Introduction To Transformers !
Table Of Contents:
- What Is Transformers?
- History Of Transformers.
- Impact Of Transformers In NLP.
- Democratizing AI.
- Multimodel Capability Of Transformers.
- Acceleration Of GenAI.
- Unification Of Deep Learning.
- Why Transformers Are Created?
- Neural Machine Translation Jointly Learning To Align & Translate.
- Attention Is All You Need.
- The Time Line Of Transformers.
- The Advantages Of Transformers.
- Real World Applications Of Transformers.
- Disadvantages Of Transformers.
- The Future Of Transformers.
(1) What Is Transformers?
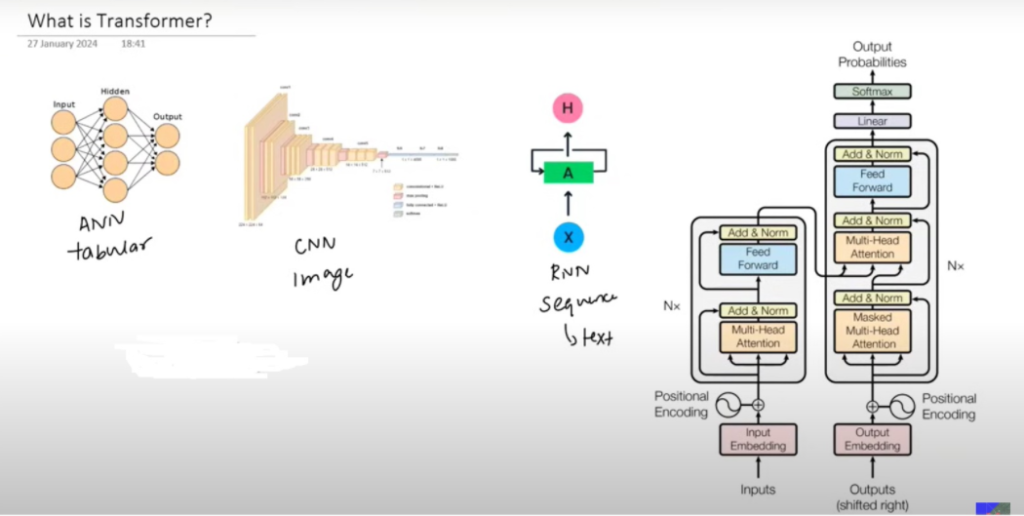
- Transformers is basically a Neural Network Architecture.
- In deep learning, we have already studied the ANN, CNN & RNN.
- ANN works for the cross-sectional data, CNN works for the image data, and RNN works for the sequential data, such as text.
- Transformers are made to handle the Sequence To Sequence task where the input and output will be sequential information.
- Examples will be Machine Translation, Question Answering System, and Text Summarization System.
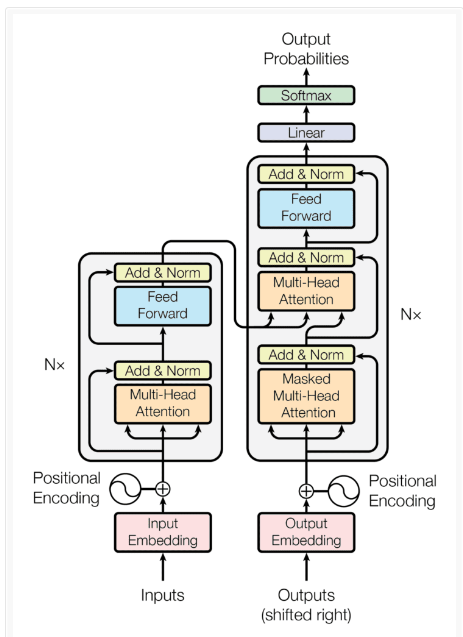
- This is the architecture of the transformers, it looks so complex but it consists of mainly two units.
- One is the Encoder part and another is the Decoder part.
- The key difference is that we don’t use LSTMs inside the encoder and decoder layers.
- Instead of LSTM layers, we use a form of attention that we call as ‘Self Attention’.
- For this reason, the encoder of the transformer can process all the words of the sentence at a time. This we call Parallel Processing.
