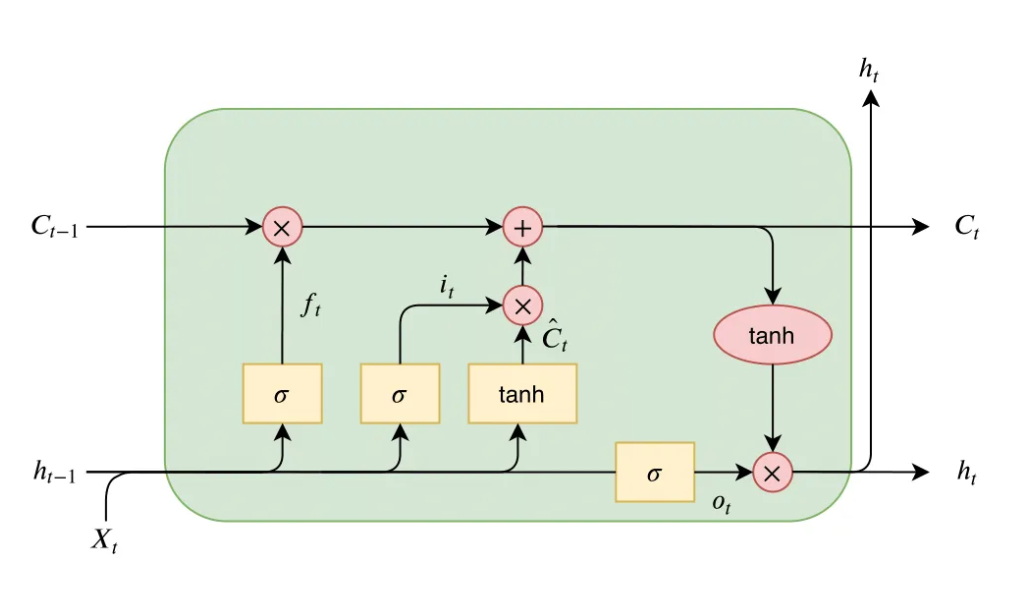
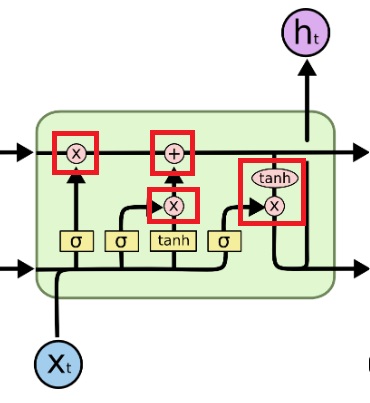
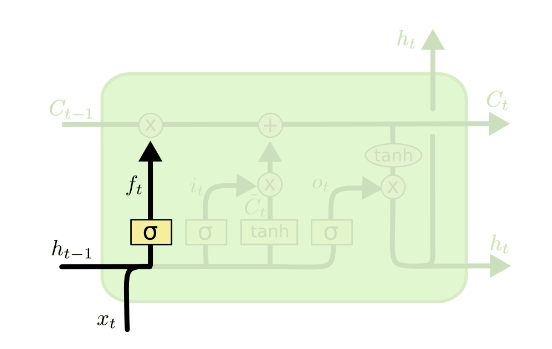
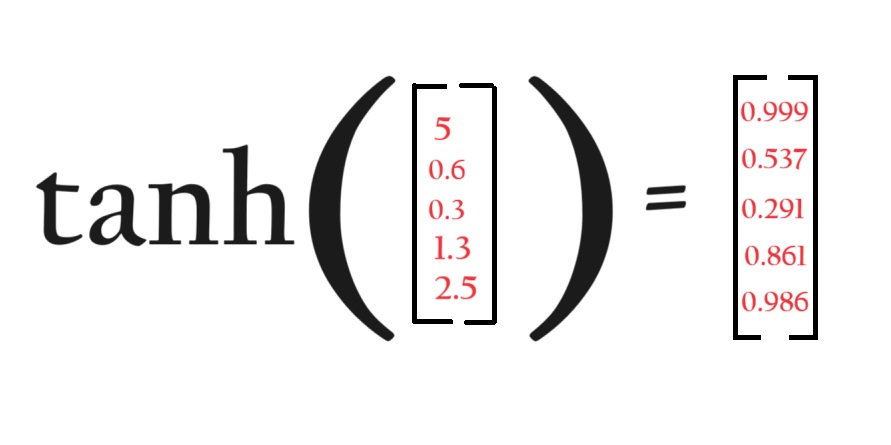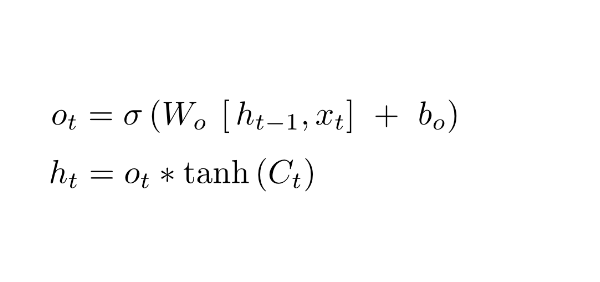A 1 represents “completely keep this” while a 0 represents “completely get rid of this.”
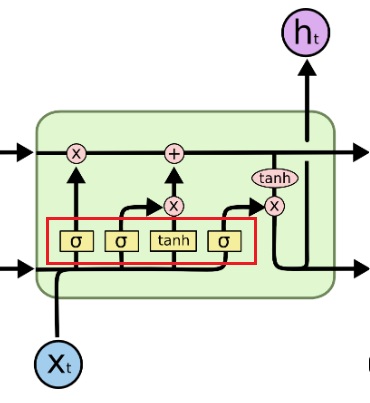
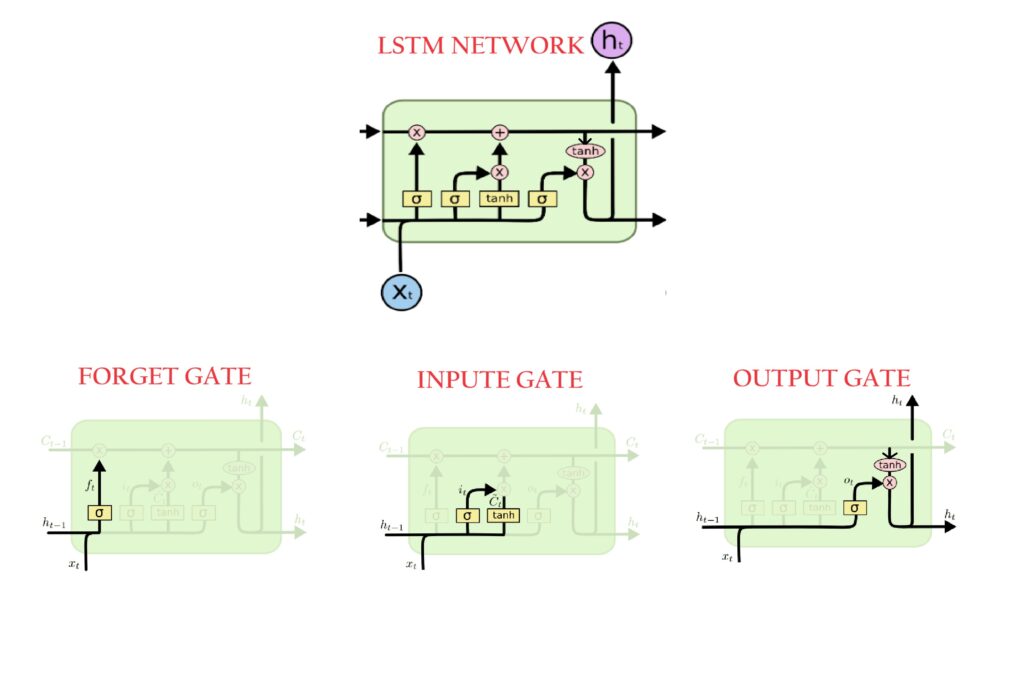
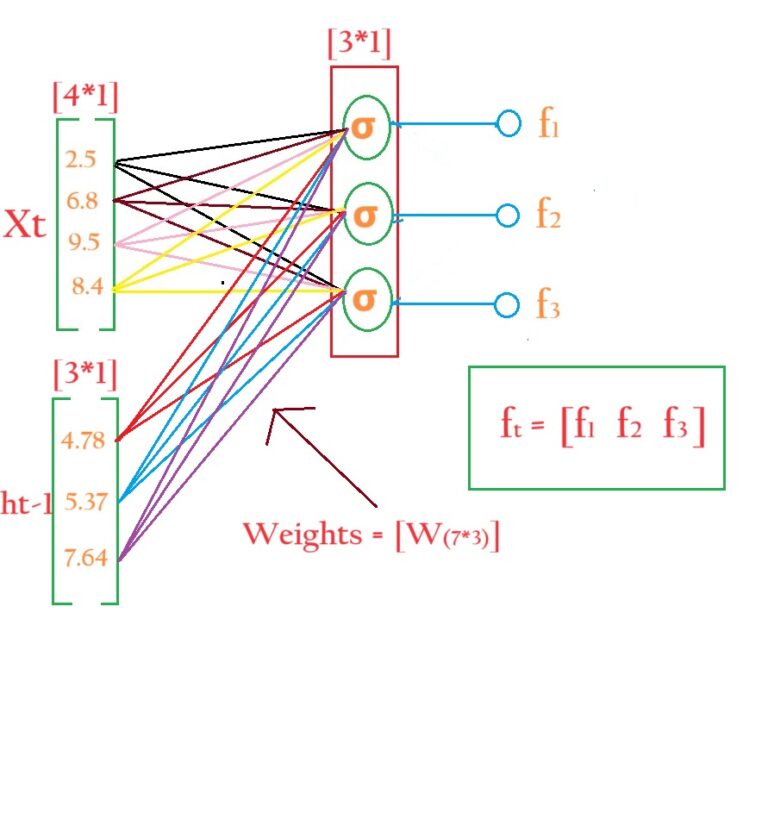
