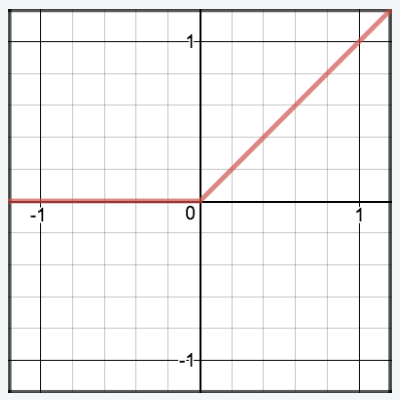
Rectified Linear Unit (ReLU) Activation:
Table Of Contents:
- What Is Rectified Linear Unit (ReLU) Activation?
- Formula & Diagram For Rectified Linear Unit (ReLU) Activation.
- Where To Use Rectified Linear Unit (ReLU) Activation?
- Advantages & Disadvantages Of Rectified Linear Unit (ReLU) Activation.
(1) What Is Rectified Linear Unit (ReLU) Activation?
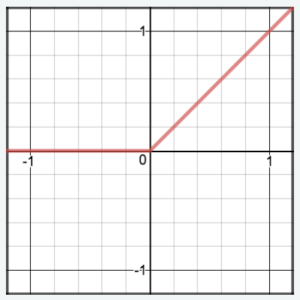
- Returns the input if it is positive; otherwise, outputs zero.
- Simple and computationally efficient.
- Popular in deep neural networks due to its ability to alleviate the vanishing gradient problem.
(2) Formula & Diagram For Rectified Linear Unit (ReLU) Activation.
Formula:
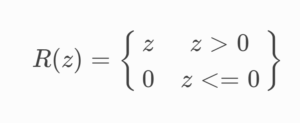
Diagram:
(3) Where To Use Rectified Linear Unit (ReLU) Activation.
Hidden Layers of Deep Neural Networks: ReLU activations are often employed in the hidden layers of deep neural networks. ReLU provides a simple and computationally efficient non-linearity by setting negative inputs to zero and leaving positive inputs unchanged. This sparsity-inducing property allows networks to learn sparse representations and promotes efficient computation during both forward and backward passes.
Addressing Vanishing Gradients: ReLU activations help mitigate the vanishing gradient problem, which can occur during backpropagation in deep networks. Since ReLU does not saturate for positive inputs, it allows gradients to flow more easily through the network, facilitating efficient training and convergence. By preventing the vanishing gradient problem, ReLU activations enable the training of deeper architectures.
Image and Computer Vision Tasks: ReLU activations have shown excellent performance in image and computer vision tasks. Convolutional neural networks (CNNs) leverage ReLU activations after convolutional and pooling layers to introduce non-linearity and learn complex hierarchical representations of images. The sparsity-inducing nature of ReLU helps in capturing edges and other image features effectively.
Natural Language Processing (NLP): ReLU activations are also employed in certain NLP tasks, such as text classification or sentiment analysis. In neural network architectures like recurrent neural networks (RNNs) or long short-term memory (LSTM) networks, ReLU activations can be used in the hidden layers to introduce non-linearity and model complex linguistic relationships.
Fast Training: ReLU activations allow for faster training compared to other activation functions, such as sigmoid or tanh, due to their computational efficiency and non-saturating nature. The absence of exponential functions in ReLU computations speeds up forward and backward passes, making it an attractive choice for large-scale deep learning models.
(4) Advantages & Disadvantages Of Rectified Linear Unit (ReLU) Activation.
Advantages Of Rectified Linear Unit (ReLU) Activation .
- Sparsity: Sparsity arises when a ≤ 0. Sigmoids on the other hand are always likely to generate some non-zero value resulting in dense representations. The more such units that exist in a layer the sparser the resulting representation. Sparse representations seem to be more beneficial than dense representations.
- ReLU has the ability to produce sparse outputs, meaning that most of the activations are 0. This is useful because it reduces the number of parameters in the model, and therefore reduces overfitting.
- Avoiding the Vanishing Gradient Problem: ReLU can help to avoid the vanishing gradient problem, which is a common issue in deep neural networks. The vanishing gradient problem occurs when the gradients of the weights become too small during the backward propagation step, making it difficult for the optimizer to update the weights.
- The constant gradient of ReLUs (when the input is positive) allows for faster learning compared to sigmoid activation functions where the gradient becomes increasingly small as the absolute value of x increases. This results in more efficient training of deep neural networks and has been one of the key factors in the recent advances in deep learning.
- Non-linearity: Non-linear activation functions are necessary to learn complex, non-linear relationships between inputs and outputs.
- Computational Efficiency: ReLU is computationally efficient and requires only a threshold operation, which is much faster than other activation functions like sigmoid or hyperbolic tangent.
- Speed of Convergence: ReLU speeds up the convergence of neural networks, compared to other activation functions. This is because the gradient of ReLU is either 0 or 1, which makes it easier for the optimizer to make rapid updates.
