
NLP Text Preprocessing
Table Of Contents:
- Introduction.
- Lowercasing.
- Remove HTML Tags.
- Remove URLs.
- Remove Punctuation.
- Chat Word Treatment.
- Spelling Correction.
- Removing Stop Words.
- Handling Emojis.
- Tokenization.
- Stemming.
- Lemmatization.
(1) What Is NLP Text Preprocessing?
- NLP (Natural Language Processing) text preprocessing is the initial step in the NLP pipeline, where the raw text data is transformed and prepared for further analysis and processing.
- The goal of text preprocessing is to clean, normalize, and transform the text data into a format that can be effectively utilized by NLP models and algorithms.

(2) Lower Casing.
- Lowercasing is an important step in NLP text preprocessing, and it involves converting all the text in a document to lowercase. This step is typically performed as part of the initial data cleaning and normalization process.
- Here are some of the key reasons why lowercasing is a common practice in NLP:
Consistency and Normalization:
- Converting all text to lowercase helps ensure consistency in the representation of words, as uppercase and lowercase versions of the same word are typically considered distinct entities.
- This normalization step allows the NLP models to treat similar words (e.g., “the”, “The”, “THE”) as the same token, reducing the overall vocabulary size and improving the model’s ability to generalize.
Improved Performance:
- Many NLP algorithms and models, such as bag-of-words, n-grams, or word embeddings, are sensitive to the case of the text. Lowercasing can help improve the performance of these models by reducing the sparsity of the feature representations.
- For example, in a bag-of-words model, “The” and “the” would be treated as separate features without lowercasing, but with lowercasing, they would be represented by the same feature, leading to a more compact and effective representation.
Robustness to Capitalization Variations:
- Text data in the real world often exhibits inconsistent capitalization, such as proper nouns, acronyms, or text from different sources. Lowercasing helps the NLP models become more robust to these variations, as they can focus on the semantic content of the text rather than surface-level formatting differences.
Improved Generalization:
- By normalizing the text to lowercase, the NLP models can learn more general patterns and representations that are not overly dependent on specific capitalization patterns. This can lead to better generalization and performance on new, unseen data.
Compatibility with Pre-trained Models:
- Many popular pre-trained NLP models, such as BERT, GPT, or word embeddings, are trained on lowercase text. Applying lowercasing as a preprocessing step ensures compatibility with these pre-trained models, allowing for effective transfer learning and fine-tuning.
- It’s important to note that while lowercasing is a common and often beneficial preprocessing step, there may be specific NLP tasks or domains where preserving the original capitalization is crucial, such as named entity recognition or sentiment analysis on social media data.
- In such cases, the decision to apply lowercasing should be made carefully, based on the requirements of the NLP application and the characteristics of the text data.
Example Of Lower Casing:

- Here you can see that at the start of the sentence you have to write the first letter of ‘Are’ in upper case.
- But in the middle of the sentence ‘a’ is small in ‘are’.
- As Python is a case-sensitive language both ‘Are’ and ‘are’ will be considered as separate entities.
- It would be wrong to consider ‘Are’ and ‘are’ as separate entities.
- Hence we have to bring all the words in a sentence to lowercase.
Python Code:
df = pd.read_csv('IMDB_Dataset.csv')df.head()
df['review'] = df['review'].str.lower()df['review']
(3) Remove HTML Tags.
Remove HTML Tags in NLP refers to the process of removing HTML tags from text data in natural language processing (NLP) tasks. HTML tags are used to structure web pages and include elements like headings, paragraphs, links, images, and other formatting.
When working with text data scraped from the web, the HTML tags must be removed before NLP models and algorithms can effectively process the text. The presence of HTML tags can negatively impact the performance of tasks like sentiment analysis, topic modelling, named entity recognition, and text classification.
Example-1
review3 = df['review'][3]
review3
import re
def remove_html_tags(text):
pattern = re.compile('<.*?>')
return pattern.sub(r'', text)remove_html_tags(review3)
df['review'] = df['review'].apply(remove_html_tags)
df['review']
Example-2:
import re
html_pattern = '<.*?>'
def remove_html_tags(text):
return re.sub(html_pattern,'',text)
df['review'].apply(remove_html_tags)
df['review'](4) Remove URLs From Text.
- Removing URLs from text is another common preprocessing step in natural language processing (NLP) tasks.