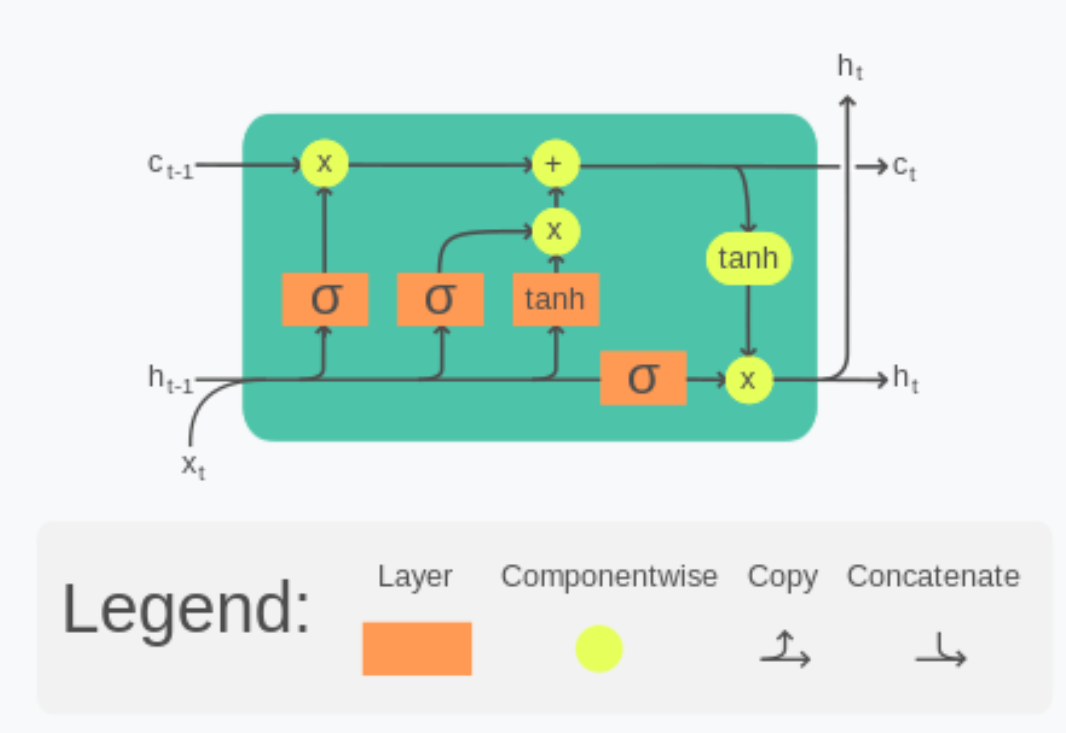
Forget Gate Calculation:
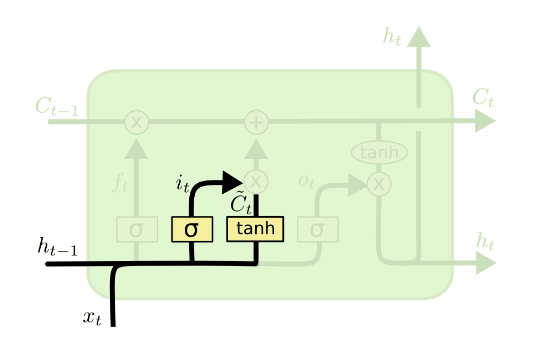
Input Gate:
The next step is to decide what new information we’re going to store in the cell state.
This has two parts.
First, a sigmoid layer called the “input gate layer” decides which values we’ll update.
Next, a tanh layer creates a vector of new candidate values, ~Ct, that could be added to the