Feature Extraction In NLP
Table Of Contents:
- What Is Feature Extraction From Text?
- Why We Need Feature Extraction?
- Why Feature Extraction Is Difficult?
- What Is The Core Idea Behind Feature Extraction?
- What Are The Feature Extraction Techniques?
(1) What Is Feature Extraction From Text?
- Feature Extraction from text is the process of transforming raw text data into a format that can be effectively used by machine learning algorithms.
- In the context of natural language processing (NLP), feature extraction involves identifying and extracting relevant characteristics or features from the text data that can be used as inputs to predictive models.
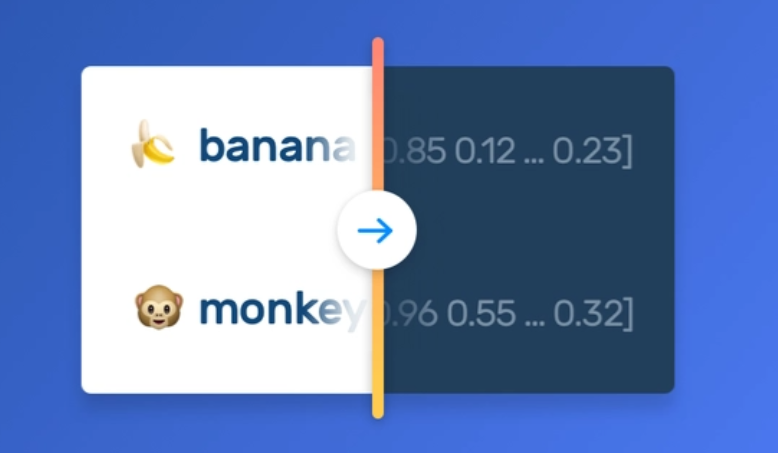
- A feature is an individual measurable property within a recorded dataset. In machine learning and statistics, features are often called “variables” or “attributes.”
- Relevant features have a correlation or bearing on a model’s use case. In a patient medical dataset, features could be age, gender, blood pressure, cholesterol level, and other observed characteristics relevant to the patient.
- In NLP Feature Extraction is a technique of converting text into numbers, so that our Machine Learning models can understand the data.
(2) Why Do We Need Feature Extraction From Text?
Unstructured Data: Text data is inherently unstructured, consisting of words, sentences, and paragraphs that do not have a predefined format. Feature extraction transforms this unstructured data into a structured, numerical representation that can be processed by machine learning algorithms.
High Dimensionality: Text data typically has a large vocabulary, with thousands or even millions of unique words. This high-dimensional feature space can be challenging for many machine learning algorithms to handle effectively. Feature extraction techniques, such as Bag-of-Words or word embeddings, help reduce the dimensionality of the feature space.
Capturing Semantic Meaning: Raw text data does not directly capture the semantic meaning or context of the words and phrases. Feature extraction techniques, like word embeddings, can learn and encode the semantic and syntactic relationships between words, allowing the machine learning model to better understand the underlying meaning of the text.
Handling Ambiguity: Natural language is often ambiguous, with words and phrases having multiple meanings. Feature extraction can help resolve this ambiguity by capturing the context and usage of the words, enabling more accurate predictions and inferences.
Handling Linguistic Variations: Text data can have various linguistic variations, such as spelling errors, regional dialects, or grammatical structures. Feature extraction can help normalize and standardize these variations, making the text data more consistent and usable for machine learning models.
Compatibility with Machine Learning Algorithms: Many machine learning algorithms, such as linear regression, decision trees, or neural networks, require numerical input data. Feature extraction transforms the text data into a format that can be directly used by these algorithms.
Interpretability: Some feature extraction techniques, like Bag-of-Words or TF-IDF, produce feature representations that are more interpretable, allowing you to understand the importance and relevance of different words or phrases in the text data. This can be valuable for tasks like text classification, sentiment analysis, or topic modeling.
Reducing Noise and Irrelevant Information: Text data can contain irrelevant or noisy information that can negatively impact the model’s performance. Feature extraction techniques, along with feature selection methods, can help filter out the irrelevant information and focus the model on the most important aspects of the text.
- If you are solving NLP problems using Machine Learning you need to create some good features from text to feed it to our model.
- For example, if you are doing sentiment analysis one of the features will be the
- “Number Of Words In The Sentence”,
- “Number Of Negative Words In The Sentence”,
- “Number Of Positive Words In The Sentence”,
(2) Why Feature Extraction Is Difficult In NLP?
Images:

- In the case of Image, the data is represented with the pixel value, a number between 0 and 1.
- Hence it will be easier for images to be represented in numbers.
Audios:
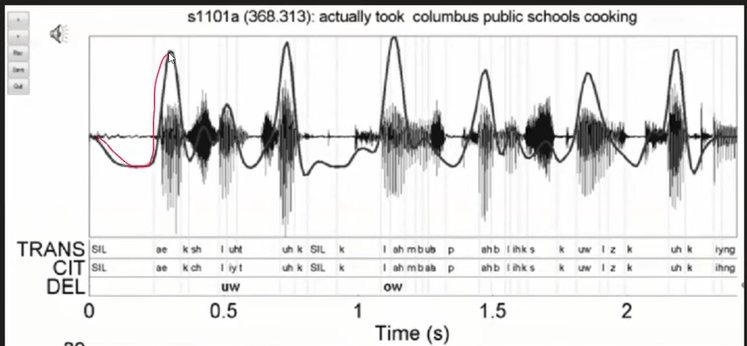
- In audio, the data can be represented with the audio amplitude values.
- Hence, it will also be easier for audio to be represented in numbers.
Text:

- In the case of text, it isn’t easy to represent it in numbers.
- Because we must derive a number that should represent the semantic meaning of the number.
- We have to design sophisticated algorithms to solve this problem.
(4) What Is The Core Ideas Behind Text To Number Conversion?
- Here the main question is what we want to achieve by converting text into numbers.
- The answer is the number should represent the semantic meaning of the word.
- Hence we have to keep this in mind. The success of our model depends on how well we can convert text into vectors.
(5) What Are The Techniques Behind Text To Number Conversion?
- One Hot Encoding.
- Bag Of Words.
- ngrams.
- TF-IDF
- Custom Features.
- Word2Vec.
(6) Common Terms
- Corpus: A Corpus is the collection of all the words in the dataset.
- Vocabulary: Vocabulary is the collection of unique words in the dataset.
- Document: The document is the individual sentences/records present inside the dataset.
- Word: Word is the individual words present inside the dataset.