Luong’s Attention !
Table Of Contents:
- What Is Luong’s Attention?
- Key Features Of Luong’s Attention Model?
- Advantages Of Luong’s Attention Model?
- Architecture Of Luong’s Attention Model.
- Why do We Take the Current Hidden State Output Of The Decoder In Luong’s Attention Model?
- Architecture Luong’s Attention Model.
- Difference In Luong’s Attention & Bahdanau’s Attention
(1) What Is Luong’s Attention?
Luong’s attention is another type of attention mechanism, introduced in the paper “Effective Approaches to Attention-based Neural Machine Translation” by Minh-Thang Luong, Hieu Pham, and Christopher D. Manning in 2015.
Luong’s attention mechanism is also designed for encoder-decoder models, similar to Bahdanau’s attention, but with some differences in the way the attention weights are computed.
(2) Key Features Of Luong’s Attention Model?
(1) Attention Scores:
- Luong’s attention mechanism computes attention scores, which represent the relevance of each input element to the current output being generated.
- The attention scores are computed as a function of the current decoder hidden state and the encoder hidden states.
(2) Attention Weights:
- The attention scores are then normalized using a softmax function to obtain the attention weights.
- The attention weights represent the proportion of importance assigned to each input element.
(3) Attention Mechanisms:
- Luong’s paper introduces three different attention mechanisms:
- Global attention: The attention weights are computed based on all the encoder hidden states.
- Local attention: The attention weights are computed based on a subset of the encoder hidden states, typically a window around the previously attended position.
- Hybrid attention: A combination of global and local attention, where the attention mechanism is dynamically selected based on the current state of the model.
(4) Context Vector:
- Similar to Bahdanau’s attention, the attention weights are used to compute a weighted sum of the encoder’s hidden states. This is then used as an additional input to the decoder’s next step.
(3) Advantages Of Luong’s Attention Model?
Luong’s attention mechanism provides more flexibility in the way the attention weights are computed, and the different attention mechanisms (global, local, and hybrid) can be more suitable for different types of tasks and input sequences.
Luong’s attention mechanism has also been widely used in various encoder-decoder models, and it has been an important contribution to the development of attention-based neural networks in natural language processing and other domains.
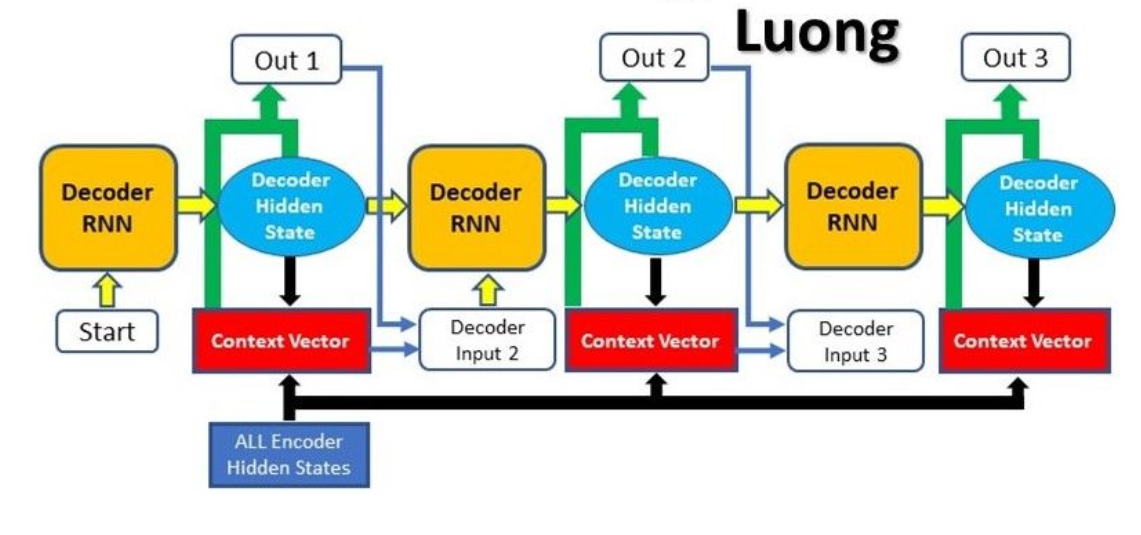
(4) Architecture Of Luong’s Attention Model.
- Let us consider the above Encoder & Decoder architecture.
- Let’s apply the Luong’s Attention mechanism in this model.
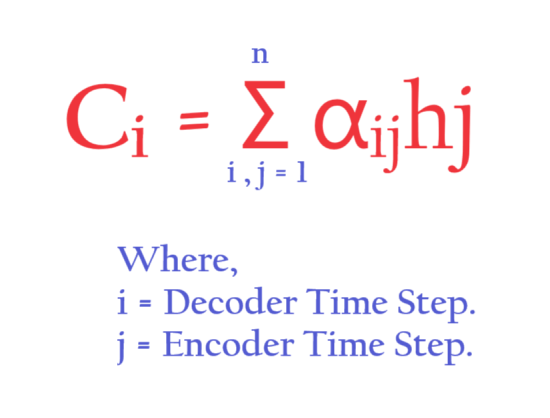
- In Luong’s Attention mechanism we also have to calculate the Ci value.
- Ci is the weighted sum of all the encoder hidden state output.