Drawbacks Of Rectified Linear Unit (ReLU) Activation .
The main issue with ReLU is that all the negative values become zero immediately, which decreases the ability of the model to fit or train from the data properly.
That means any negative input given to the ReLU activation function turns the value into zero immediately in the graph, which in turn affects the resulting graph by not mapping the negative values appropriately.
- The ReLU activation function can result in “dead neurons” during training, where the activation value becomes 0 and remains 0 for all future inputs. This means that the corresponding weights will never be updated, effectively rendering the neuron useless.
- Unbounded Outputs: ReLU has unbounded outputs, meaning that the activation can become very large, which can cause numeric instability and make the network difficult to train.
- Non-Differentiability: ReLU is not differentiable at 0, which means that the gradient of the function is undefined at this point. This can make optimization difficult and slow down convergence. Also, we talked about it in the previous section.
- Unsuitability for Certain Data Distributions: ReLU may not be suitable for data that has a large number of negative values, as it can produce a large number of “dead neurons.” In this case, alternative activation functions may use for it.
(5) What Is Dead ReLU Problem ?
What Is Dead ReLU ?
- The “dead ReLU” problem refers to a situation where ReLU (Rectified Linear Unit) neurons in a neural network become permanently inactive and do not activate or update their weights during training. When the weights of a ReLU neuron are adjusted in such a way that the output is always negative, the neuron effectively “dies” and remains unresponsive to any input or gradient updates.
Why Dead ReLU Occurs?
(1) High Learning Rate
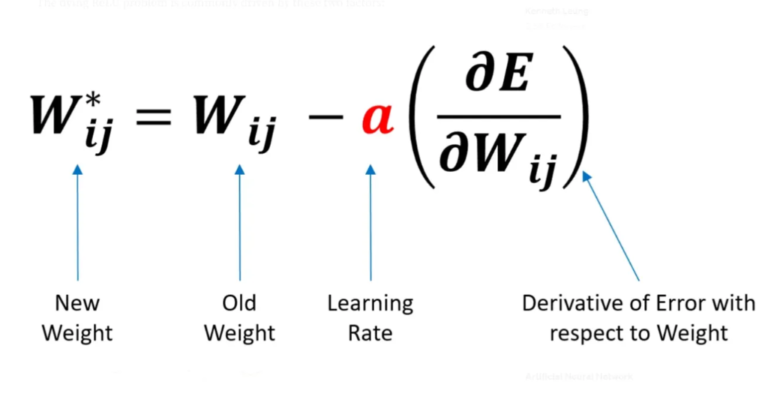
- If our learning rate (α) is set too high, there is a significant chance that our new weights will end up in the highly negative value range since our old weights will be subtracted by a large number. These negative weights result in negative inputs for ReLU, thereby causing the dying ReLU problem to happen.
(2)Large Negative Bias
Large negative bias refers to a situation where the bias term in the ReLU activation function is set to a very negative value. This has the effect of essentially “killing” the ReLU units, as they will always output 0 regardless of the input.
This can occur when the weights in a neural network are initialized with large negative values, or when the learning process has caused the bias term to shift to a large negative value. In either case, this can result in a phenomenon known as the “dying ReLU” problem, where many or most of the ReLU units in the network are no longer active and are unable to contribute to the overall computation.
Initialization: If the weights of a ReLU neuron are initialized in a way that consistently leads to negative outputs, the neuron may become inactive from the beginning of training. For example, using a weight initialization method that sets all weights to a negative value can cause this issue.
Large Learning Rates: In some cases, using a large learning rate during training can cause the weights of a ReLU neuron to be updated in such a way that the neuron’s output becomes consistently negative. This can lead to the neuron becoming “dead” and unresponsive to subsequent updates.
Unbalanced Data or Incorrect Labels: When dealing with imbalanced datasets or incorrect labels, ReLU neurons can end up learning to always produce negative outputs, resulting in dead ReLUs. If the majority of the training examples correspond to a specific class or have incorrect labels, the ReLU neurons associated with other classes may become inactive.
Solution To Dead ReLU .
The presence of dead ReLU neurons can have detrimental effects on the performance and learning capacity of a neural network. Since the dead neurons do not contribute to the learning process, they effectively reduce the model’s capacity and may lead to underfitting or limited representational power.
To mitigate the dead ReLU problem, several modifications to the ReLU activation function have been proposed. One common approach is to use variants such as Leaky ReLU, Parametric ReLU (PReLU), or Exponential Linear Units (ELU), which introduce small slopes or non-zero outputs for negative inputs. These modifications help prevent the complete inactivation of neurons and allow for the possibility of recovery and learning.
- It’s worth noting that the dead ReLU problem is more prevalent in deeper networks where the vanishing gradient problem can occur. Shallower networks or networks with skip connections (e.g., residual connections) tend to be less affected by the dead ReLU problem.