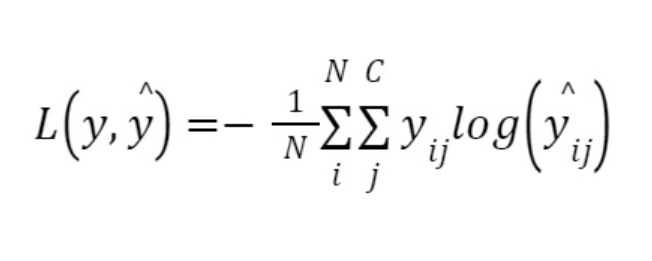
- Here, N is the number of samples,
- C is the number of classes,
- yij is the true output for the i-th sample and j-th class,
- yij is the predicted output for the i-th sample and j-th class.
- The CCE loss is computed by summing over all samples (Σ) and all classes (Σ), multiplying the true class labels (y_true) with the logarithm of the predicted class probabilities (log(y_pred)), and then averaging the result by dividing it by the number of samples (n).
- The logarithm function is used to amplify the errors and penalize larger deviations more strongly. It ensures that the loss is always non-negative and approaches zero when the predicted probabilities align perfectly with the true labels.
- It’s important to note that the y_pred vector must be passed through a softmax activation function before calculating the CCE loss. The softmax function normalizes the predicted probabilities, ensuring that they sum up to 1 and represent a valid probability distribution.
- By minimizing the CCE loss during training, the model learns to assign high probabilities to the correct class and low probabilities to the incorrect classes, ultimately improving its ability to make accurate multi-class predictions.
(5) Custom Loss Function.
- In machine learning, custom loss functions are user-defined cost functions that are tailored to specific problem requirements or objectives. While standard loss functions like Mean Squared Error (MSE) or Binary Cross-Entropy (BCE) are commonly used, there are cases where custom loss functions can be beneficial.
- Custom loss functions allow you to incorporate domain-specific knowledge, address specific challenges, or optimize for specific performance metrics that are not directly captured by standard loss functions. Here are some details on custom loss functions:
Designing A Custom Loss Function: Designing a custom loss function involves defining a mathematical expression that quantifies the discrepancy between the predicted values and the true values. The choice of the expression depends on the problem domain, objectives, and desired behavior of the model.
Flexibility: Custom loss functions provide flexibility in capturing specific properties of the problem. For example, if your problem involves imbalanced classes, you may create a custom loss function that assigns higher penalties for misclassifying the minority class.
Differentiability: Custom loss functions should typically be differentiable to enable gradient-based optimization algorithms. This allows for efficient optimization through backpropagation, which is important for training deep neural networks.
Regularization: Custom loss functions can include regularization terms to control model complexity and prevent overfitting. By incorporating regularization, you can encourage simpler models or impose specific constraints on the model’s parameters.
Evaluation Metrics: Custom loss functions can be designed to optimize for specific evaluation metrics beyond the loss function itself. For example, if accuracy is a crucial metric for your problem, you can design a custom loss function that directly optimizes for accuracy rather than a surrogate loss.
Trade-offs: When designing custom loss functions, it’s important to consider trade-offs. Highly specialized loss functions may improve performance on specific aspects but can also make the learning process more challenging or prone to overfitting. It’s crucial to strike a balance between optimizing for specific objectives and maintaining generalization capability.
- Implementing custom loss functions depends on the machine learning framework you are using. Most frameworks provide the flexibility to define and use custom loss functions by extending their functionality or by specifying a loss function as a callable object.
- Custom loss functions can be particularly useful in research or specialized applications where the standard loss functions may not capture the desired behavior. However, it’s important to carefully design and validate the custom loss function to ensure its effectiveness and compatibility with the learning algorithm and problem requirements.
(6) Loss Function For Specific Task.
- To determine a suitable loss function for a specific task, it’s important to consider the characteristics of the problem, the nature of the data, and the desired behavior of the model. Here are some common tasks and corresponding loss functions:
Regression:
- Mean Squared Error (MSE): Appropriate for tasks where the goal is to predict a continuous numerical value. It penalizes the squared difference between the predicted and true values.
- Mean Absolute Error (MAE): Similar to MSE, but penalizes the absolute difference between the predicted and true values instead of squaring them. MAE is less sensitive to outliers.
Binary Classification:
- Binary Cross-Entropy (BCE) Loss: Suitable for binary classification tasks, where the model predicts the probability of belonging to one of two classes. BCE loss measures the dissimilarity between predicted probabilities and true binary labels.
- Hinge Loss: Commonly used in support vector machines (SVMs) for binary classification. It penalizes misclassifications and encourages correct classification with a margin.
Multi-Class Classification:
- Categorical Cross-Entropy (CCE) Loss: Appropriate for multi-class classification, where the model predicts the probability distribution over multiple classes. CCE loss quantifies the dissimilarity between predicted class probabilities and true class labels.