- For this reason, this architecture is more Scalable, which means it can process large sentences at a single time, it can be trained on Big Data.
- BERT is an example of Transformer architecture, which has trained on entire data from internet.
(2) History Of Transformers?

- In 2017 the transformer architecture was introduced.
- Google Brain has released the paper ‘Attention Is All You Need’.
- It is the first paper in which the concept of the transformer and the concept of self-attention were introduced.
- After this paper, there has been a big revolution in the field of deep learning.
- The most popular software in the world ChatGPT is designed using the Transformers.
- By using the Transformers as the base technology many Startups have created and raised billions of money.
Note:
- It is fun to know that Google researchers have made the Transformers to solve the problem of Machine Translation and achieve state-of-the-art results.
- They also did not know that the Transformers would become a big hit in the future.
(3) Impact Of Transformers?
(a) Revolution In NLP
- The Transformers are built to solve the NLP task and the most impact of Transformers is in the field of NLP also
- Natural language is always very important to human beings, we want how we as humans to talk with each other also we can talk like that with machines.
- In this field, there is work going on for more than 50 years.
- But when Transformers comes whatever the problem we give to it, it will provide the state of the art results.
- The progress that should have happened within 50 years has happened in 5 yers due to transformers.
(b) Democratizing Transformers
- In past when you want to build any NLP applications we have to build our model from scratch using the LSTM & GRUs.
- If we are building models from scratch we need a lot of data and we have to bring our model to a particular state that it will give good results.
- But in reality, for a single Data Science developer it is very difficult to produce a state-of-the-art model.
- But after the Transformer came this thing changed.
- Because the Transformer is too scalable architecture which means we can train them efficiently with big data sets.
- By training the Transformers with Big datasets we got the pretrained models like BERT and GPT.
- BERT and GPT have trained on huge datasets and put them in the public domain so that anyone can download and use them.
- Although it has trained on Big datasets you can also fine-tune or train the model also for smaller datasets for your specific tasks.
- This concept is called Transfer learning.
- Small startups can take a specific domain and train the pre-trained models and can achieve good results.
- Previously it was very impossible.
(c) Multi Model Capability
- One important thing about the Transformer is that the Architecture of the Transformer is more flexible.
- As of now, we have only seen how the Transformers are working on the text-based data.
- But if we want we can work with different types of Data Sets like images, audio etc.
- This is possible because of the Transformer Architecture.
- For example, chatGPT can be used to search using images we can also pass the audio inputs to the ChatGPT because of the Multi-Modal Capability.
- For example, DALL.E works by converting text into images.
- Midjourney generates images from natural language descriptions.
- RunwayML can convert text to videos.
- In video AI tool is used to convert text into videos.
(d) Acceleration Of GenAI
- Generative AI is a technique where you create brand-new text, images, audio and videos.
- Previously we were using models like GANs, by using this model we can generate images. But most of the time we can’t use them in industries and can’t convert them into products.
- But after the Transformers it has revolutionalized the text generation task by creating software like ChatGPT.
- Midjourney, DALLE-like software can create text to images.
- Software like RunwayML can create text-to videos.
- Adobe Photoshop can generate new portions of an Image, and the Google Pixel phone can edit images on the go, if you close your eyes while taking photos you can edit it and can open your eyes.
(e) Unification Of Deep Learning.
- As of now what we are doing in Deep Learning is like we create different solutions for different problems.
- For example, for Tabular data we have ANN, for text data we have LSTM, for image data we have CNN, for generation we use GANs etc.
- We don’t have a single solution for all our problems.
- But after the Transformers came we finally can use it to solve many problems using a single solution.
(4) Why Transformers Were Created?
- Let us first discuss the origin story of the Transformers.
First Paper: Sequence To Sequence Learning With Neural Networks.
