One Hot Encoding
Table Of Contents:
- What Is One Hot Encoding?
- What Is Categorical Text Data?
- Example Of One Hot Encoding.
- Pros & Cons Of One Hot Encoding.
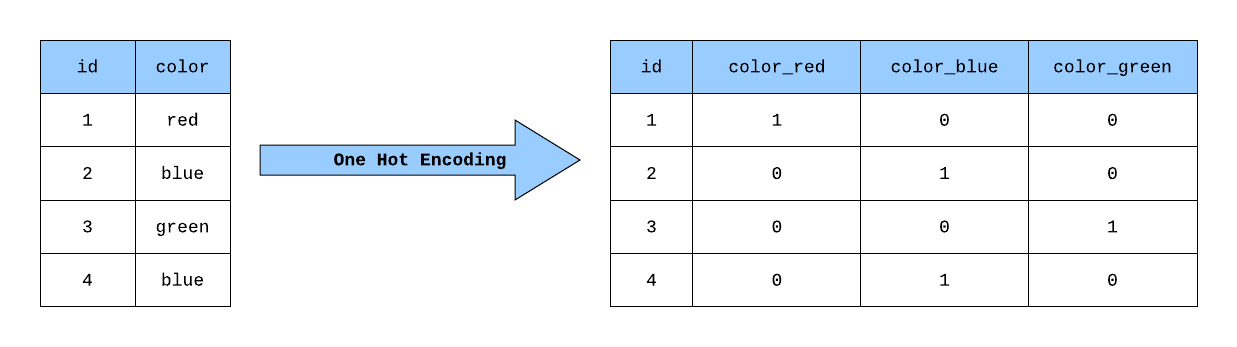
(1) What Is One Hot Encoding?
- One-hot encoding is a feature extraction technique commonly used in Natural Language Processing (NLP) to represent categorical text data in a numerical format.
- It is a simple yet effective method for encoding categorical variables, including words, into a format that machine learning algorithms can use.
- Categorical text data refers to text data that can be divided into distinct categories or classes, where each piece of text belongs to one or more of these categories.
- Classifying text documents into predefined categories such as topic (e.g., “politics”, “sports”, “technology”), sentiment (e.g., “positive”, “negative”, “neutral”), or genre (e.g., “news article”, “blog post”, “product review”).

(2) What Is Categorical Text Data ?
- Categorical text data refers to text data that can be divided into distinct categories or classes, where each piece of text belongs to one or more of these categories.
- Classifying text documents into predefined categories such as topic (e.g., “politics”, “sports”, “technology”), sentiment (e.g., “positive”, “negative”, “neutral”), or genre (e.g., “news article”, “blog post”, “product review”).

(3) Example Of One Hot Encoding.
- Suppose we have the below dataset with us.
- Let us do the one-hot encoding on it.
Dataset:

Corpus:

Vocabulary:

- Vocabulary Count = 5
- As V = 5, we need to convert each word of the document into a ‘V’ dimensional vector.
One Hot Encoding:

Word Representation:

Sentence Representation:

(4) Pros & Cons Of One Hot Encoding.
- Suppose we have the below dataset with us.
- Let us do the one-hot encoding on it.
Pros of One-Hot Encoding:
Simplicity: One-hot encoding is a straightforward and easy-to-implement method for encoding categorical text data into a numerical format.
Preserving Categorical Information: By representing each unique word or token as a separate binary feature, one-hot encoding preserves the categorical nature of the text data, avoiding any loss of information.
Compatibility with Machine Learning Algorithms: Many traditional machine learning algorithms, such as logistic regression, decision trees, and support vector machines, require numerical input data. One-hot encoding transforms the text data into a format that can be directly used by these algorithms.
Interpretability: The one-hot encoded features are easily interpretable, as each feature corresponds to a specific word or token in the vocabulary.
Handling Unseen Data: One-hot encoding can handle unseen words or tokens during prediction or inference, by simply assigning a zero value to the corresponding feature.
Cons of One-Hot Encoding:
High Dimensionality: The size of the one-hot encoded vector is equal to the size of the vocabulary, which can be very large for large text datasets. This can lead to high-dimensional feature spaces, which can be computationally expensive and may require more data to train effective models.
Sparsity: The one-hot encoded vectors are typically very sparse, with most elements being zero. This sparsity can lead to inefficient storage and computation, especially for large vocabularies.
Lack of Semantic Relationships: One-hot encoding does not capture any semantic or contextual relationships between the words, as each word is represented independently.
Susceptibility to Overfitting: The high-dimensional feature space created by one-hot encoding can make the model more prone to overfitting, especially when the dataset is small.
Limited Generalization: One-hot encoding does not generalize well to new, unseen words or tokens that were not present in the training data, as it cannot capture their semantic or contextual relationships.
Out Of Vocabulary: If a new word comes during the prediction it will not be present in our vocabulary hence we can’t get the one hot encoded value for it.
- Fixed Training Size: ML models will work on a fixed input size data set. That means you can’t pass variable-length input text to our ML models as we have trained with a fixed input length dataset, while in the prediction if some different length text comes our ML model can’t handle it.
- To address the limitations of one-hot encoding, more advanced feature extraction techniques, such as word embeddings (e.g., word2vec, GloVe, or BERT), have been developed in NLP.
- These methods can capture the semantic and contextual relationships between words, leading to more efficient and informative feature representations.