
Recurrent Neural Network
Table Of Contents:
- What Are Recurrent Neural Networks?
- The Architecture of a Traditional RNN.
- Types Of Recurrent Neural Networks.
- How Does Recurrent Neural Networks Work?
- Common Activation Functions.
- Advantages And Disadvantages of RNN.
- Recurrent Neural Network Vs Feedforward Neural Network.
- Backpropagation Through Time (BPTT).
- Two Issues Of Standard RNNs.
- RNN Applications.
- Sequence Generation.
- Sequence Classification.
(1) What Is Recurrent Neural Network?
- Recurrent Neural Network(RNN) is a type of Neural Network where the output from the previous step is fed as input to the current step. In traditional neural networks, all the inputs and outputs are independent of each other.
- Still, in cases when it is required to predict the next word of a sentence, the previous words are required and hence there is a need to remember the previous words.

- Thus RNN came into existence, which solved this issue with the help of a Hidden Layer. The main and most important feature of RNN is its Hidden state, which remembers some information about a sequence. The state is also referred to as Memory State since it remembers the previous input to the network.
- It uses the same parameters for each input as it performs the same task on all the inputs or hidden layers to produce the output. This reduces the complexity of parameters, unlike other neural networks.
(2) The Architecture Of RNN.
- The architecture of a Recurrent Neural Network (RNN) is designed to process sequential data by incorporating feedback connections that allow information to be passed from one step to the next.
- RNNs have a recurrent or cyclic structure that enables them to maintain an internal memory to process sequences of varying lengths.
- Here’s an overview of the basic architecture of an RNN:

Input Layer: The input layer receives the sequential data as input. Each element of the sequence is typically represented as a feature vector or embedding.
Hidden Layer: The hidden layer(s) of an RNN play a crucial role in capturing and maintaining the sequential information. It consists of recurrent connections that allow information to be passed from one step to the next within the sequence. The hidden layer maintains a hidden state or memory that is updated at each time step.
Recurrent Connections: The recurrent connections in an RNN enable the hidden layer to process the sequential data. At each time step, the hidden state is updated based on the current input and the previous hidden state. This allows the RNN to capture dependencies and patterns across different time steps.
Activation Function: An activation function is applied to the output of the hidden layer to introduce non-linearity into the RNN. Common activation functions used in RNNs include sigmoid, tanh, or ReLU (Rectified Linear Unit).
Output Layer: The output layer produces the desired output based on the information captured by the hidden layer. The specific structure of the output layer depends on the task being performed, such as sequence classification or sequence generation.
Feedback Connections: In addition to the recurrent connections within the hidden layer, RNNs also have feedback connections that allow gradients to flow through time during the training process. These feedback connections enable the use of backpropagation through time (BPTT) algorithm for training the RNN.
Training Parameters: RNNs have trainable parameters, including weights and biases, which are adjusted during the training process using optimization algorithms like gradient descent. The goal is to minimize the difference between the predicted output and the true output.
Note:
- It is important to note that the basic RNN architecture can suffer from the vanishing gradient problem, where gradients diminish exponentially over time, making it difficult to capture long-term dependencies. To address this issue, more sophisticated RNN architectures have been developed, such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), which incorporate additional mechanisms to selectively retain and update information over time.
- LSTM and GRU architectures maintain internal memory cells and gating mechanisms that help alleviate the vanishing gradient problem and enable RNNs to capture long-term dependencies more effectively.
- Overall, the architecture of an RNN allows it to process sequential data by maintaining an internal hidden state and capturing dependencies across different time steps. This makes RNNs well-suited for tasks involving sequential information, such as natural language processing, speech recognition, machine translation, and time series analysis.
(3) How RNN Solves Issues With ANN?
- The two big issues with ANN are:
- It discarded the sequential information.
- Long-term dependency is not captured.
- Capture Sequential Information:‘
- RNN captures sequential information by introducing the concept of time steps.
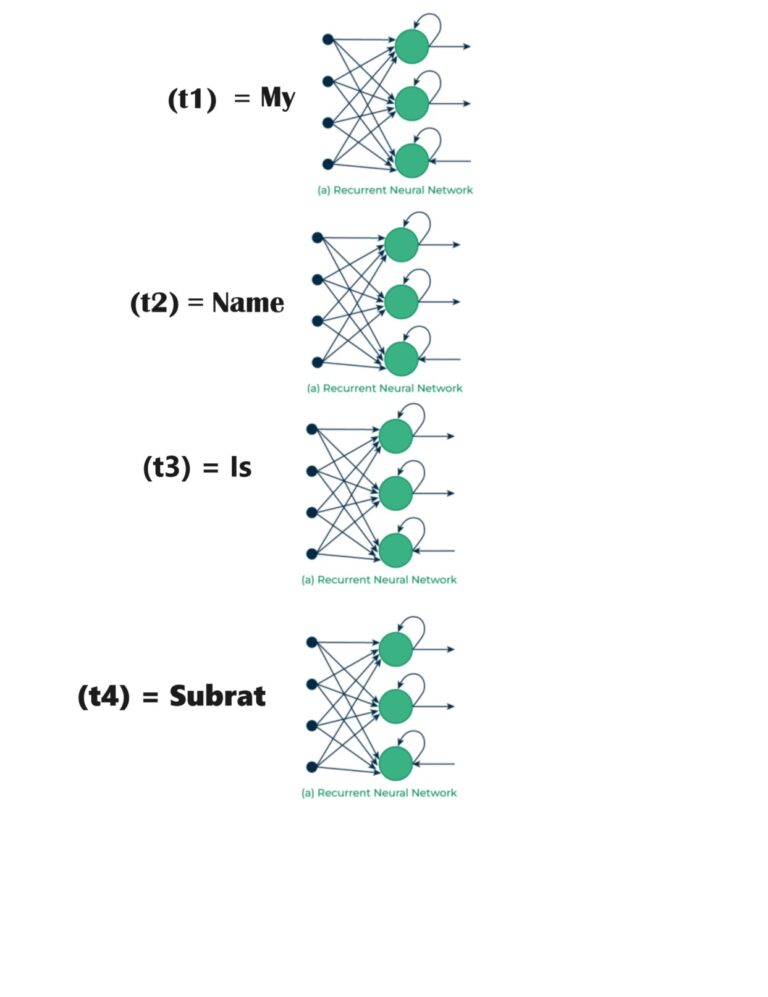
- Suppose I have a sentence, “My Name Is Subrat”,
- Here we have 4 words. Hence we will create 4 time steps, t1, t2, t3, t4.
- In the first time step word ‘My’ will enter into the network.
- Subsequent words will be processed in t2, t3, t4 time steps.
- Like this, we are capturing the sequential information of the sentence.
- Capture Long-Term Dependency:
- As we have a feedback loop in the recurrent neural network, the previous inputs will be given back to the network again.
- Hence we are capturing the previous dependencies in the neural network.

