
Gated Recurrent Units(GRUs)
Table Of Contents:
- Disadvantages Of LSTM Networks.
- What Is GRU?
- Why We Need GRU Neural Network?
(1) Disadvantages Of LSTM Networks.
Computational Complexity: LSTM networks are more computationally complex compared to simpler architectures like feedforward neural networks or basic RNNs. This complexity arises due to the presence of multiple gates, memory cells, and additional parameters. As a result, training and inference can be more computationally expensive and time-consuming, especially for large-scale models and datasets.
Memory Requirement: LSTM networks require more memory to store the additional parameters and memory cells. This can pose challenges when working with limited computational resources or deploying models on memory-constrained devices such as mobile phones or embedded systems.
Difficulty in Interpretability: The complex architecture of LSTM networks can make them challenging to interpret and understand. It may be difficult to analyze and explain how specific inputs or patterns are processed and contribute to the network’s decision-making. This lack of interpretability can be a limitation in certain domains where explainability is crucial, such as healthcare or legal applications.
Overfitting: LSTM networks, like other deep learning models, are susceptible to overfitting, especially when dealing with small datasets. The large number of parameters in LSTM networks makes them prone to memorizing noise or idiosyncrasies in the training data, leading to poor generalization of unseen data. Regularization techniques and careful hyperparameter tuning are often required to mitigate overfitting.
Training Complexity: Training LSTM networks effectively requires careful hyperparameter tuning and managing issues such as exploding or vanishing gradients. Although techniques like gradient clipping and batch normalization can alleviate these problems to some extent, training LSTM networks can still be more challenging compared to simpler architectures.
Longer Training Time: Due to the increased complexity and longer sequence dependencies that LSTM networks can handle, training them may require more iterations or epochs to converge. This longer training time can be a limitation in scenarios where quick model iteration or deployment is required.
Lack of Parallelism: The sequential nature of recurrent computations in LSTM networks limits their parallelizability. While some parallelization techniques exist, such as mini-batch processing and GPU utilization, LSTM networks are inherently more difficult to parallelize compared to feedforward networks. This can result in slower training and inference times.
Conclusion:
- It’s worth noting that while LSTM networks have these potential disadvantages, they have also demonstrated remarkable success in various domains, including natural language processing, speech recognition, and time series analysis.
- The choice of architecture depends on the specific requirements and constraints of the task at hand.
(2) What Is Gated Recurrent Unit?
- The Gated Recurrent Unit (GRU) is a type of recurrent neural network (RNN) architecture that was introduced as an alternative to the more complex Long Short-Term Memory (LSTM) units.
- GRU units aim to simplify the architecture while retaining the ability to capture and model long-term dependencies in sequential data.
- The key idea behind GRU is the introduction of gating mechanisms that control the flow of information and enable the network to selectively update and retain information over time.
- GRU units typically consist of two main gates:
- the Update Gate and
- the Reset Gate.

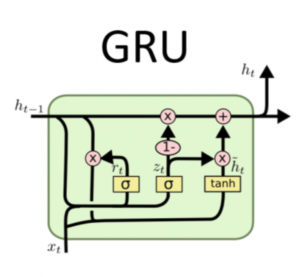
(3) Components Inside Gated Recurrent Unit.
Pointwise Operation:
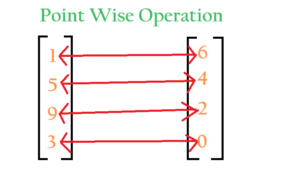
- A pointwise operation, also known as an element-wise operation, is a type of operation that is applied to individual elements of one or more input arrays, without considering the relationship between the elements.
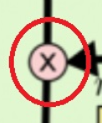
= Pointwise Multiplication

= Pointwise Addition

= 1 – Minus Operation
Dense Neural Network:

- These green boxes are called “Dense Neural Network” layers with sigmoid and tanh activation functions.

- The above structure shows the architecture of the “Dense Neural Network” layer present inside the GRU unit.
Note:
- The number of units inside the dense neural network is a hyperparameter.
- Suppose we choose the number of units/nodes = 5.
- Then the size of the vectors ht-1, xt, rt, zt,~ht and ht will also be 5.
- Hence, the dense neural network’s size will determine the internal vectors’ size.
(4) Steps Involved In Calculating ‘ht’.
- Calculate rt (Reset Gate).
- Calculate ~ht (Candidate Hidden State).
- Calculate Zt (Update Gate).
- Calculate ht (Current Hidden State).
(5) Flow Diagram For GRUs

(6) Reset Gate (rt)
- The reset gate helps the network decide how much of the past information is relevant to the current time step.
- It determines the extent to which the previous hidden state should be reset or forgotten. The reset gate value also ranges between 0 and 1.
- A value of 1 means that all the previous hidden state information is preserved, while a value of 0 means that the previous hidden state is ignored.

