
Optimization Algorithms For Neural Networks
Table Of Contents:
- What Is An Optimization Algorithm?
Gradient Descent Variants:
- Batch Gradient Descent (BGD)
- Stochastic Gradient Descent (SGD)
- Mini-Batch Gradient Descent
- Convergence analysis and trade-offs
- Learning rate selection and scheduling
Adaptive Learning Rate Methods:
- AdaGrad
- RMSProp
- Adam (Adaptive Moment Estimation)
- Comparisons and performance analysis
- Hyperparameter tuning for adaptive learning rate methods
Momentum-Based Methods:
- Momentum
- Nesterov Accelerated Gradient (NAG)
- Advantages and limitations of momentum methods
- Momentum variants and improvements
Second-Order Methods:
- Newton’s Method
- Quasi-Newton Methods (e.g., BFGS, L-BFGS)
- Hessian matrix and its computation
- Pros and cons of second-order methods in deep learning
Optimization Challenges and Techniques:
- Vanishing and exploding gradients
- Weight initialization strategies
- Batch normalization and its impact on optimization
- Gradient clipping to mitigate exploding gradients
- Regularization techniques (e.g., weight decay, dropout) and their effects on optimization
Optimization for Specific Network Architectures:
Convolutional Neural Networks (CNNs):
- Convolutional operations and their optimization
- Pooling operations and their impact on optimization
- Optimizing CNN architectures and hyperparameters
Recurrent Neural Networks (RNNs):
- Backpropagation Through Time (BPTT)
- Long Short-Term Memory (LSTM) optimization
- Gated Recurrent Units (GRUs) and optimization challenges
Parallel and Distributed Optimization:
- Parallelization techniques for optimization in deep learning
- Distributed training strategies and algorithms
- Communication overhead and synchronization challenges
Optimization Libraries and Frameworks:
- TensorFlow’s Optimizers
- PyTorch’s Optimizers
- Keras’ Optimizers
- Comparison of optimization libraries and their features.
(1) What Is An Optimization Algorithm?
- In deep learning, an optimization algorithm refers to a specific algorithm or method used to train deep neural networks by iteratively adjusting the network’s parameters to minimize a defined loss function.
- The optimization process aims to find the optimal set of parameters that results in the best performance of the neural network on a given task, such as image classification or natural language processing.
- In the context of deep learning, optimization algorithms typically rely on the concept of gradient descent, which involves computing the gradients of the loss function with respect to the network parameters and updating the parameters in the direction opposite to the gradients to minimize the loss. The goal is to iteratively refine the parameters until convergence or until a certain stopping criterion is met.
(2) Why We Need Optimization ?
- Optimization is essential in deep learning for several reasons:
Minimizing Loss: The primary goal of optimization in deep learning is to minimize the loss function. The loss function quantifies the discrepancy between the predicted outputs of the neural network and the true values. By minimizing the loss, we aim to improve the model’s ability to make accurate predictions.
Model Training: Deep learning models typically have a large number of parameters, which makes training them computationally expensive. Optimization algorithms iteratively update the parameters based on the gradients of the loss function, allowing the model to learn from the data and improve its performance. Without optimization, it would be challenging to train complex neural networks effectively.
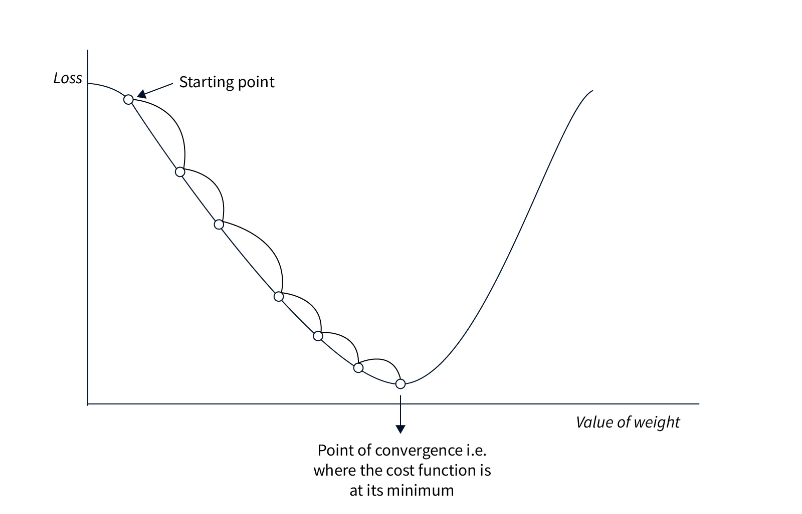
Convergence to Optimal Solution: Optimization algorithms guide the model’s parameters towards the optimal solution that minimizes the loss function. The optimization process involves iteratively adjusting the parameters based on the gradients to descend the loss landscape. This allows the model to converge to a point where the loss is minimized, resulting in a better-performing model.
Generalization: Deep learning models aim to generalize well to unseen data, meaning they should perform well on new, unseen examples beyond the training set. Optimization helps prevent overfitting, where the model becomes too specialized to the training data and performs poorly on new data. By minimizing the loss function during training, optimization algorithms help the model learn patterns and representations that generalize well.
Hyperparameter Tuning: Deep learning models often have hyperparameters, such as learning rate, batch size, and regularization strength, which need to be carefully selected. Optimization algorithms provide insights into how these hyperparameters affect the training process and the model’s performance. By analyzing the learning curves and monitoring the loss during training, one can adjust the hyperparameters to achieve better results.
- In summary, optimization is crucial in deep learning to train models effectively, minimize the loss function, converge to an optimal solution, generalize well to unseen data, and fine-tune hyperparameters. It enables deep neural networks to learn from data and improve their performance on various tasks, such as image classification, natural language processing, and speech recognition.