(4) Types Of Recurrent Neural Network.
- There are four types of RNNs based on the number of inputs and outputs in the network.
- One to One
- One to Many
- Many to One
- Many to Many
One To One:
- This type of RNN behaves the same as any simple Neural Network it is also known as Vanilla Neural Network.
- In this Neural Network, there is only one input and one output.

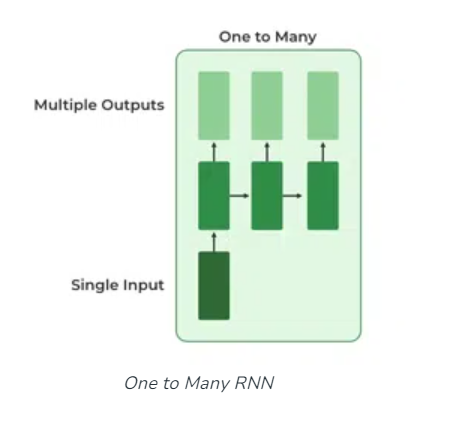
One To Many:
- In this type of RNN, there is one input and many outputs associated with it.
- One of the most used examples of this network is Image captioning where given an image we predict a sentence having Multiple words.
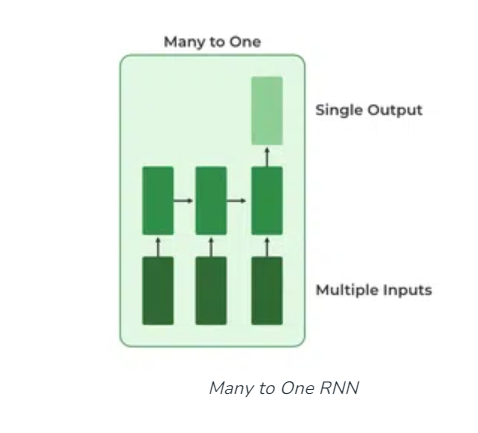
Many to One:
- In this type of network, Many inputs are fed to the network at several states of the network generating only one output.
- This type of network is used in problems like sentimental analysis.
- Where we give multiple words as input and predict only the sentiment of the sentence as output.
Many to Many:
- In this type of neural network, there are multiple inputs and multiple outputs corresponding to a problem.
- One Example of this Problem will be language translation.
- In language translation, we provide multiple words from one language as input and predict multiple words from the second language as output.