- URLs (Uniform Resource Locators) can appear within the text data and need to be removed for many NLP applications.
Example-1:
1. Identify URLs: Use regular expressions to identify and extract URLs from the text. A common regex pattern for this purpose is:
import re
url_pattern = r'https?://\S+|www\.\S+'2. Remove URLs: Once the URLs are identified, replace them with an empty string or a placeholder value (e.g., “[URL]”) to remove them from the text.
def remove_urls(text):
return re.sub(url_pattern, '', text)
text = "Check out this website: https://example.com for more information."
cleaned_text = remove_urls(text)
print(cleaned_text)
# Output: "Check out this website: for more information."3. Handle Edge Cases: Consider additional edge cases, such as URLs within parentheses or URLs that are part of a sentence.
def remove_urls(text):
return re.sub(r'\(?\b(https?://|www[.])\S+\b\)?', '', text)
text = "Check out (https://example.com) and www.example.org for more information."
cleaned_text = remove_urls(text)
print(cleaned_text)
# Output: "Check out and for more information."Example-2:
import re
df = pd.read_csv('IMDB_Dataset.csv')
url_pattern = r'https?://\S+|www\.\S+'
def remove_urls(text):
return re.sub(url_pattern, '', text)
df['review'] = df['review'].apply(remove_urls)
df['review']
(5) Remove Punctuation
- Removing punctuation is another common preprocessing step in natural language processing (NLP) tasks.
- Punctuation marks, such as periods, commas, exclamation points, and question marks, can sometimes be considered as noise or irrelevant information for certain NLP applications.
- When we do tokenization all the punctuation marks will also be considered as a different word.
- But the punctuation marks don’t add any meaning to our sentences.
Example-1:
- We use the regular expression
[^\w\s]to match any character that is not a word character (a-z, A-Z, 0-9, _) or a whitespace character, and then replace those characters with an empty string.
import re
text = "Hello, world! This is a test."
no_punctuation = re.sub(r'[^\w\s]', '', text)
print(no_punctuation)
Example-2:
- In this example, we first import the
stringmodule, which provides a set of punctuation characters. We then use thestr.maketrans()function to create a translation table that maps each punctuation character to an empty string, effectively removing them from the text.
import string
text = "Hello, world! This is a test."
no_punctuation = text.translate(str.maketrans('', '', string.punctuation))
print(no_punctuation)Example-3:
import re
def remove_punctuation(text):
return re.sub(r'[^\w\s]', '', text)
df['review'] = df['review'].apply(remove_punctuation)
df['review']
(6) Chat Word Treatment:
- Chat word treatment in natural language processing (NLP) refers to the handling and processing of informal, colloquial, or slang language that is commonly found in conversational or chat-based text.
- Abbreviations: Shortened versions of words, such as “lol” for “laugh out loud” or “btw” for “by the way”.
- Emoticons and Emojis: Graphical representations of facial expressions or emotions, such as “:)” or “😊”.
- Repeated Characters: Repeated letters or punctuation to express emphasis or emotion, like “whooooaa” or “so cooool!!!”.
- Nonstandard Spelling: Intentional misspellings or phonetic representations of words, such as “luv” for “love” or “bday” for “birthday”.
- Slang and Idioms: Informal, context-specific language that may not follow standard grammatical rules, like “that’s lit” or “spill the tea”.