state. In the next step, we’ll combine these two to create an update to the state.
Input Gate works in 3 stages.
Calculate Candidate Cell State (~Ct). (The new word that may go into the cell state.)
Calculate “it”. ( It will decide whether to store the candidate value in the cell state.)
Calculate Ct.
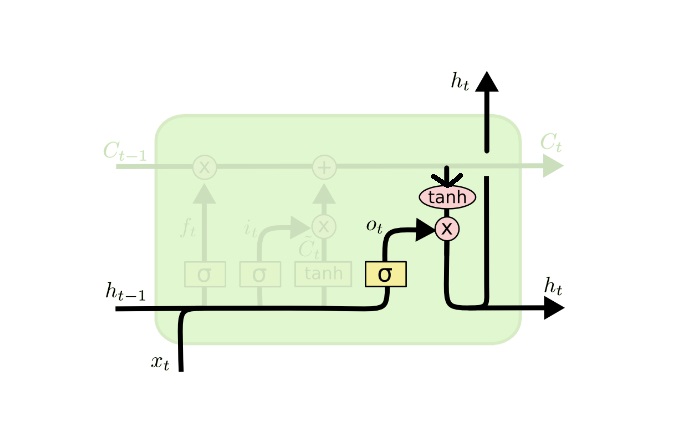
Output Gate:
Finally, we need to decide what we’re going to output. This output will be based on our cell state but will be a filtered version.
First, the values of the current state and previous hidden state are passed into the third sigmoid function.
Then the new cell state generated from the cell state is passed through the tanh function (to push the values between −1 and 1).
Both these outputs are multiplied point-by-point so that we only output the parts we decided to.