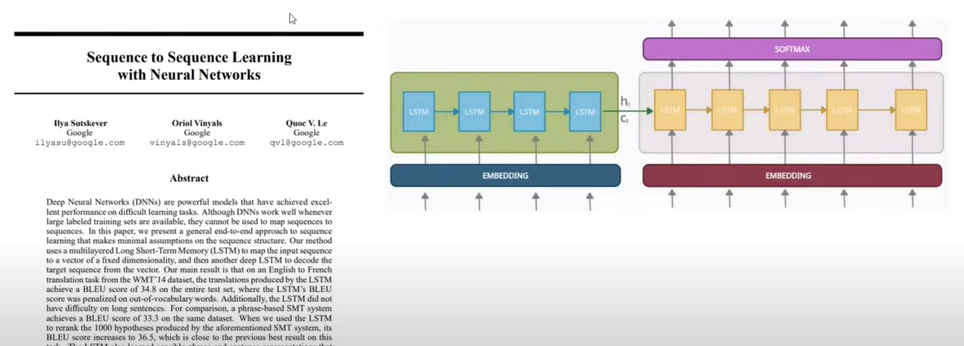
- Around 2014-15 one research paper was released that is “Sequence To Sequence Learning With Neural Networks”.
- This paper introduced an Encoder & Decoder architecture to solve sequence-to-sequence tasks.
- In this architecture in both places, we use LSTM neural networks.
- This architecture works for short sentences for long sentences of more than 30 words it fails to decode properly.
Second Paper: Neural Machine Translation By Jointly Learning To Align & Translate.
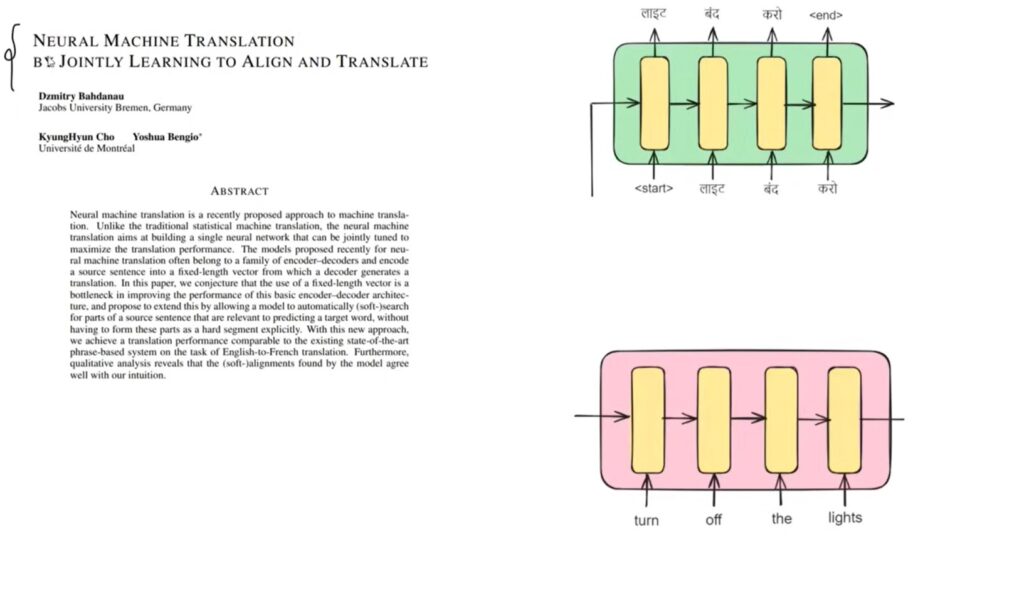
- The above architecture is called attention-based Encoder & Decoder.
- This was the first paper where the concept of Attention was proposed to solve the problem faced by paper one.
- Here the main concept is that to print a particular word we don’t need the entire context of the sentence, we just need a particular word.
- The problem with this architecture is the sequential training, where we have to feed our words sequentially one after another.
- Hence the time of training will be huge for long sentences.
- If we are not able to train our model with a Huge data set we can’t use the concepts like Transfer learning.
- Which means if you want to solve any problem with this model you have to build it from scratch which will not give you the State Of The Art performance.
(5) Attention Is All You Need.