Example-1:
chat_word_dict = {
"AFAIK" : "As Far As I Know",
"AFK" : "Away From Keyboard",
"ASAP" : "As Soon As Possible",
"ATK" : "At The Keyboard",
"ATM" : "At The Moment",
"A3" : "Anytime, Anywhere, Anyplace",
"BAK" : "Back At Keyboard",
"BBL" : "Be Back Later",
"BBS" : "Be Back Soon",
"BFN" : "Bye For Now",
"B4N" : "Bye For Now",
"BRB" : "Be Right Back",
"BRT" : "Be Right There",
"BTW" : "By The Way",
"B4" : "Before",
"B4N" : "Bye For Now",
"CU" : "See You",
"CUL8R" : "See You Later",
"CYA" : "See You",
"FAQ" : "Frequently Asked Questions",
"FC" : "Fingers Crossed",
"FWIW" : "For What It's Worth",
"FYI" : "For Your Information",
"GAL" : "Get A Life",
"GG" : "Good Game",
"GN" : "Good Night",
"GMTA" : "Great Minds Think Alike",
"GR8" : "Great!",
"G9" : "Genius",
"IC" : "I See",
"ICQ" : "I Seek you",
"ILU" : "I Love You",
"IMHO" : "In My Honest/Humble Opinion",
"IMO" : "In My Opinion",
"IOW" : "In Other Words",
"IRL" : "In Real Life",
"KISS" : "Keep It Simple, Stupid",
"LDR" : "Long Distance Relationship",
"LMAO" : "Laugh My A.. Off",
"LOL" : "Laughing Out Loud",
"LTNS" : "Long Time No See",
"L8R" : "Later",
"MTE" : "My Thoughts Exactly",
"M8" : "Mate",
"NRN" : "No Reply Necessary",
"OIC" : "Oh I See",
"PITA" : "Pain In The A..",
"PRT" : "Party",
"PRW" : "Parents Are Watching",
"QPSA?" : "Que Pasa?",
"ROFL" : "Rolling On The Floor Laughing",
"ROFLOL" : "Rolling On The Floor Laughing Out Loud",
"ROTFLMAO" : "Rolling On The Floor Laughing My A.. Off",
"SK8" : "Skate",
"STATS" : "Your sex and age",
"ASL" : "Age, Sex, Location",
"THX" : "Thank You",
"TTFN" : "Ta-Ta For Now!",
"TTYL" : "Talk To You Later",
"U" : "You",
"U2" : "You Too",
"U4E" : "Yours For Ever",
"WB" : "Welcome Back",
"WTF" : "What The F...",
"WTG" : "Way To Go!",
"WUF" : "Where Are You From?",
"W8" : "Wait...",
"7K" : "Sick:-D Laugher",
"TFW" : "That feeling when",
"MFW" : "My face when",
"MRW" : "My reaction when",
"IFYP" : "I feel your pain",
"LOL" : "Laughing out loud",
"TNTL" : "Trying not to laugh",
"JK" : "Just kidding",
"IDC" : "I don’t care",
"ILY" : "I love you",
"IMU" : "I miss you",
"ADIH" : "Another day in hell",
"IDC" : "I don’t care",
"ZZZ" : "Sleeping, bored, tired",
"WYWH" : "Wish you were here",
"TIME" : "Tears in my eyes",
"BAE" : "Before anyone else",
"FIMH" : "Forever in my heart",
"BSAAW" : "Big smile and a wink",
"BWL" : "Bursting with laughter",
"LMAO" : "Laughing my a** off",
"BFF" : "Best friends forever",
"CSL" : "Can’t stop laughing"
}def chat_conversion(text):
new_text = []
for w in text.split():
if w.upper() in chat_word_dict:
new_text.append(chat_word_dict[w.upper()])
else:
new_text.append(w)
return " ".join(new_text)
chat_conversion('IMHO he is the best')
Example-2:
df = pd.read_csv('IMDB_Dataset.csv')
df['review'] = df['review'].apply(chat_conversion)
df['review'] (7) Spelling Correction
- Spelling correction in natural language processing (NLP) refers to the task of identifying and correcting misspelt words in a given text.
- This is an important task in many NLP applications, as misspelt words can negatively impact the performance of various language processing tasks, such as text classification, information retrieval, and machine translation.
Example-1:
from textblob import TextBlob
incorrect_text = "ceertain conditionas durring severell ggeneration are moodified in saame manner"
txtblb_obj = TextBlob(incorrect_text)
txtblb_obj.correct().string

Example-2: Taking Long Time
import pandas as pd
def correct_text(text):
textblb_obj = TextBlob(text)
return textblb_obj.correct().string
df = pd.read_csv('IMDB_Dataset.csv')
df['review'] = df['review'].apply(correct_text)(8) Stop Words Removal
- Stop words are high-frequency words that are generally considered to be of little or no significance for a given NLP task.
- These are words like “the”, “a”, “and”, “is”, “in”, “on”, etc. They are often removed from the text before further processing to focus on more meaningful words.
- In POS tagging we don’t remove stop words.
Why Remove Stop Words?
Removing stop words can have several benefits in NLP:
Improved Performance: By removing stop words, you can reduce the dimensionality of the feature space, which can lead to faster and more efficient text processing, especially for tasks like text classification, clustering, and information retrieval.