(5) How Does Recurrent Neural Network Works?
- Recurrent Neural Networks (RNNs) are a type of neural network that are specifically designed to handle sequential data.
- They can process and make predictions based on the order and context of the input data.
- RNNs are widely used in various applications such as speech recognition, machine translation, and natural language processing.
- Here is a step-by-step explanation of how Recurrent Neural Networks work:

Sequential Data Handling: RNNs are designed to handle sequential data, where the order of the data points matters. Examples of sequential data include sentences, time series data, and DNA sequences.
Recurrent Connections: Unlike feedforward neural networks, RNNs have recurrent connections that allow information to flow not only from the input layer to the output layer but also in a loop, where information from previous time steps is fed back into the network.
Memory Cells: RNNs have memory cells, also known as hidden states or memory states, which store information about the previous inputs. These memory cells enable the network to retain information from the past and use it to make predictions in the future.
Time Steps: RNNs process sequential data one time step at a time. At each time step, the network takes an input and updates its hidden state based on the current input and the previous hidden state.
Weight Sharing: RNNs share the same set of weights across all time steps. This weight sharing allows the network to learn patterns and dependencies in the sequential data.
Training: RNNs are trained using a technique called backpropagation through time (BPTT). BPTT is an extension of the backpropagation algorithm used in feedforward neural networks. It calculates the gradients of the loss function with respect to the weights and updates the weights accordingly.
Vanishing Gradient Problem: One challenge in training RNNs is the vanishing gradient problem. It occurs when the gradients become extremely small as they are backpropagated through time, making it difficult for the network to learn long-term dependencies. To address this issue, variants of RNNs such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) were developed. These variants use gating mechanisms to selectively retain and update information in the memory cells, allowing them to capture long-term dependencies more effectively.
(6) What Is A Memory Cell?
- Cells that are a function of inputs from previous time steps are also known as memory cells.
- Unlike feed-forward neural networks, RNNs can use their internal state (memory) to process sequences of inputs.
- In other neural networks, all the inputs are independent of each other.
- But in RNN, all the inputs are related to each other.
(7) Why It Is Said Recurrent Neural Network?
- It is called “Recurrent” because the same neural network is used multiple times with different input values.

- In RNN we will consider pack of Neurons.
- We call it as a RNN unit.
- A RNN unit can consist of ‘n’ number of neurons.

- In the above example the RNN unit consist of ’32’ number of Neurons.
- input_shape = (50,1)
- (50,1) = [time_step, input_feature]
- Here 50 = Number of words in a sentence, it is also understood as 50 number of time steps from t1 to t50.
- 1 = single word entered at a time.
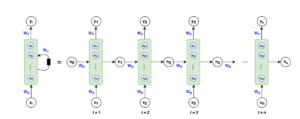
- It is said as “Recurrent” because the same neural network unit of “32” neurons is used 50 times to process an input sentence of 50 words.
- The same weights and biases are used while processing 50 number of words in a sentence.
- RNNs are “recurrent” because they recurrently apply the same operation to a sequence of inputs, using the output from one time step as input to the next time step.
- This allows the network to maintain a “memory” of the past inputs and to use this information to inform its predictions or decisions.
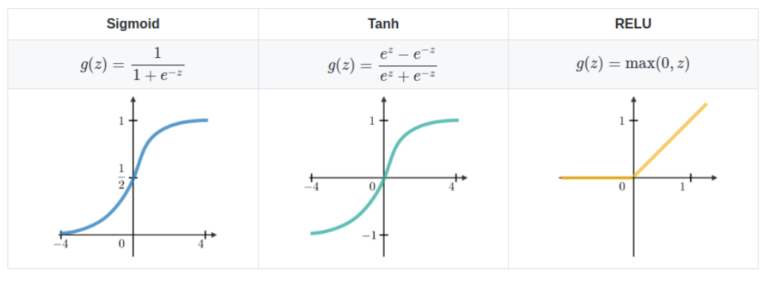
(8) Common Activation Functions Used In RNN.
- A neuron’s activation function dictates whether it should be turned on or off.
- Nonlinear functions usually transform a neuron’s output to a number between 0 and 1 or -1 and 1.
(9) Backpropagation Through Time (BPTT).
- In RNN the neural network is in an ordered fashion and since in the ordered network each variable is computed one at a time in a specified order like first h1 then h2 then h3 so on.
- Hence we will apply backpropagation throughout all these hidden time states sequentially.

- In a traditional feedforward neural network, backpropagation updates the weights based on the error at the output layer.
- However, in RNNs, where the hidden state is updated at each time step, backpropagation needs to consider the temporal dependencies between the hidden states.
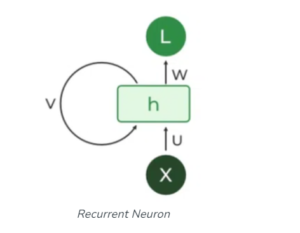
Mathematically:

- Suppose consider the above RNN network.
- Where Xt = Input at time step ‘t’
- ht = Hidden state output at time step ‘t’.
