NLP Pipeline
Table Of Contents:
- What Is NLP Pipeline?
- Steps Under NLP Pipeline.
- Data Acquisition.
- Text Preprocessing.
- Feature Engineering.
- Model Building.
- Model Evaluation.
- Model Deployment.
(1) What Is NLP Pipeline?
- An NLP (Natural Language Processing) pipeline is a series of interconnected steps or modules used to process and analyze natural language data.
- The pipeline typically consists of several stages, each performing a specific task in the overall process of understanding and extracting useful information from unstructured text.
- The NLP pipeline is a set of steps to build an end-to-end NLP software.

(2) Steps Under NLP Pipeline.
- Data Acquisition.
- Data Acquisition is an important step in the Natural Language Processing (NLP) pipeline.
- It involves the process of collecting, gathering, and obtaining the raw text data that will be used for various NLP tasks.
- Text Preparation.
- Text preprocessing is an essential step in natural language processing (NLP) that involves cleaning and transforming unstructured text data to prepare it for analysis.
- It includes tokenization, stemming, lemmatization, stop-word removal, and part-of-speech tagging.
- Feature Engineering.
- You need data in the correct format before feeding it into a Machine Learning or Deep Learning model.
- In this step, we need to convert our sentences to numeric vector form so that our algorithm can understand them.
- Modelling.
- In this step, we are actually applying the algorithms in our input data.
- It consists of two steps. (1) Model Building (2) Model Evaluation.
- Deployment.
- After model building the final step is the deployment.
- In this step, you deploy your model in any cloud service platform so the user can access it.
- It consists of three steps
- (1) Model Deployment,
- (2) Model Monitoring
- (3) Model Updating.
(3) Data Acquisition.
- Data Acquisition is an important step in the Natural Language Processing (NLP) pipeline.
- It involves the process of collecting, gathering, and obtaining the raw text data that will be used for various NLP tasks.

Data Is Available:
Case-1: Data Is With You
- In this case, the data is available to you on the spot like in a CSV file, excel file etc.
- You don’t have to do anything in this step for data acquisition.
- You can proceed with the next step.
Case-2: Data Is In Database
- In this case, the data is available in your company’s database.
- You have to talk with your Data Base team to get the data from the company’s Data Base.
Case-3: Less Data
- In this case, you have the data but it’s quite less In amount.
- You can’t build your NLP application with this small amount of data.
- In this case, you have to use the “Data Augmentation” technique.
- In this technique, you will create some fake data and when you have more amount of data you can train your model with it.
- Some of the techniques under Data Augmentation are “Synonym Replacement”, “Bigram Flip”, “Back Translate”, “Adding Additional Noises”, etc.
Data Is With Others:
Case-1: Use Public Data Set
- You can collect data from publically available platforms like Kaggle, GitHub, Universities Websites etc.
- One problem may arise that the public data may not be suitable for your unique use case.
- Then your model will not be able to predict correctly as per your use case.
Case-2: Use Web Scrapping
- You can go to your competitor’s website and use Web Scrapping techniques to collect information.
- You can use the “BeautifulSoup” technique for web scrapping.
- Sometimes it will be difficult to do web scrapping because the designing of the websites varies from one another.
- You will get some unwanted text after doing web scraping those texts you have to filter them out.
Case-3: Use Available APIs
- You can hit some publicly available APIs and get the data out of it.
- You have to search for the API that will be suitable for your use case.
- One of the websites is, “RapidAPI.com” Here you will get the list of APIs on different domains.
- You can use the ‘Request’ Python library to fetch data from APIs.
- Here you will get data in JSON format that you have to convert into the text file.
Case-4: Data Is In pdf File.
- Sometimes data will be in PDF format, which you have to convert into text format.
- You can use the available Python library to convert pdf to text.
Case-5: Data Is In Image File.
- Sometimes data will be in image format, which you have to convert into text format.
- You can use the available Python library to convert images to text.
Case-6: Data Is In Audio File.
- Sometimes data will be in audio format, which you have to convert into text format.
- You can use the available Python library to convert audio to text.
Data Is Not Available:
- In this case, you don’t have any data at all. You are newly developing the application for that use case, no one has worked on before you.
- In that case, you have to talk to your product team to provide information about that product.
- Suppose you are building one “Sentiment Analysis” use case, you will need some customer reviews for your analysis.
- Here your product team will ask your software development team to put a customer review tab on the product website.
- Your first work will be to collect those reviews and manually label them as positive or negative reviews.
- After that, you can use those data for your sentiment analysis problem.
(4) Text Preprocessing.
- Text preprocessing is an essential step in natural language processing (NLP) tasks.
- It involves transforming raw text data into a format that can be more easily and effectively processed by machine learning models.

