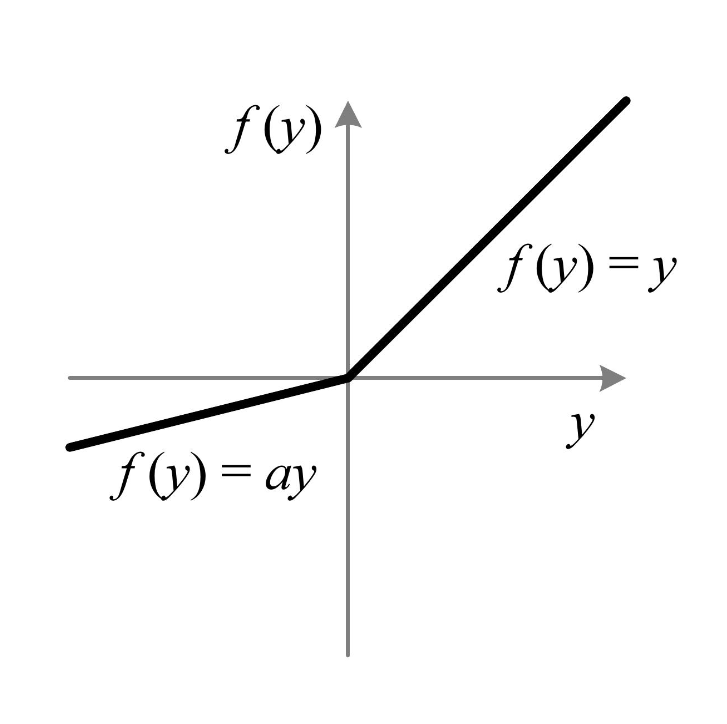
Parametric ReLU (PReLU) Activation Function
Table Of Contents:
- What Is Parametric ReLU (PReLU) Activation Function?
- Formula & Diagram For Parametric ReLU (PReLU) Activation Function.
- Where To Use Parametric ReLU (PReLU) Activation Function?
- Advantages & Disadvantages Of Parametric ReLU (PReLU) Activation Function.
(1) What Is Parametric ReLU (PReLU) Activation Function?
- The Parametric ReLU (PReLU) activation function is an extension of the standard ReLU (Rectified Linear Unit) function that introduces learnable parameters to control the slope of the function for both positive and negative inputs.
- Unlike the ReLU and Leaky ReLU, which have fixed slopes, the PReLU allows the slope to be adjusted during training, enabling the network to learn the optimal activation behavior.
- Parametric ReLU or PReLU uses
 as a hyperparameter that the model learns during the training process.
as a hyperparameter that the model learns during the training process.

- During training, the value of the parameter a is updated through backpropagation and gradient descent, allowing the network to learn the most appropriate slope for negative inputs.
- If a is set to 0, the PReLU reduces to the standard ReLU function. By allowing a to take non-zero values, the PReLU provides a more flexible activation function that adapts to the data and learns different slopes for positive and negative inputs.
(2) Formula & Diagram For Parametric ReLU (PReLU) Activation Function.
Formula:


Diagram:
(3) Where To Use Parametric ReLU (PReLU) Activation Function?
- The Parametric ReLU (PReLU) activation function can be used in various scenarios, particularly in deep neural networks, where it offers advantages over the standard ReLU and other activation functions.
- Here are some situations where the PReLU is commonly applied:
Deep Neural Networks: The PReLU is often used in deep neural networks, especially when the network architecture consists of many layers. Deep networks can benefit from the adaptive activation behavior of the PReLU, as it allows the network to learn different slopes for positive and negative inputs, improving its representational power and learning capacity.
Complex and Varying Activation Patterns: In datasets with complex and varying activation patterns, the PReLU can adapt to different characteristics by learning the appropriate slope for positive and negative inputs. This flexibility enables the network to capture and model intricate relationships, potentially leading to improved performance on challenging tasks.
Addressing the Dying ReLU Problem: The PReLU, like the Leaky ReLU, helps alleviate the dying ReLU problem by introducing a non-zero slope for negative inputs. This property prevents neurons from becoming permanently inactive, enabling potential recovery and learning of previously “dead” neurons during training.
Networks with Sparse Activation: In some cases, ReLU neurons can exhibit overly sparse activation, where they are inactive for the majority of the input space. The PReLU’s adaptability allows it to encourage more active neurons and a richer representation of the data, addressing the issue of sparsity and potentially improving the network’s capacity to capture important features.
- It’s important to note that the choice of activation function, including whether to use the PReLU, depends on the specific problem, data characteristics, and network architecture.
- While the PReLU offers advantages over the standard ReLU, other activation functions like sigmoid, tanh, or different variants of the ReLU family (e.g., Leaky ReLU, Exponential Linear Units) should also be considered and compared based on their performance on the task at hand.
- Experimentation and empirical evaluation are typically necessary to determine the optimal activation function for a given problem.
(4) Advantages & Disadvantages Of Parametric ReLU (PReLU) Activation Function.
Advantages Of Parametric ReLU (PReLU) Activation Function:
Adaptive Activation Behavior: One of the key advantages of the PReLU is its ability to adaptively learn different slopes for positive and negative inputs. This adaptability allows the network to capture varying activation patterns in the data, potentially improving the model’s representational power and learning capacity.
Prevention of Dead Neurons: Similar to the Leaky ReLU, the PReLU helps address the dying ReLU problem by introducing a non-zero slope for negative inputs. This property ensures that neurons do not become permanently inactive, enabling potential recovery and learning of previously “dead” neurons during training.
Improved Gradient Flow: The PReLU retains the non-zero gradient for negative inputs, similar to the Leaky ReLU. This property helps mitigate the vanishing gradient problem, promoting more stable and effective training in deep neural networks. It allows for better information flow and facilitates learning in deep architectures.
Disadvantages Of Parametric ReLU (PReLU) Activation Function:
Increased Model Complexity: The PReLU introduces additional learnable parameters, which increase the complexity of the model. Each PReLU unit requires its own parameter to be learned during training, adding computational overhead and potentially increasing the risk of overfitting, especially when dealing with limited data.
More Difficult Parameter Tuning: The additional parameters in the PReLU require careful tuning during training. Determining the optimal slopes for positive and negative inputs can be challenging, and an inappropriate choice of these parameters may result in suboptimal performance or convergence issues.
Risk of Overfitting: When using the PReLU, there is an increased risk of overfitting the training data due to the additional parameters. Regularization techniques, such as weight decay or dropout, may need to be employed to mitigate this risk and improve generalization.
Computational Cost: The PReLU involves additional computations compared to simpler activation functions like ReLU or Leaky ReLU. Although the computational overhead is relatively low, it can accumulate in large-scale networks and affect the overall training and inference time.
- It’s important to consider the trade-offs and carefully evaluate the advantages and disadvantages of the PReLU activation function in the specific context of the problem, dataset, and network architecture. While the PReLU offers benefits such as adaptability and prevention of dead neurons, it also introduces complexities and risks that need to be managed effectively.
- Proper regularization and parameter tuning techniques are crucial to harness the potential advantages of the PReLU while mitigating its disadvantages.