Focusing on Meaningful Words: Stop words generally do not carry much semantic information. Removing them allows you to focus on more meaningful words that are likely to be more informative for your NLP task.
Reducing Noise: Stop words can introduce noise and unwanted patterns in the data, which can negatively impact the performance of NLP models. Removing them can help improve the signal-to-noise ratio.
Example-1:
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stopwords.words("english")
Example-2:
import nltk
from nltk.corpus import stopwords
# Download the stop words corpus if not already downloaded
nltk.download('stopwords')
# Define the text to be processed
text = "The quick brown fox jumps over the lazy dog."
# Remove stop words
stop_words = set(stopwords.words('english'))
words = [word for word in text.split() if word.lower() not in stop_words]
cleaned_text = ' '.join(words)
print("Original text:", text)
print("Cleaned text:", cleaned_text)
Example-3:
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
def stop_words_removal(text):
stop_words = set(stopwords.words('english'))
words = [word for word in text.split() if word.lower not in stop_words]
cleanes_text = ' '.join(words)
return cleanes_text
df = pd.read_csv('IMDB_Dataset.csv')
df['review'] = df['review'].apply(stop_words_removal)
df['review']
(9) Handling Emojis
- Handling emojis in natural language processing (NLP) is an important consideration, as emojis can carry significant semantic and emotional information in text.
- Our ML algorithms can’t understand the Emojis.
- We have two options to handle Emojis.
- Option-1: Remove Emojis.
- Option-2: Replace Emojis With It’s Meaning.
Example-1: Emoji Removal
#import clean function
from cleantext import clean
#provide string with emojis
text = "I love🤩 😍 this app! 🙌 It's 😍 😍 😍 amazing 🤩😍 😍 😍 "
#print text after removing the emojis from it
print(clean(text, no_emoji=True))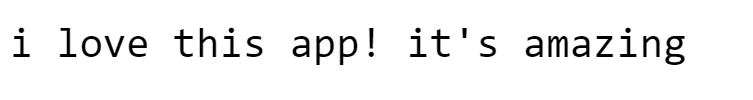
Example-2: Emoji Removal
from cleantext import clean
def remove_emoji(text):
clean_text = clean(text, no_emoji=True)
return clean_text
import pandas as pd
df = pd.read_csv('IMDB_Dataset.csv')
df['review'] = df['review'].apply(remove_emoji)
df['review'] Example-3: Replacing Emojis With Text
import emoji
emoji.demojize("I love 🤩")

Example-4: Replacing Emojis With Text

Example-5: Replacing Emojis In Entire Column
import emoji
def replace_emoji(text):
emoji_text = emoji.demojize(text)
return emoji_text
import pandas as pd
df = pd.read_csv('IMDB_Dataset.csv')
df['review'] = df['review'].apply(replace_emoji)
df['review'] 
(10) Tokenization
- Tokenization is a fundamental pre-processing step in natural language processing (NLP) where the input text is broken down into smaller, meaningful units called tokens.
- These tokens can be words, phrases, or other linguistic elements, depending on the specific requirements of the NLP task.
- Here’s a more detailed explanation of tokenization in NLP:
Word Tokenization: This is the most common form of tokenization, where the input text is split into individual words. For example, the sentence “The quick brown fox jumps over the lazy dog.” would be tokenized into the following list of words: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”].
Sentence Tokenization: In this case, the input text is split into individual sentences. This is useful for tasks that require processing text at the sentence level, such as sentiment analysis or text summarization.
N-gram Tokenization: Instead of single words, this approach creates tokens that consist of sequences of n consecutive words. For example, with n=2 (bigrams), the sentence “The quick brown fox” would be tokenized into [“The quick”, “quick brown”, “brown fox”].
Subword Tokenization: This method breaks down words into smaller meaningful units, such as morphemes or character n-grams. This can be useful for handling rare or out-of-vocabulary words, as well as for languages with complex morphology.
Why We Need Tokenization?
Text Representation: Tokenization is the first step in converting unstructured text data into a structured format that can be more easily processed by NLP algorithms and models. By breaking down the text into smaller, meaningful units (tokens), the text can be more effectively represented and manipulated.
Feature Extraction: Many NLP tasks, such as text classification, sentiment analysis, or named entity recognition, rely on the extraction of relevant features from the input text. Tokenization provides the foundation for these feature extraction processes, as the tokens can be used as basic units of analysis.