Step-1: Clean And Standardize The Text:
- Clean and standardize the text: This includes tasks like removing HTML tags, URLs, special characters, punctuation, numbers, and converting the text to a consistent case (e.g., all lowercase).

- Replace Emojis: Emojis can’t be understood by Machine Learning models, these need to be converted to some numeric form.
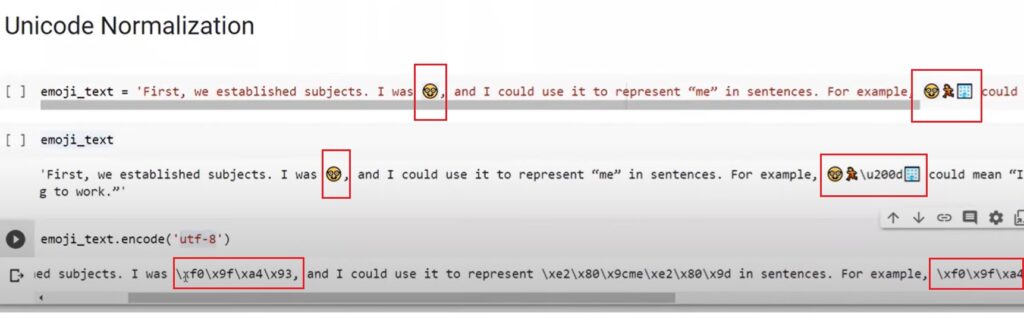
- Spelling Checker: Sometimes users type fast on the keyboard, chances are there for spelling mistakes. You need to correct your word spelling before feeding data to ML models.

Step-2: Basic Test Preprocessing
- Basic Preprocessing: Under text basic preprocessing we have two steps.
- Mandatory Steps.
- Optional Steps
Mandatory Steps:
- Mandatory Steps:: These are the compulsory steps that you need to perform before feeding data into NLP models.
- Tokenization.
(1) Tokenization: The process of breaking the text into smaller, meaningful units called tokens, such as words, phrases, or n-grams.
- It’s of two types,
- (1) Sentence Tokenization and
- (2) Word Tokenization.


Optional Steps:
- Optional Steps:: The optional steps are performed based on your business use case.
- Stop Word Removal
- Stemming or Lemmatization.
- Removing Digits, Punctuation Marks etc.
- Lower Casing.
- Language Detection.
(1) Stop Word Removal:
- Identifying and removing common words (e.g., “the”, “a”, “is”) that are unlikely to contribute meaningful information to the analysis.
- If you want to derive the meaning of the sentence then these stop words don’t add any meaning to my sentence. Hence you can remove them.
- You can’t remove stop words in the Language Translation use case.

(2) Stemming Or Lemmatization
- Reducing words to their base or root form, which can help to normalize the vocabulary and improve the performance of downstream NLP models.

(3) Removing Digits, Punctuation Marks etc.
- In some use cases digits, punctuation marks, and question marks don’t add any value to the sentence.
- That time you can remove them.
(4) Lower Casing
- It is advisable to bring all of your words into lower cases before processing.
- Sometimes same words will be in upper or lower cases that time the model will consider it as two different words.
- Hence you need to bring them as lower case.