- Reset Gate will determine whether the past information is important or not.
- If it is important ‘rt’ will be e.g. [1,1,1,1] i.e. we will keep all the information from the previous state.
- If it is not important ‘rt’ will be e.g. [0,0,0,0] i.e. we will discard all the information from the previous state.
Note:
- Here the question arises: What will be the value inside the previous hidden state?
- The previous hidden state may contain the immediate previous word or the important word before some time step.
(7) What Does The Hidden State Number Signifies?
- Hidden State is nothing but the memory of the system.
- It stores the context of the story.
Story:

- The hidden state represents some form of context of the story.
- For Example: [Power, Conflict, Tragedy, Revenge]
- Individual numbers represent some aspects of the story. In our example,
- The first number represents the ‘Power’ of the story.
- The second number represents the ‘Conflict’ of the story.
- The third number represents the ‘Tragedy’ of the story.
- And The fourth number represents the ‘Revenge’ inside the story.
Special Note:
- It is not mandatory to only have these four aspects of the story, It depends on the neural network and the input text and how it will capture the context.
- When the storylines talk about the power aspects of the story the first number will represent that.
- When there is a conflict in the story the second number will represent that.
- In this way, the GRU network maintains some form of context for the story.
- When Power = 1 the storyline talks about the power aspect of the story.
- When the king dies the Power will be 0.
- Actually, you will not know what it represents in deep learning because it is a black box.
- You can output that number and try to convert it into a word to see what it represents.
- For example [0.9, 0.0, 0.0, 0.0] may mean that now the story is only talking about the power aspect.
- As time passes you introduce new aspects of the story gradually the values will increase. like [0.9, 0.6, 0.0, 0.0]
(8) Steps Involved In Calculating ‘ht’.
- Mainly two steps are there while calculating ‘ht’.
- Step-1: Calculate the Candidate Memory state (~ht) from the previous hidden state (ht-1) and current input (xt).
- Step-2: From Candidate State(~ht) calculate the Current Hidden state(ht).

Step-1: Calculate Candidate Memory State (~ht)
- Suppose as of now we have processed 2 sentences from our story and we have our past hidden state memory ht-1 = [0.5, 0.6, 0.7, 0.1].
- When a new input sentence comes which is (Xt), based on this current input we have to form a new memory which will be our Candidate Memory (~ht).
- That means this memory is the candidate to become our Current Hidden State output (ht) in future.
- Based on our new input sentence suppose we have, (~ht)=[0.8, 0.4, 0.5, 0.3] as a new candidate memory.
- This is step 1 where we got our candidate memory state from the current input and the previous hidden state.
- This candidate’s memory has the potential to become a new memory.
- But directly we can’t make this Candidate Memory (~ht) to our Current Hidden State Memory (ht).
- Because it is heavily inclined towards the Current Input Sentence, it can be the case where this current input is not so important from the overall point of view.
Step-2: Balancing Between (ht-1) and (~ht)
- As of now what we have is (ht-1) and (~ht).
- The (~ht) we got by making changes on (ht-1).
- Now what we will do is decide which one to give more weightage based on our current input.
- That we will do by balancing out between (ht-1) and (~ht).
- If the current input is more important we will give more weight to the (~ht) else we will give more weight to (ht-1).
- Suppose we have (ht-1) = [0.5, 0.6, 0.7, 0.1] and (~ht) = [0.8, 0.4, 0.5, 0.3], if we make an equal balance between these two we will get around [0.65, 0.5, 0.6, 0.2].
(9) Calculation Of (rt)
- The reset gate helps the network decide how much of the past information is relevant to the current time step.
- It determines the extent to which the previous hidden state should be reset or forgotten. The reset gate value also ranges between 0 and 1.
- A value of 1 means that all the previous hidden state information is preserved, while a value of 0 means that the previous hidden state is ignored.
- Reset Gate will determine whether the past information is important or not.
- If it is important ‘rt’ will be e.g. [1,1,1,1] i.e. we will keep all the information from the previous state.
- If it is not important ‘rt’ will be e.g. [0,0,0,0] i.e. we will discard all the information from the previous state.