Handling Variations: Tokenization helps handle variations in language, such as different word forms, abbreviations, or compound words. By breaking down the text into tokens, the NLP system can better understand the underlying linguistic structures and patterns.
Efficient Processing: Tokenization allows for more efficient processing of large volumes of text data. By breaking down the text into smaller, manageable units, NLP models and algorithms can operate more effectively, reducing computational complexity and memory usage.
Enabling Downstream Tasks: Tokenization is often a prerequisite for many other NLP tasks, such as stop word removal, stemming, lemmatization, and part-of-speech tagging. These subsequent tasks rely on the tokenized representation of the text as their input.
Improving Model Performance: Effective tokenization can significantly improve the performance of NLP models, as it helps to capture the semantic and syntactic relationships within the text. This, in turn, can lead to better model predictions and more accurate results for the target NLP task.
Handling Special Characters: Tokenization can help handle special characters, such as punctuation, numbers, or emojis, which can play an important role in the meaning and interpretation of the text.
- By breaking down the input text into tokens, NLP systems can better understand the structure and meaning of the text, leading to more accurate and effective processing of natural language data.
- Tokenization is a fundamental and essential step in the NLP pipeline, serving as the foundation for a wide range of downstream NLP tasks and applications.
Challenges Faced In Tokenization.
- Tokenization, while a fundamental step in natural language processing (NLP), can also face several challenges that can impact the overall performance of NLP systems.
- Some of the key challenges in tokenization include:
Ambiguity: Natural language can be inherently ambiguous, and the same sequence of characters may have multiple valid tokenization possibilities. For example, the phrase “I scream, you scream, we all scream for ice cream” could be tokenized either as [“I”, “scream”, “,”, “you”, “scream”, “,”, “we”, “all”, “scream”, “for”, “ice”, “cream”] or [“I”, “scream”, “,”, “you”, “scream”, “,”, “we”, “all”, “scream”, “for”, “ice cream”].
Compound Words: Compound words, such as “ice cream” or “New York”, present a challenge for tokenization, as they may need to be treated as a single unit rather than being split into individual tokens.
Contractions and Abbreviations: Contractions (e.g., “don’t”, “can’t”) and abbreviations (e.g., “U.S.A.”, “Mr.”) can be challenging to tokenize correctly, as they may need to be split or kept as a single token depending on the context and the specific NLP task.
Multilingual and Non-Latin Scripts: Tokenization becomes more complex when dealing with text in non-Latin scripts, such as Chinese, Japanese, or Arabic, or when working with multilingual text, where the tokenization rules may differ across languages.
Handling Noise and Errors: Real-world text data can often contain various types of noise, such as spelling errors, typos, or formatting issues, which can make tokenization more challenging and potentially lead to incorrect or suboptimal tokenization.
Domain-Specific Terminology: Specialized domains, such as medicine, finance, or technology, may use domain-specific terminology, acronyms, or jargon that can be difficult to tokenize accurately without appropriate domain knowledge or custom tokenization rules.
Context Dependency: The appropriate tokenization of a piece of text may depend on the surrounding context or the specific NLP task at hand. For example, the word “bank” may need to be tokenized differently in the context of “river bank” versus “bank account”.
Example-1: Using Split Method
sent1 = "I am going to Bhubaneswar"
tokens = sent1.split()
print(tokens)
sent2 = "I am going to Bhubaneswar. I will stay there for 5 days. I will visit temples in Bhubaneswar."
tokens = sent2.split('. ')
print(tokens)Problem With Split() Method:
sent3 = "I am going to Bhubaneswar!!"
tokens = sent3.split()
print(tokens)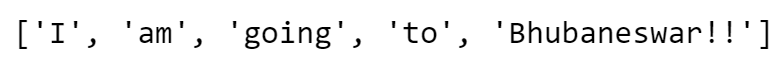
- ‘Bhubaneswar’ & ‘Bhubaneswar!!’ Will be considered as two different words !
- Split function can’t handle this type of text.
sent4 = "Where do you think I shood go? I have 3 days holiday."
tokens = sent4.split('. ')
print(tokens)
- Here we have 2 sentences but the split function does not work because of the question mark.
