
Leaky ReLU Activation Function.
Table Of Contents:
- What Is Leaky ReLU Activation Function?
- Formula & Diagram For Leaky ReLU Activation Function.
- Where To Use Leaky ReLU Activation Function?
- Advantages & Disadvantages Of Leaky ReLU Activation Function?
(1) What Is Leaky ReLU Activation Function?
- The Leaky ReLU (Rectified Linear Unit) activation function is a modified version of the standard ReLU function that addresses the “dying ReLU” problem, where ReLU neurons can become permanently inactive.
- The Leaky ReLU introduces a small slope for negative inputs, allowing the neuron to respond to negative values and preventing complete inactivation.
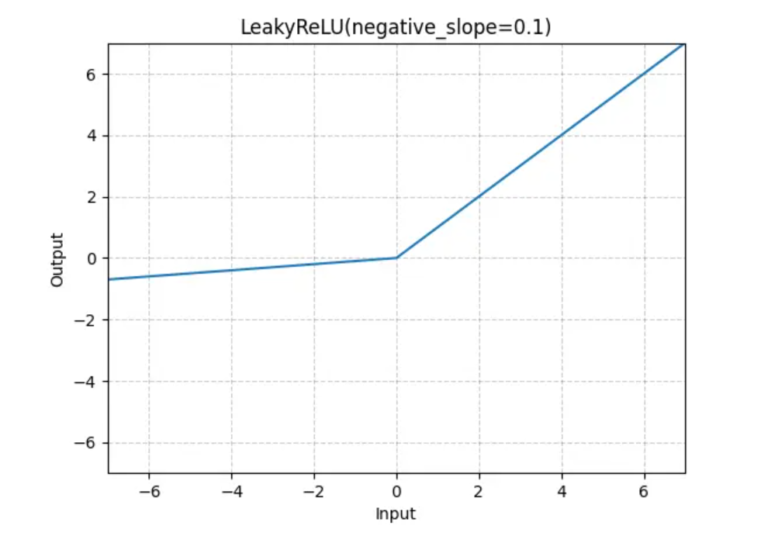
(2) Formula & Diagram For Leaky ReLU Activation Function.
Formula:
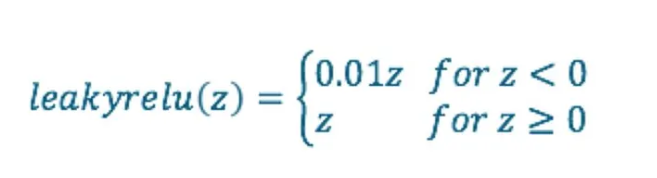
Diagram:
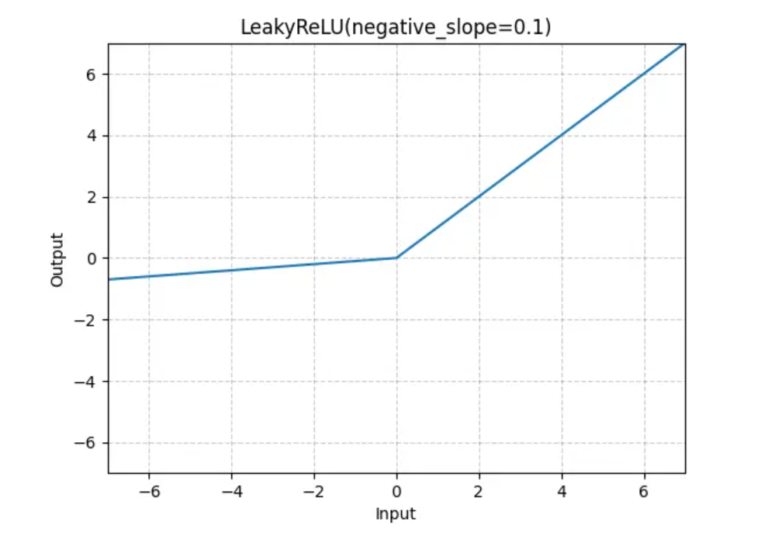
(3) Where To Use Leaky ReLU Activation Function?
- The Leaky ReLU (Rectified Linear Unit) activation function can be used in various scenarios, particularly in deep neural networks, where it addresses some of the limitations of the standard ReLU activation function.
- Here are some situations where the Leaky ReLU is commonly applied:
Deep Neural Networks: The Leaky ReLU is often used in deep neural networks, especially when the network architecture consists of many layers. Deep networks are more prone to the dying ReLU problem, where a significant number of ReLU neurons become permanently inactive. By introducing a small negative slope for negative inputs, the Leaky ReLU helps prevent the complete inactivation of neurons and promotes better learning and representation capabilities.
Networks with Sparse Activation: In some cases, ReLU neurons can be overly sparse, meaning that they are inactive for the majority of the input space. The Leaky ReLU can help alleviate this issue by allowing a non-zero response for negative inputs. By introducing a small negative slope, the Leaky ReLU encourages more active neurons and a richer representation of the data.
Models with Negative Input Values: If the input data or the network’s weights can have negative values, using the standard ReLU would discard all negative information. The Leaky ReLU, with its small negative slope, allows the network to capture and process negative values, preserving valuable information in such scenarios.
Avoiding Dead Neurons: The Leaky ReLU is specifically designed to address the problem of dead neurons, where ReLU neurons become permanently inactive during training. By introducing a small slope for negative inputs, the Leaky ReLU enables these neurons to receive gradient updates and potentially recover from the inactive state. This property makes it useful in situations where the network experiences a significant number of dead neurons.
(4) Advantages & Disadvantages Of Leaky ReLU Activation Function.
Advantages of the Leaky ReLU Activation Function
Prevention of Dead Neurons: The small negative slope introduced by the leak coefficient in the Leaky ReLU helps prevent neurons from becoming permanently inactive, addressing the “dying ReLU” problem. This property allows for potential recovery and learning of previously “dead” neurons, leading to improved model capacity and performance.
Non-Zero Gradient for Negative Inputs: Unlike the standard ReLU activation function, which has a gradient of zero for negative inputs, the Leaky ReLU provides a non-zero gradient for negative values. This property helps mitigate the vanishing gradient problem and facilitates more stable and effective training in deep neural networks, enabling better information flow and learning in the network.
Simplicity and Computational Efficiency: The Leaky ReLU is a simple modification of the standard ReLU, involving the introduction of a small negative slope. This simplicity makes it computationally efficient to compute and implement in neural network architectures, requiring minimal additional computational resources compared to other activation functions.
Disadvantages of the Leaky ReLU Activation Function
Choice of Leak Coefficient: The leak coefficient in the Leaky ReLU is a hyperparameter that needs to be tuned. While a small value like 0.01 is commonly used, different values may yield different results. Determining the optimal leak coefficient requires experimentation and validation on the specific problem and dataset at hand.
Lack of Saturation Control: The Leaky ReLU does not have an upper bound for positive inputs, which means that it does not saturate like the sigmoid or tanh functions. In some cases, this lack of saturation can lead to unstable behavior in the network or cause the activation values to grow without bounds. It is necessary to monitor and control the saturation of activation values when using the Leaky ReLU.
Activation Output Range: The Leaky ReLU, similar to the standard ReLU, maps negative inputs to negative outputs but allows positive inputs to pass through unchanged. This can result in an unbalanced output range, where negative values are preserved while positive values are unbounded. It is important to consider the implications of this output range on the specific task and ensure it aligns with the requirements of the problem.