(5) Language Detection
- Before you do any NLP task you must know which language the text is present.
- Without knowing the language type you can’t proceed.
- Suppose you are working with some foreign language, you must know the language names like Chinese, Portuguese, Japanese etc.
Step-3: Advanced Text Preprocessing
- In Advance Text Preprocessing you will do some advanced level of preprocessing work.
- Advance Text Preprocessing you use when you are building some complex big application.
- Some of the steps in Advance Text Preprocessing are:
- Parts Of Speech Tagging.
- Text Parsing.
- Core Reference Resolution.
(1) Parts Of Speech Tagging.
- Parts of Speech (POS) Tagging is a fundamental natural language processing (NLP) task that involves assigning a grammatical category or part of speech to each word in a given text.
- The primary goal of POS tagging is to identify the role that each word plays in the sentence, such as noun, verb, adjective, adverb, preposition, pronoun, etc.

(2) Text Parsing
- Parsing is the process of examining the grammatical structure and relationships inside a given sentence or text in natural language processing (NLP).
- It involves analyzing the text to determine the roles of specific words, such as nouns, verbs, and adjectives, as well as their interrelationships.

(3) Core Reference Resolution
- Core reference resolution, also known as coreference resolution, is an important task in natural language processing (NLP) that aims to identify all expressions in a text that refer to the same real-world entity or concept.
- The goal is to determine which noun phrases, pronouns, and other referring expressions in a text all point to the same underlying referent.
- Coreference resolution (CR) is the task of finding all linguistic expressions (called mentions) in a given text that refer to the same real-world entity. After finding and grouping these mentions we can resolve them by replacing, as stated above, pronouns with noun phrases.

- Core Reference means identifying the words which denotes same person or place.
- In the above example the words ‘I’, ‘My’, ‘John’ denotes the same person and ‘Trumph’ and ‘he’ denotes the same person.
Step-4: Feature Engineering
- Feature Engineering is the process of transforming raw data into a format that is more suitable for machine learning models.
- Convert the unstructured text data into a structured, numerical format that can be processed by machine learning models.
- This typically involves techniques like converting text to numerical vectors.