Example-2: Using NLTK
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize, sent_tokenizesent1 = "I am going to Bhubaneswar!!"
sent2 = "I have a Ph.D in A.I"
sent3 = "We're here to help! mail us at hello@gmail.com"
sent4 = "A 5km ride cost $10.10"print(word_tokenize(sent1))
print(word_tokenize(sent2))
print(word_tokenize(sent3))
print(word_tokenize(sent4))
- Here it failed to tokenize properly, the word “We’re” has been splitted as two words which is incorrect.
- The email id hello@gmail.com has been splitted as different words.
Example-3: Using Spacy
pip install spacy
python -m spacy download en_core_web_smimport spacy
nlp = spacy.load('en_core_web_sm')doc1 = nlp(sent1)
doc2 = nlp(sent2)
doc3 = nlp(sent3)
doc4 = nlp(sent4)print([token.text for token in doc1])
print([token.text for token in doc2])
print([token.text for token in doc3])
print([token.text for token in doc4])
- Here the ‘Spacy’ library also failed for the word “We’re”.
- It has split into two different words which is incorrect.
Example-:4 Tokenize Entire Column
import spacy
nlp = spacy.load('en_core_web_sm')
def word_tokenize(text):
doc = nlp(text)
tokens = [token.text for token in doc]
return tokensimport pandas as pd
df = pd.read_csv('IMDB_Dataset.csv')
df['review_tokens'] = df['review'].apply(word_tokenize)df.head()
(11) Stemming
- Stemming is a fundamental text preprocessing technique used in natural language processing (NLP) that involves reducing words to their base or root form, known as the stem even if the stem itself is not a valid word in the language.
- The primary purpose of stemming is to simplify and reduce the dimensionality of the text data, which can improve the performance of various NLP tasks.
- The process of stemming involves removing the suffixes (e.g., -s, -es, -ing, -ed) from words to obtain their base or root form. For example, the words “connect,” “connected,” “connecting,” and “connection” would all be reduced to the stem “connect.”
Advantages Of Stemming:
Reduced Vocabulary: Stemming helps to reduce the number of unique words (vocabulary size) by mapping different word forms to a common stem. This can be particularly useful for tasks like text classification, where a smaller vocabulary can lead to better generalization and faster processing.
Improved Recall: By reducing words to their stems, stemming can help improve the recall of information retrieval systems, as documents containing different forms of the same word (e.g., “run,” “running,” “ran”) can be identified as relevant to a query.
Language Dependency: Stemming algorithms are typically language-specific, as the rules for forming suffixes and roots can vary significantly across different languages. Common stemming algorithms include the Porter Stemmer, the Snowball Stemmer, and the Lancaster Stemmer.
Limitations: While stemming can be effective in many cases, it can also have limitations. Aggressive stemming can sometimes lead to the loss of semantic information, resulting in words being mapped to the wrong stem or overgeneralization. This can potentially impact the performance of certain NLP tasks.
Alternatives: An alternative to stemming is lemmatization, which aims to transform words into their dictionary form (known as the lemma) based on their part-of-speech and meaning. Lemmatization is generally more sophisticated than stemming and can provide better semantic preservation.
- Stemming is often used as a preprocessing step in various NLP applications, such as:
- Information retrieval
- Text classification
- Sentiment analysis
- Topic modeling
- Named entity recognition
- By reducing words to their stems, stemming can help to improve the efficiency and effectiveness of NLP models by reducing the dimensionality of the input data and capturing the underlying linguistic relationships between words.
Example-1: Using Different Stemmer Algorithms
- In Python, there are several libraries and tools available for performing stemming. Here are some of the most commonly used ones:
- NLTK provides various stemming algorithms, including the
- Porter Stemmer,
- Snowball Stemmer,
- Lancaster Stemmer.
from nltk.stem.porter import PorterStemmer
from nltk.stem.snowball import SnowballStemmer
from nltk.stem.lancaster import LancasterStemmerporter = PorterStemmer()
snowball = SnowballStemmer("english")
lancaster = LancasterStemmer()words = ["connect", "connected", "connecting", "connection"]
print('Porter Stemmer')
for word in words:
print(word, "->" , porter.stem(word))
words = ["walk", "walks", "walking", "walked"]
print('Snowball Stemmer')
for word in words:
print(word, "->" , snowball.stem(word))
words = ["eat", "eats", "eating", "ate"]
print('Lancaster Stemmer')
for word in words:
print(word, "->" , lancaster.stem(word))
Example-2: Stemming To A Data Frame Column.