- In Bahdanau’s Attention we calculate α using the above formula.
- Here you can see that α is the function of current hidden state output of the Encoder and previous hidden state output of the Decoder.
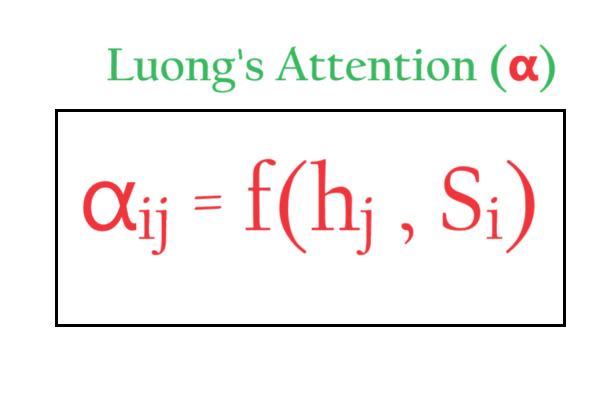
- In Luong’s Attention we calculate α using the above formula.
- Here you can see that α is the function of current hidden state output of the Encoder and also the current hidden state output of the Decoder.

- In case of Bahdanau’s Attention we use an Artificial neural network to approximate the function that will capture relationship between ‘α‘ and (hj, si-1)


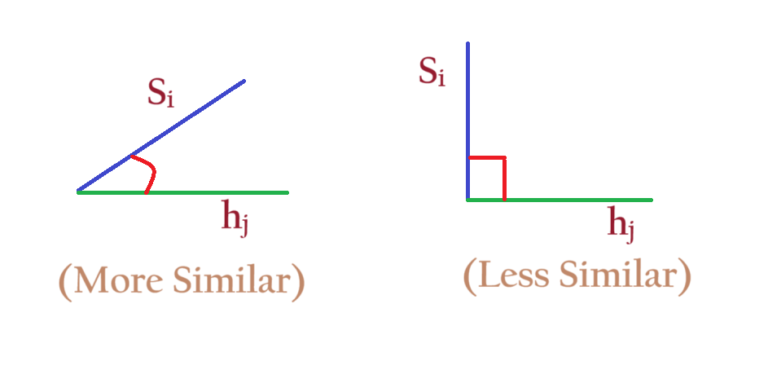
- In case of Luong’s Attention we use dot product between Si and hi to calculate the α value.
- The α is called the Similarity score, which calculate the similarity between Si and hi.
- If we take the dot product of Si and hi It will give us a scalar quantity to normalize the scalar between 0 to 1 we pass it through the SOFTMAX function.
- If two vectors are more similar there dot product will be more, or else it will be less.
(5) Why We Take Current Hidden State Output Of The Decoder In Luong’s Attention Model?
- In Luong’s attention mechanism, the current hidden state of the decoder is used in the computation of the attention scores for a few key reasons:
- Decoder’s current state represents the word that is going to be currently outputted.
- By seeing the current output word we can guess which input word needs high Attention.
(1) Capturing The Current Context:
- The current hidden state of the decoder represents the model’s current understanding of the output sequence being generated. This information is crucial in determining which parts of the input sequence are most relevant for generating the next output token.
- By incorporating the decoder’s current hidden state, the attention mechanism can focus on the parts of the input that are most useful for the current step of the output generation process.
(2) Aligning Input And Output:
- The attention mechanism aims to align the relevant parts of the input sequence with the current output being generated. Using the decoder’s current hidden state helps the attention mechanism identify the appropriate correspondence between the input and output.
- This alignment can improve the model’s ability to accurately generate the output sequence, as the attention mechanism can focus on the most relevant parts of the input.
(3) Exploiting The Encoder-Decoder Structure:
- Encoder-decoder models, such as those used in machine translation, have a natural information flow from the encoder to the decoder. The decoder’s current hidden state represents the model’s internal state at the current step, which can be used to guide the attention mechanism to the most relevant parts of the encoded input.
(4) Improving interpretability:
- By using the decoder’s current hidden state, the attention mechanism can provide insights into the model’s decision-making process. The attention weights can help interpret which parts of the input are most influential for generating the current output token.
- This interpretability can be useful for understanding the model’s behavior and potentially improving its performance.
Conclusion:
- In summary, the use of the decoder’s current hidden state in Luong’s attention mechanism allows the model to effectively align the input and output sequences, capture the current context, and improve the interpretability of the attention mechanism, which can lead to better overall performance in encoder-decoder models.
(6) Architecture Luong’s Attention Model.