- In Machine Learning the columns are called the features of the Data Set.
- But in NLP you have the sentences or texts present.
- Somehow you need to convert those texts to Numbers so that the Machine can understand it.
- In case of Machine Learning models you create features based on your domain knowledge understanding.
- In case of deep learning you got the data, you preprocess it and directly pass it to the Deep Learning model. Here you don’t have to do Feature Engineering most of the time, the model will automatically extract features out of your text.
- In case of Machine Learning models as you have created features by yourself you can explain the model output by yourself. You can explain like due to which features your model has given that output.
- The Disadvantage of Machine Learning model is that to create the features by yourself you must have strong domain knowledge about that business.
- Sometimes some features that you have created will negatively affect the model performance.
- In case of Deep Learning the features are automatically generated based on my problem statement.
- You don’t have to manually create the features for your model.
- The disadvantages of the Deep Learning model is that you will not know internally which features are generated inside.
- Therefore you will not be able to explain about the model.
- For Email spam prediction if the model is saying this is a spam Email, you will not know for which words the model has classified it as a spam.
Techniques Of Feature Engineering:
- Basic Methods
- Parsing.
- PoS Tagging.
- Name Entity Recognition.
- Bag Of Words.
- One-Hot-Encoding
- Statistical Methods
- Term-Frequency, Inverse Trem Frequency.
- Advanced Methods:
- Word2Vec,
- GloVe,
- FastText,
- Skip-Thought Vectors,
- InferSent,
- Universal Sentence Encoder
- ELMo,
- BERT,
- GPT-2.
Common Techniques Of Feature Engineering:
In natural language processing (NLP), converting text data into numerical vectors is a crucial step for many machine learning models. Here are some of the most common techniques for converting text to vectors:
One-Hot Encoding: This is a simple technique where each unique word in the vocabulary is represented by a binary vector, with a 1 in the position corresponding to the word and 0s elsewhere. This approach captures the presence or absence of words but doesn’t capture any semantic relationships between them.
Bag-of-Words (BOW): In this approach, the text is represented as a vector of word frequencies, where each element in the vector corresponds to the count of a particular word in the text. This captures the importance of words but doesn’t consider the order or context of the words.
Term Frequency-Inverse Document Frequency (TF-IDF): This is a refinement of the BOW approach, where the word frequencies are weighted by the inverse of their document frequency. This helps to down weight common words that are less informative and upweight rare words that are more informative.
Word Embeddings: These are dense, low-dimensional numerical representations of words that capture semantic and syntactic relationships between them. Examples of popular word embedding techniques include Word2Vec, GloVe, and FastText.
Sentence Embeddings: These techniques represent entire sentences or paragraphs as numerical vectors, capturing the meaning and context of the text. Examples include Skip-Thought Vectors, InferSent, and Universal Sentence Encoder.
Contextual Embeddings: These are a more recent advancement in text representation, where the vector representation of a word depends on the context in which it appears. Examples include ELMo, BERT, and GPT-2.
Hybrid Approaches: Some techniques combine multiple approaches, such as using word embeddings in conjunction with other features like part-of-speech tags or named entities, to create more comprehensive text representations.
Step-5: Model Building
- The model building step in natural language processing (NLP) is a crucial part of the overall process, where the chosen machine learning or deep learning model is trained to perform a specific NLP task.
- Here are the typical steps involved in the model building process:
Data Preparation:
- Clean and preprocess the text data, such as removing stop words, handling punctuation, and converting to lowercase.
- Tokenize the text into words, phrases, or other relevant units.
- Convert the text data into numerical vector representations using techniques like one-hot encoding, bag-of-words, or word embeddings.
- Split the data into training, validation, and test sets.
Model Selection:
- Choose an appropriate model architecture based on the NLP task, such as a recurrent neural network (RNN) for sequence-to-sequence tasks, a convolutional neural network (CNN) for text classification, or a transformer-based model like BERT for various NLP tasks.
- Decide on the model’s hyperparameters, such as the number of layers, the size of the hidden layers, the learning rate, and the batch size.
Model Training:
- Train the model using the prepared training data, optimizing the model’s parameters to minimize the chosen loss function.
- Monitor the model’s performance on the validation set during training to prevent overfitting and to determine the optimal stopping point.
Model Evaluation:
- Evaluate the trained model’s performance on the held-out test set using appropriate metrics, such as accuracy, F1 score, or perplexity, depending on the NLP task.