- (Ur) and (Wr) are the weights of the network.
Explanation:
- Step-1: To calculate (rt) we will take two inputs (ht-1) and (Xt).
- Step-2: Concatenate (ht-1) and (Xt) it will be like [ht-1 Xt].
- Step-3: Pass this concatenation [ht-1 Xt] to a dense neural network layer with a sigmoid (σ) activation function.
- Step-4: The output of the dense layer will be the (rt).
Diagrammatically:

Mathematically:

Vector Dimensions:

(10) Calculation Of (rt * ht-1)
- rt * ht-1 operation is called modulated/reseated memory.
- The result of this operation will tell us how much of the previous state value we want to keep.

- (ht-1)*(ht) = Modulated/Reseated Memory.
- (Ur) and (Wr) = are the weights of the network.
- (ht-1) = Previous state hidden state.
- (Xt) = Current Input value.
- (rt) = Reset Gate.
Example:
- If (ht-1) = [0.6, 0.6, 0.7, 0.1] and (rt) = [0.8, 0.2, 0.1, 0.9]
- (ht-1) * (rt) = [0.6, 0.6, 0.7, 0.1] * [0.8, 0.2, 0.1, 0.9] = [0.48, 0.12, 0.07, 0.09].
- Resting means as the storyline changes based on the input we need to reset our previous hidden state value.
- In our example Power was = 0.6 we have reseated to 0.48, which means the power aspect of the story has decreased.
(11) Calculation Of Candidate Hidden State(~ht)
Explanation:
- Step-1: To calculate ‘Candidate Hidden State’ we will take two inputs.
- Reseated Memory (ht-1)*(ht).
- Current Input Value (Xt).
- Step-2: Apply weights (Uh) to (ht-1)*(ht) and (Wr) to (Xt).
- Step-3: Concatenate both (ht-1)*(ht) and (Xt) = [(ht-1)*(ht) , (Xt)]
- Step-4: Pass this concatenation to the dense layer with the tanh activation function.
- Step-5: The output from the dense layer will be our candidate’s hidden state.
Diagrammatically:

tanh Dense Layer:

Notations :
- (ht-1)*(ht) = Modulated/Reseated Memory.
- (Ur) = Weights of the (ht-1).
- (Uh) = Weights of the (ht-1)*(rt).
- (Wr) = Weights of the (Xt).
- (ht-1) = Previous state hidden state.
- (Xt) = Current Input value.
- (rt) = Reset Gate.
- (~ht) = Candidate Hidden State.
Mathematically:

(12) Update Gate (Zt)
- The update gate determines how much of the previous hidden state should be retained and how much new information should be incorporated into the current state.
- It takes into account the current input and the previous hidden state.
- The update gate value ranges between 0 and 1, representing the extent to which the previous hidden state and the new information should be combined.
- A value of 1 means that all the previous hidden state is preserved, while a value of 0 means that only the new information is considered.
Purpose Of Zt:
- We have our candidate’s hidden state (~ht), but we directly can’t make it to our hidden state output (ht).
- Because (~ht) is heavily skewed towards our input value (Xt).
- We also have to give value to our past hidden state context (ht-1).
- But we don’t know how much value we should give to (ht-1).
- If Xt is really important we should give more importance to (~ht).
- If Xt is not so important then we should give importance to (ht-1).
- Hence update gate (Zt) is a set of numbers that will balance out between (ht-1) and (~ht) it will happen in the training process in Back Propagation.

- When z_t is close to 1, it means the previous hidden state is largely preserved, and the new information has little influence on the current hidden state.
- When z_t is close to 0, it means the previous hidden state is mostly discarded, and the current hidden state is predominantly determined by the new information.
Mathematically:

(13) Calculation Of (ht)
Explanation:
- Step-1: To calculate (ht) we will take two inputs, Update Gate (Zt) and Candidate Hidden State (~ht).
- Step-2: We will calculate (1-Zt) and will do point-wise multiplication with (ht-1) and the result will be (1-Zt)*(ht-1).
- Step-3: We will do point-wise multiplication of (Zt) and (~ht), which will be (Zt*~ht).
- Step-4: Finally we will add the result of step-2 and step-3, which will be (Zt*ht) + (1-Zt)*(ht-1).
Diagrammatically:

Mathematically:

Intuition:
- If (Zt) is high we will give more value to Candidate Hidden State.
- If (Zt) is low (1-Zt) will be high hence we will give more importance to (ht-1).
- In this way, we are making balance between (ht-1) and (~ht).