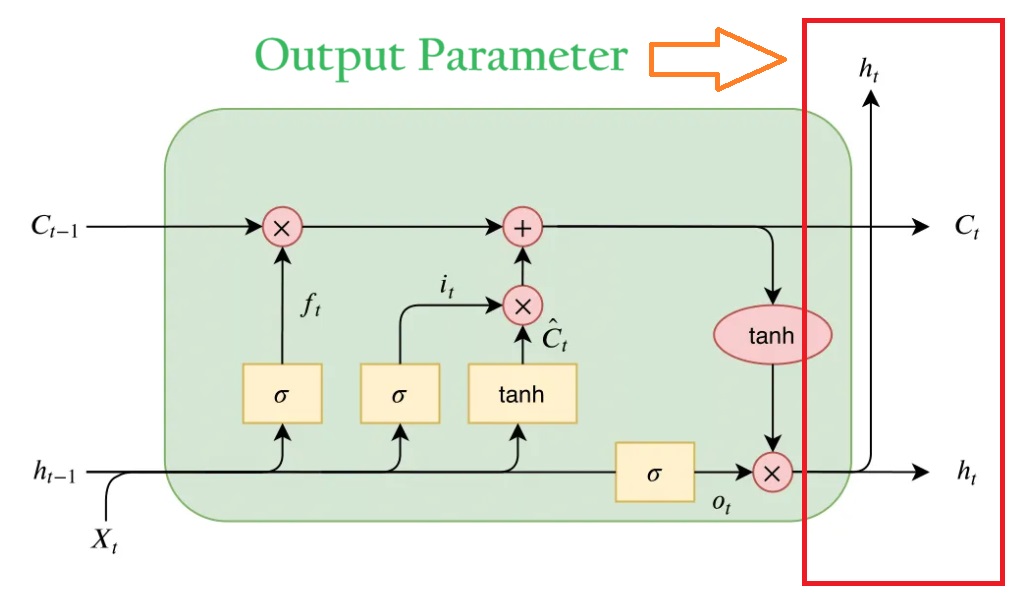
This hidden state is used for prediction.
The output for the current time step is dependent on the Current Cell State value.
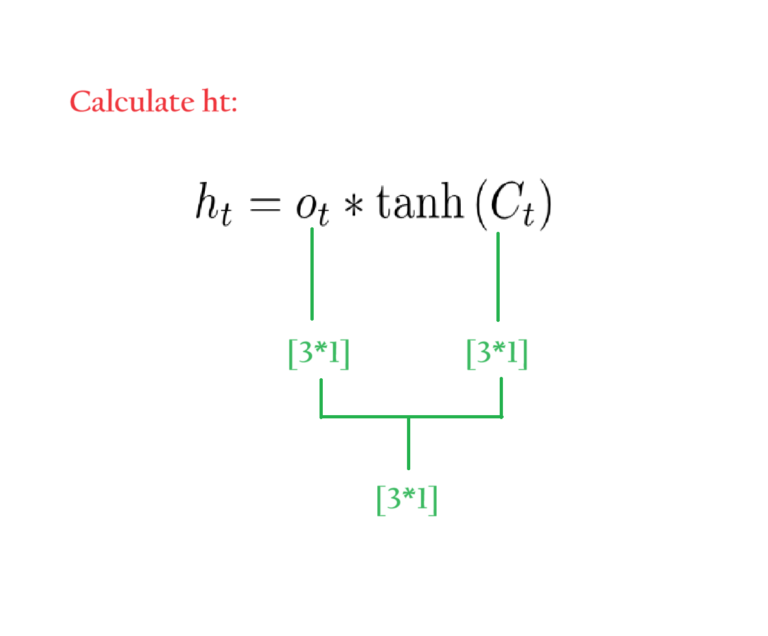
ht is derived from the long-term memory or cell state Ct.
ht is calculated in two steps.
tanh(Ct) = Element wise tanh operation on Ct. It will bring values between [-1 1].
Calculate Ot to apply the filter on tanh(Ct).
Apply filter on tanh(Ct) by doing point-wise multiplication on Ot.
Finally, the new cell state and new hidden state are carried over to the next time step.
Conclusion:
To conclude, the forget gate determines which relevant information from the prior steps is needed.
The input gate decides what relevant information can be added from the current step, and the output gates finalize the next hidden state.