import pandas as pd
from nltk.stem.porter import PorterStemmer
# Create a sample DataFrame
df = pd.DataFrame({'text': ['unflinching ', 'viewing', 'darker', 'agreements']})
# Create a Porter Stemmer
stemmer = PorterStemmer()
# Define a function to apply stemming to a single element
def stem_text(text):
return stemmer.stem(text)
# Apply the stemming function to the 'text' column
df['stemmed_text'] = df['text'].apply(stem_text)
print(df)
Example-3: Apply Stemming To Entire Column!!
import pandas as pd
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
df = pd.read_csv('IMDB_Dataset.csv', nrows=5)
df['review_tokens'] = df['review'].apply(word_tokenize)
df['stemmed_tokens'] = df['review_tokens'].apply(lambda x: [stemmer.stem(y) for y in x])
df
(12) Lemmatization
- Lemmatization is a more advanced natural language processing (NLP) technique than stemming, and it is used to transform words into their base or dictionary form, known as the lemma.
- Lemmatization unlike Stemming, reduces the inflected words properly ensuring that the root word belongs to the language.
Example-1: Using NLTK’s WordNetLemmatizer:
import nltk
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('runs'))
print(lemmatizer.lemmatize('better','a'))
print(lemmatizer.lemmatize('mice'))
print(lemmatizer.lemmatize('geese'))
Example-2: Applying Lemmatization To Entire Column Using NLTK
import pandas as pd
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
df = pd.read_csv('IMDB_Dataset.csv', nrows=5)
df['review_tokens'] = df['review'].apply(word_tokenize)
df['lematize_tokens'] = df['review_tokens'].apply(lambda x: [lemmatizer.lemmatize(y,'a') for y in x])
df
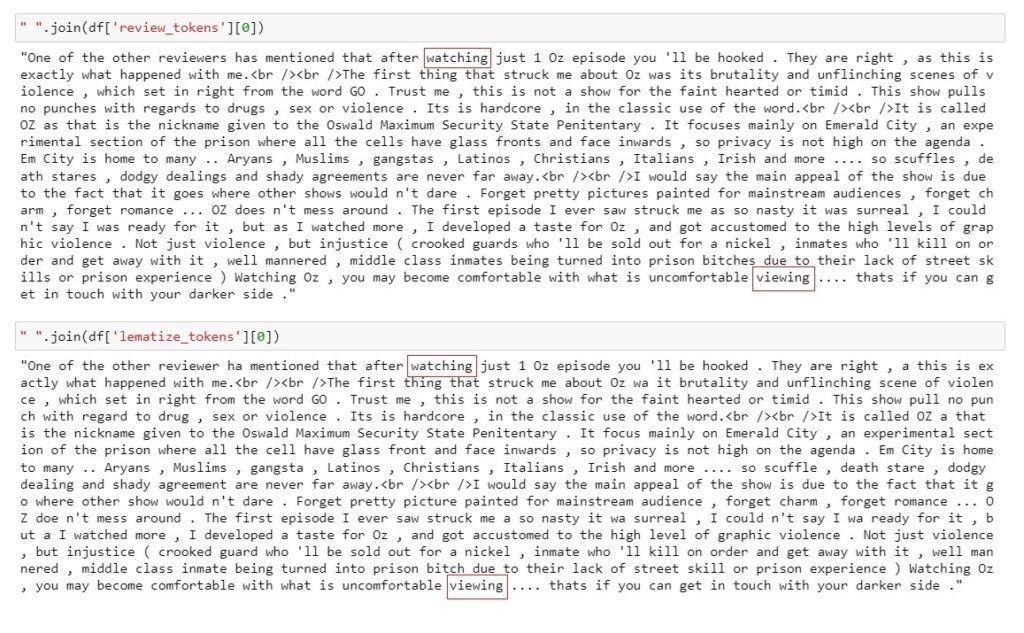
- You can see that NLTK lemmatization is failing in some cases.
Example-3: Applying Lemmatization To Entire Column Using Spacy
import pandas as pd
import spacy
nlp = spacy.load("en_core_web_sm")
df = pd.read_csv('IMDB_Dataset.csv', nrows=5)
df['review_tokens'] = df['review'].apply(word_tokenize)
df['lematize_tokens'] = df['review'].apply(lambda x: [y.lemma_ for y in nlp(x)])
df