- Analyze the model’s strengths and weaknesses, and identify areas for improvement.
Model Tuning and Optimization:
- Experiment with different model architectures, hyperparameters, and feature engineering techniques to improve the model’s performance.
- Consider ensemble methods, which combine multiple models to achieve better results.
- Employ techniques like transfer learning or domain adaptation to leverage knowledge from related tasks or datasets.
Model Deployment:
- Once the model is satisfactory, integrate it into the application or system that will use the NLP capabilities.
- Implement necessary infrastructure and monitoring to ensure the model’s reliability and performance in production.
- The specific steps and techniques used in the model-building process will depend on the NLP task, the available data, and the computational resources.
- It’s often an iterative process of experimentation and refinement to find the most effective model for a given problem.
Model Selection Methods:
- There are several approach that you can choose to solve your business use cases.
- Heuristic Approach.
- Machine Learning Algorithms.
- Deep Learning Algorithms.
- Cloud APIs.
- Which approach to use depends on two things,
- One is the Amount Of Data,
- Second is the Nature Of the Problem.
Heuristic Approach:
The heuristic approach in natural language processing (NLP) refers to the use of practical, experience-based techniques that provide reasonable, but not necessarily optimal, solutions to a problem.
Heuristic methods are often used when finding the optimal solution is not feasible or too computationally expensive.
Some examples of heuristic approaches in NLP include:
- Suppose you are doing an Email spam classifier and you have only a few Emails, Since you have few emails you can’t use ML or DL algorithms.
- In this case, you have to use the Heuristic approach.
- You found out that out of 10 Emails, 2 Emails are spam emails and are coming from the same email IDs.
- Hence you can make a rule to filter out those two spam email IDs.
Rule-based Systems: These systems use a set of predefined rules, patterns, and linguistic knowledge to process and understand natural language. For instance, a rule-based approach to named entity recognition might use a set of rules to identify and classify named entities in text, such as person names, organizations, and locations.
Greedy Algorithms: Greedy algorithms make locally optimal choices at each stage with the hope of finding a global optimum. For example, in text summarization, a greedy algorithm might select the most important sentences based on features like word frequency, position in the text, or presence of key phrases.
Heuristic Search Algorithms: These algorithms use heuristic functions to guide the search process, often by estimating the cost or distance to the goal state. For instance, in machine translation, a heuristic search algorithm might use a combination of language models and translation models to generate and evaluate candidate translations.
Approximation Algorithms: These algorithms provide approximate solutions to computationally hard problems, such as finding the optimal parse tree for a sentence in natural language parsing. Approximation algorithms can often be designed to provide guarantees on the quality of the solution, even if it’s not the optimal one.
Knowledge-Based Approaches: These approaches leverage external knowledge sources, such as ontologies, lexical databases, or common-sense reasoning systems, to address various NLP tasks. For example, a knowledge-based approach to word sense disambiguation might use a lexical database like WordNet to identify the most appropriate sense of a word in a given context.
Machine Learning Models:
- When you have quite a good amount of data you can use the Machine Learning model.
- Machine learning models are widely used in natural language processing (NLP) tasks. Here are some of the common machine learning models and their applications in NLP:
Supervised Learning Models:
- Logistic Regression: Used for text classification tasks, such as sentiment analysis, spam detection, and topic categorization.
- Support Vector Machines (SVMs): Effective for text classification, especially when dealing with high-dimensional feature spaces.
- Decision Trees and Random Forests: Applied to various NLP tasks, including text classification, named entity recognition, and semantic role labelling.
Unsupervised Learning Models:
- Clustering Algorithms (K-Means, Hierarchical Clustering): Used for document clustering, topic modelling, and word sense disambiguation.
- Latent Dirichlet Allocation (LDA): A popular topic modelling technique used for discovering hidden topics within a collection of documents.
Sequence-to-Sequence Models:
- Recurrent Neural Networks (RNNs): Used for tasks like language modelling, machine translation, and text generation.
- Long Short-Term Memory (LSTMs): A type of RNN that can effectively capture long-term dependencies in sequential data, making it suitable for tasks like machine translation and text summarization.
- Transformers: A more recent architecture, such as BERT and GPT, has shown remarkable performance on a wide range of NLP tasks, including text classification, question answering, and language generation.
Convolutional Neural Networks (CNNs):
- Effective for text classification tasks, as they can capture local patterns and features in the text.
- Used for tasks like sentiment analysis, text categorization, and document classification.