- Sparse Categorical Cross-Entropy (SCCE) Loss: Similar to CCE loss, but suitable for cases where the true class labels are represented as integers rather than one-hot encodings.
Sequence-to-Sequence Tasks:
- Connectionist Temporal Classification (CTC) Loss: Used in tasks like speech recognition or handwriting recognition, where the alignment between inputs and outputs is not known. CTC loss computes the likelihood of all possible alignments and encourages the model to learn the correct sequence.
Object Detection:
- Intersection over Union (IoU) Loss: Often used in tasks like object detection or instance segmentation. It measures the overlap between predicted bounding boxes and ground truth bounding boxes.
- Focal Loss: Addressing the class imbalance problem in object detection, focal loss assigns higher weights to hard or misclassified examples to focus the model’s attention on challenging instances.
(7) Loss Function For Imbalanced Data.
- When dealing with imbalanced data, where the number of samples in different classes is significantly unequal, standard loss functions may not effectively capture the desired behavior. In such cases, specialized loss functions can be used to address the issue of class imbalance. Here are a few commonly used loss functions for imbalanced data:
Weighted Cross-Entropy Loss:
- Weighted Binary Cross-Entropy (BCE) Loss: In binary classification with imbalanced classes, this approach assigns higher weights to the minority class and lower weights to the majority class. By doing so, it increases the importance of correctly classifying the minority class and helps mitigate the impact of class imbalance.
Focal Loss:
- Focal Loss: Introduced for imbalanced object detection tasks, focal loss assigns higher weights to misclassified examples that are hard to classify. It reduces the loss contribution of well-classified examples, thereby focusing the model on challenging instances and improving performance on the minority class.
Dice Loss:
- Dice Loss: Originally used for medical image segmentation, the Dice loss measures the overlap between the predicted and true segmentation masks. It can help address class imbalance by emphasizing the agreement between the predicted and true positive regions.
Kullback-Leibler Divergence:
- Kullback-Leibler (KL) Divergence: KL divergence measures the dissimilarity between two probability distributions. It can be utilized to emphasize the difference between the predicted class probabilities and a modified target distribution that accounts for class imbalance. This approach encourages the model to assign higher probabilities to the minority class.
Cost-Sensitive Loss:
- Cost-Sensitive Loss: Instead of directly modifying the loss function, this approach assigns different misclassification costs to different classes. By assigning higher costs to misclassifications of the minority class, the model is incentivized to focus on improving performance on the minority class.
- These are just a few examples of loss functions that can be used to address class imbalance. The choice of the appropriate loss function depends on the specific characteristics of the problem and the desired behavior of the model. It’s important to carefully evaluate and experiment with different loss functions to find the one that yields the best results for the imbalanced data at hand.
(8) Loss Function Selection.
- Selecting an appropriate loss function depends on several factors, including the nature of the problem, the type of data, and the desired behavior of the model. Here are some considerations to guide your decision-making process:
Task Type: Identify the task you are working on, such as regression, binary classification, multi-class classification, object detection, or sequence generation. Each task may have specific loss functions designed to address its unique characteristics.
Output Type: Determine the form of the model’s output. For example, if the output is continuous numerical values, regression-specific loss functions like Mean Squared Error (MSE) or Mean Absolute Error (MAE) may be suitable. For binary classification, Binary Cross-Entropy (BCE) loss is commonly used, while Categorical Cross-Entropy (CCE) loss is appropriate for multi-class classification.
Data Balance: Consider whether your data is balanced or imbalanced in terms of class distribution. In cases of class imbalance, loss functions specifically designed to handle such scenarios, like weighted cross-entropy, focal loss, or cost-sensitive loss, may be necessary to address the imbalance and prevent biased predictions.
Evaluation Metrics: Think about the evaluation metrics you care about most for your task. For example, if accuracy is important, you may want to choose a loss function that directly optimizes for accuracy or incorporates it as a part of the loss calculation.
Problem-specific Considerations: Consider any specific requirements or constraints of your problem. For instance, if you need to handle cases where the alignment between inputs and outputs is unknown, a loss function like Connectionist Temporal Classification (CTC) loss might be appropriate for sequence-to-sequence tasks.
Customization Needs: Assess whether you need to incorporate domain-specific knowledge, address particular challenges, or optimize for specific metrics that are not captured by standard loss functions. In such cases, designing a custom loss function may be necessary.
Availability and Compatibility: Consider the availability of loss functions in the machine learning framework or library you are using. Ensure that the chosen loss function is compatible with the framework and can be efficiently optimized through backpropagation.
- It’s crucial to experiment and compare different loss functions to find the one that aligns with your objectives and performs well on your specific task and dataset. Additionally, keep in mind that the choice of the loss function is not fixed and can be adjusted as you gain insights from model evaluation and iterations.