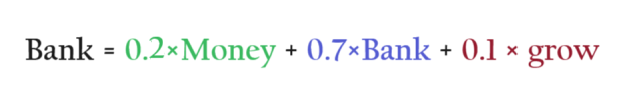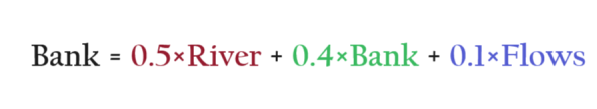In 2024 we all know that there is a technology called ‘GenAI’ has penetrated into the market.
With this technology we can create different new images, videos, texts from scratch automatically.
The center of ‘GenAI’ technology is the ‘Transformers’.
And the center of the Transformer is the ‘Self Attention’.
Hence we need to understand ‘Self Attention’ better to understand others.
(2) Problem With Word Embedding.
The problem with the word embedding is that it doesn’t capture the contextual meaning of the word.
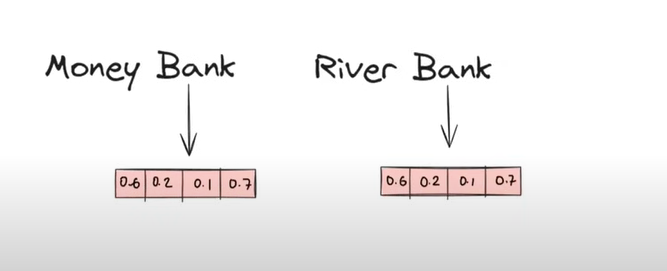
In the above example, we can see that the meaning of ‘Bank’ is different in different sentences.
But if we are using a word embedding technique the vector representation [0.6, 0.2, 0.1, 0.7] is the same for the word ‘Bank’, which is wrong.
Hence we need to come up with a new technique that will capture the contextual meaning of the word.
(3) What Is Contextual Word Embedding ?
Based on the words before and after we need to derive the meaning of the word.
In the above example ‘River Bank’, the meaning of the word ‘Bank’ will be derived by using its previous and after words, in this case using the word ‘River’.
In case of ‘Money Bank’ , meaning of Bank will be derived from the word ‘Money’.
(4) How Does Self Attention Works?
Step-1: The first step is to calculate the static word embedding of the words by using the “Word2Vec” or “glove” technique.
Step-2: The second step is to pass the static embeddings into an “Self Attention” model.
Step-3: Finally get the Dynamic Contextual Embedding of the words.
(5) Let Us Create The Self Attention
In the above example, we can see that the word ‘Bank’ is being used in different contexts.
Unfortunately, if we use word embedding the meaning of ‘Bank’ will be the same in both of the sentences.
We need to change the meaning of ‘Bank’ based on the context around the world.
If I write the Bank embedding as the weighted sum of the words around it, I can capture the context meaning of the word ‘Bank’.
Because I am taking account of all the surrounding words of the ‘Bank’.
The numbers [0.2, 0.7, 0.1] represent word similarity.
‘Bank’ is 0.2 per cent similar to the word ‘Money’.
We can also write the ‘Bank’ equation for the second sentence as above.
Note:
Automatically the meaning of ‘Bank’ will come as different in both of the sentences.
It also depends on the context of words.
Cont..
Let us write each word as the combination of its context words.
If you focus on the word ‘Bank’ the LHS part is the same but the RHS is different now.
The computer can’t understand the words hence we need to convert each word in the sentence to a vector format.
All these numbers on the RHS side represent the similarity between the words.
So the next question will be how to calculate the similarity between words.
How To Calculate Similarity Between Words?
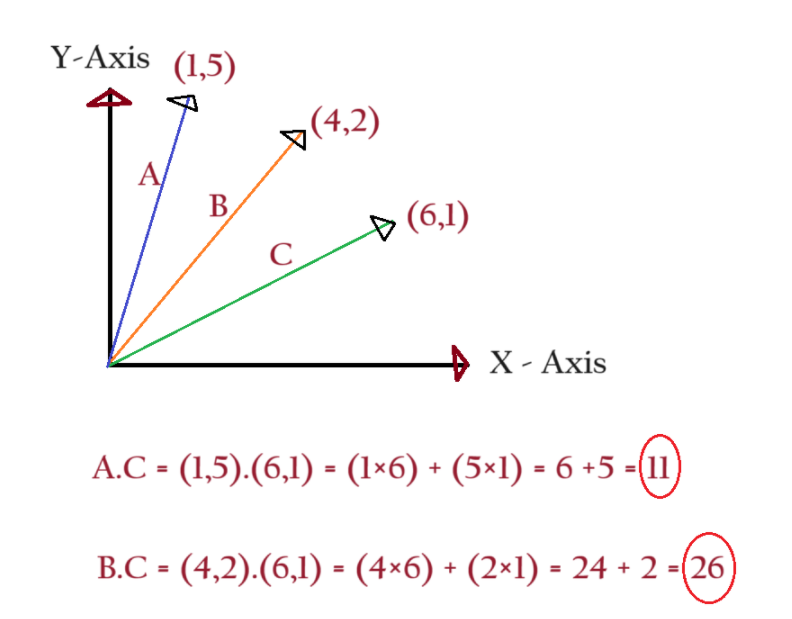
The best way to calculate the similarity between words is to calculate the dot product between two vectors.
First, represent the words in vector format and determine the dot product between the two.
The dot product of two vectors will be a scalar quantity.
The dot product of the ‘B’ & ‘C’ vector is 26 and ‘A’ and ‘C’ is 11.
Hence vectors ‘B’ and ‘C’ are more similar compared to ‘A’ and ‘C’.
Hence the numbers in the equation represent the similarity between words.
We can also write the equation for the new embedding as below.