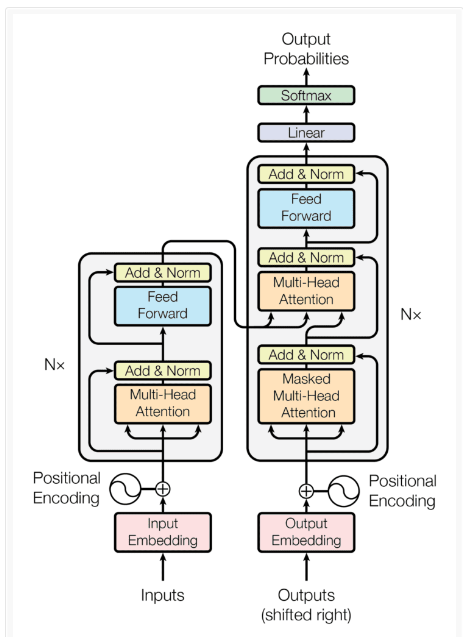
- In 2017 Google Brain released one paper called ‘Attention Is All You Need’.
- In this paper, they have introduced Transformer architecture.
- This architecture completely solves the Sequential problem faced by previous models.
- On a high label, it is an encoder and decoder architecture that is the only similarity but everything has changed inside.
- The major change in this architecture is that we don’t have any LSTM or RNN components inside it.
- The entire architecture is based on one thing which is called ‘Self Attention’.
- The main point about this architecture is that it can be trained in parallel on entire sentences.
- Due to this, it made it a highly scalable architecture.
- We can train it on huge data sets.
- Due to these advantages, we got the concept of ‘Transfer Learning’.
- Due to being highly scalable in nature we got models like BERT, GPT etc.
- The main 3 good things about the Transformer are:
- LSTMs are not being used hence no sequential training.
- More stable architecture by using different components.
- The hyperparameters are very stable and robust. This means the hyperparameters which are being used in the Transformers are much more stable in nature, you can use them to train your model, and you do not need to change any Hyperparameters again.
(6) The Time Lines Of Transformer.

(7) Advantages Of Transformer.
(a) Scalability
- As we are not using the LSTM networks inside the Transformers hence we can train the Transformers parallelly.
- Hence we can train the transfer with huge data sets.
(b) Transfer Learning
- You can train your transformers with huge datasets first and can apply that learning to the new task.
- You can fine-tune the pre-trained Transfer and train it for a specific task.
- This concept is called transfer learning.
(c) Multi Modal Input & Output.
- We can use transformers for a variety of tasks like, image, voice, audio etc.
- Hence it is called multimodal in nature..
(d) Flexible Architecture
- You can also change the architecture of the Transformers itself and can make your own Transformers.
- Like encoder-only Transformers(BERT), decoder-only Transformers like GPT.
(E) Eco Systems
- There is a rich community available on the internet, that they will support and issues you are facing regarding it.
- You will get many libraries and tools regarding Transformers.
- You can use the HuggingFace library to implement and use Transformers in your project.
(F) Ease Of Integration
- You can add GANs and Transformers to generate good-quality images.
- This is being done in the DALLE tool.
- You can combine Reinforcement Learning with Transformers to generate the best Game-playing agents.
- You also can compile CNN with Transformers for doing Image captioning, Visual search etc.
(8) Applications Of Transformer.
(a) chatGPT
- chatGPT is a chatbot which is built upon GPT3 which is a Transformer.
- chatGPT is a generative pre-trained Transformer created by open AI.
- You give a text input to it and it will generate a text output.
- You can use it to write poems, write codes, answer questions etc.
(b) DALL.E-2
- DALL.E-2 is also software by open AI it is also an implementation of the Transformer.
- It basically converts text to images.
(c) AlphaFold
- AlphaFold is designed by the Google Mind team. It uses Transformers behind the scenes.
- It finds out the protein structure of proteins.
- Recently it has decoded the protein structures of many proteins which was a great scientific breakthrough.
(d) OpenAI CodeX
- It is a tool developed by the OpenAI team.
- It is being used to convert the natural language to code.
(9) Disadvantages Of Transformer.
(a) Requires High Computational Resources.
- To train transformers we need GPUs which are costly.
- Hence there is a high computational cost involved while training the transformers.
(b) Requires A Lot Of Data.
- Transformers require a huge dataset for training to get state-of-the-art performance.
- Entire internet data is being used to train the chatGPT application.
- Hence more data brings more performance improvements.