Hybrid Models:
- Combine multiple machine learning techniques to leverage the strengths of different approaches.
- Example: Using a CNN to extract local features and an LSTM to capture long-term dependencies in a text classification task.
Deep Learning Models:
- Deep learning models have become increasingly prominent in the field of natural language processing (NLP) due to their ability to learn complex representations from data and achieve state-of-the-art performance on a wide range of NLP tasks. Here are some of the commonly used deep learning models in NLP:
Recurrent Neural Networks (RNNs):
- RNNs, such as Long Short-Term Memory (LSTMs) and Gated Recurrent Units (GRUs), are well-suited for processing sequential data, such as text, and are widely used in tasks like language modeling, machine translation, and text generation.
Convolutional Neural Networks (CNNs):
- CNNs can effectively capture local patterns and features in text, making them useful for tasks like text classification, sentiment analysis, and document categorization.
Transformer Models:
- Transformers, like BERT, GPT, and T5, have revolutionized the field of NLP by introducing attention-based architectures that can capture long-range dependencies in text.
- Transformer models have shown exceptional performance on a variety of NLP tasks, including text classification, question answering, named entity recognition, and text generation.
Hybrid Models:
- Combining different deep learning architectures, such as CNNs and RNNs, can leverage the strengths of each approach and lead to improved performance on complex NLP tasks.
Generative Adversarial Networks (GANs):
- GANs have been used in NLP for tasks like text generation, style transfer, and data augmentation, where the generator model learns to produce realistic-looking text while the discriminator model learns to distinguish generated text from real text.
Memory-augmented Neural Networks:
- These models, such as Neural Turing Machines and Differentiable Neural Computers, incorporate external memory components to enhance their ability to reason, remember, and apply knowledge, making them suitable for tasks like question answering and knowledge-intensive language understanding.
Meta-learning and Few-shot Learning Models:
- These approaches aim to learn how to learn, allowing models to adapt to new tasks or domains with limited training data, which is particularly valuable in NLP where labelled data can be scarce.
- The choice of deep learning model for a specific NLP task depends on the nature of the task, the available data, the computational resources, and the desired level of interpretability.
- Increasingly, researchers and practitioners are also exploring ways to combine deep learning with other techniques, such as symbolic reasoning and knowledge-based approaches, to create more powerful and versatile NLP systems.
Cloud API Approach:
- The cloud API approach in natural language processing (NLP) refers to the use of cloud-based NLP services provided by major cloud computing platforms, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, and IBM Watson. These cloud-based NLP APIs offer a range of pre-built models and services that can be easily integrated into applications and workflows.
- Some of the key advantages of the cloud API approach in NLP include:
- Accessibility: Cloud-based NLP APIs are easily accessible and can be integrated into applications with minimal effort, allowing developers to focus on building their core functionality rather than developing NLP capabilities from scratch.
Scalability: Cloud platforms provide the necessary infrastructure and computing power to handle large-scale NLP workloads, allowing applications to scale up or down as needed.
Pre-Trained Models: Cloud-based NLP services often provide access to pre-trained models for various NLP tasks, such as text classification, named entity recognition, sentiment analysis, and language translation. This can significantly reduce the time and resources required for model training and deployment.
Ease of Use: Cloud NLP APIs typically provide intuitive and well-documented interfaces, making it easier for developers to integrate NLP capabilities into their applications.
Continuous Improvements: Cloud providers regularly update and improve their NLP services, ensuring that users have access to the latest advancements in the field.
- Some examples of popular cloud-based NLP APIs include:
- Amazon Comprehend A natural language processing service offered by AWS that provides capabilities like sentiment analysis, named entity recognition, and key phrase extraction.
- Google Cloud Natural Language API: Provides a range of NLP features, such as sentiment analysis, entity recognition, and syntax analysis.
- Microsoft Cognitive Services – Language: A suite of NLP services offered by Microsoft Azure, including text analytics, language understanding, and translation.
- IBM Watson Natural Language Understanding: Provides advanced NLP capabilities, including sentiment analysis, entity extraction, and keyword extraction.
- The cloud API approach in NLP is particularly useful for developers who need to quickly incorporate NLP capabilities into their applications without the need to build and maintain complex NLP models and infrastructure. However, it’s important to consider factors like pricing, data privacy, and the specific requirements of the application when choosing a cloud-based NLP service.