Step-1: Calculation Of α.
- In the case of Luong’s Attention Model, the calculation of α is different.
- Let us understand how to calculate α.
- The α is calculated using the below formula.

- α tells us the importance of the Encoder’s hidden state output for predicting the output of the decoder layer.
- We have to calculate α for each Encoder’s Hidden State output. To know the importance of each hidden state output.
- Let us understand the steps to calculate the value of α.
- By applying the ‘Attention Mechanism’ we want to know the importance of the encoder’s hidden state for predicting the translation.
- The importance is measured using the value of α.
- First, we take the current state output of the Encoder (S1) and Decoder (h1)
- Second, we take the dot product of (S1) and (h1) to find out the similarity of (S1) and (h1). If the dot product is high it means it is more similar, if it is less it means it is less similar.
- Third, the dot product can be of any value. To normalize it we pass it through the ‘SOFTMAX’ layer. It will transform values between 0 to 1.
- Fourth, in this step, we have calculated α11 = S1.H1
- Fifth, we will calculate α12 = S1.H2, α13 = S1.H3, α14 = S1.H4,
- Sixth, Finally we combine all the α values by taking the weighted sum of encoders’ hidden state outputs.

- Let us understand the architecture of the Attention Vector.
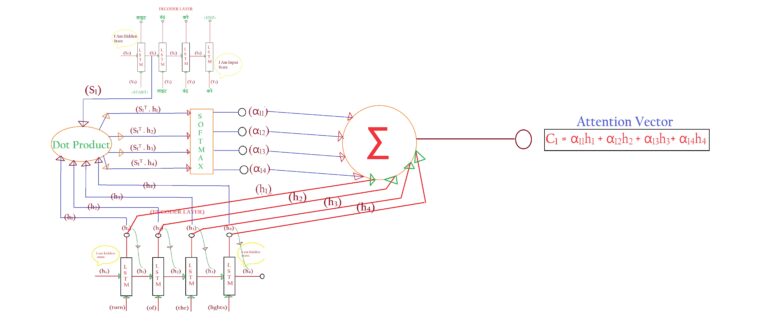
- Once we calculate the α value we need to calculate the Attention Vectors(Ci).
- The Ci is calculated using the weighted sum of the α and h.
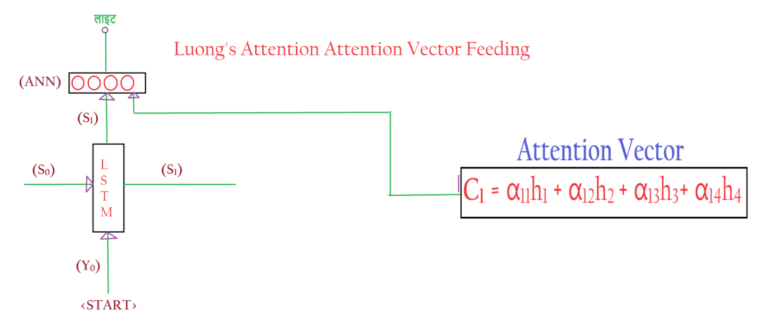
- Once we calculate the Ci value we pass it to the ‘Decoder’s’ output where it combines with the Si and goes inside the ANN layer for prediction.
(7) Difference In Luong’s Attention & Bahdanau’s Attention
- In the case of Bahdanau’s attention, we pass the attention vector to the input of the decoders’ LSTM layer.
- But in the case of Luong’s attention, we pass the attention vector to the output of the decoders’ LSTM layer.
- Luong’s attention is proven more effective then the Bahdanau’s Attention.