Step-6: Model Evaluation
- There are mainly two types of Evaluation done in NLP models.
- Intrinsic Evaluation.
- Extrinsic Evaluation.
- Intrinsic Evaluation is a technique using the available metrics to evaluate the model’s performance Accuracy, Precision, Recall etc.
- Extrinsic Evaluation is the approach where you do an evaluation based on real-world business scenarios.
- Evaluating the performance of natural language processing (NLP) models is a crucial step in the development and deployment of NLP systems. Here are some common approaches and metrics used for model evaluation in NLP:
Accuracy-based Metrics:
- Accuracy: The proportion of correct predictions made by the model.
- Precision, Recall, and F1-score: These metrics are often used for classification tasks, providing a balance between the model’s ability to correctly identify positive instances (precision) and its ability to identify all positive instances (recall).
Task-specific Metrics:
- Perplexity: Used for language modelling tasks, perplexity measures how well the model predicts the next word in a sequence.
- BLEU (Bilingual Evaluation Understudy): Evaluates the quality of machine-generated text, such as in machine translation or text summarization, by comparing it to reference translations.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Measures the overlap between the generated text and reference text, commonly used for text summarization evaluation.
Human Evaluation:
- In some cases, human evaluation is necessary to assess the quality, coherence, and relevance of the generated text, particularly for open-ended tasks like dialogue generation or creative writing.
Extrinsic Evaluation:
- Measuring the impact of the NLP model on the overall performance of a larger system or application, such as the improvement in customer satisfaction for a chatbot or the increase in sales for a product recommendation system.
Interpretability and Explainability:
- Evaluating the ability of the NLP model to provide insights into its decision-making process, which is particularly important in domains where model transparency is required, such as in healthcare or finance.
Generalization and Robustness:
- Assessing the model’s ability to perform well on unseen data, as well as its resilience to noise, adversarial attacks, or domain shifts.
Efficiency Metrics:
- Measuring the computational resources required by the model, such as inference time, memory usage, and model size, which are crucial for real-world deployment, especially in resource-constrained environments.
- The choice of evaluation metrics depends on the specific NLP task, the intended use case, and the trade-offs between different performance aspects, such as accuracy, interpretability, and efficiency.
- It is often necessary to use a combination of these evaluation methods to obtain a comprehensive understanding of the model’s performance and suitability for a given application.
Step-7: Model Deployment
- The model deployment step in natural language processing (NLP) is a crucial phase that involves taking a trained and evaluated NLP model and integrating it into a production environment, where it can be used to process real-world data and serve end-users or applications.
- There are three steps involved in Model Deployment,
- Model Deployment.
- Model Monitoring.
- Model Updation.
(1) Model Deployment
- The model deployment also depends on the type of application you are going to build.
- For Email Spam filtering, you just make one feature of the entire Email system, In this case, you have to create an API and deploy it in any cloud service as a microservice.
- When a new email comes the system will call an API where you have put your model and pass the email text, then your model will decide whether it is Spam or Not.
- If it is spam it will go to the spam folder or else it will go to the main folder.
- If it is a full fledge Machine Learning product you have to deploy it entirely on the cloud server.
- In this case, you have to know what your end product is, accordingly you have to deploy it.
(2) Model Monitoring
- Model monitoring is an essential part of the model deployment and maintenance process in natural language processing (NLP) and machine learning in general.
- It involves continuously tracking and evaluating the performance and behaviour of a deployed NLP model to ensure its ongoing effectiveness, reliability, and alignment with the intended use case.
- Generally, what people do, they create one dashboard to track the performance of the model.
- It will be easier for the user to see the dashboard and find out the performance of the model in real time.
- You will able to see in the graph yesterday and today’s performance.
(3) Model Updation
- Model Updation in natural language processing (NLP) refers to the process of improving or updating an existing NLP model to enhance its performance, adapt to changing data or requirements, or incorporate new capabilities.
- This process involves retraining or fine-tuning the model with additional data or modifications to the model architecture, with the goal of improving the model’s accuracy, robustness, or suitability for the target application.
- When new data comes your model must be trained on it, so that it will be able to handle the new task.
- What people do is they make the model training on the go in the server itself when new data comes and deploy it, so that you don’t have to manually train it and deploy it.