
Vanishing & Exploding Gradient
Table Of Contents:
- Vanishing & Exploding Gradient.
- What Is Vanishing Gradient?
- What Is Exploding Gradient?
- Solution To Vanishing & Exploding Gradient.
(1) Vanishing & Exploding Gradient
- The vanishing and exploding gradient problems are common challenges in training recurrent neural networks (RNNs).
- These problems occur when the gradients used to update the network’s parameters during training become either too small (vanishing gradients) or too large (exploding gradients).
- This can hinder the convergence of the training process and affect the performance of the RNN model.
(2) Vanishing Gradient
During backpropagation, the calculation of (partial) derivatives/gradients in the weight update formula follows the Chain Rule, where gradients in earlier layers are the multiplication of gradients of later layers:

- As the gradients frequently become SMALLER until they are close to zero, the new model weights (of the initial layers) will be virtually identical to the old weights without any updates.
- As a result, the gradient descent algorithm never converges to the optimal solution. This is known as the problem of vanishing gradients, and it’s one example of the unstable behaviours of neural nets.
(3) Why Vanishing Gradient Problem Happens?

- Taking the derivative w.r.t. the parameter x, we get:
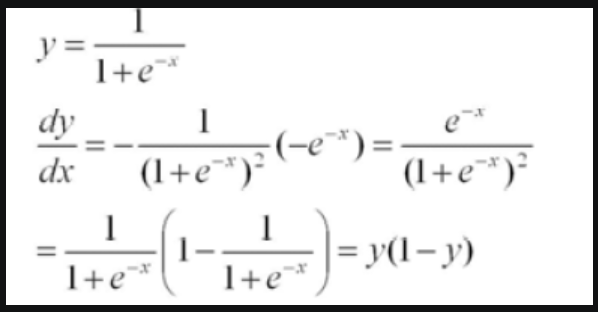
- and if we visualize the Sigmoid function and its derivative:

- We can see that the Sigmoid function squeezes our input space into a range between [0,1], and when the inputs become fairly small or fairly large, this function saturates at 0 or 1.
- These regions are referred to as ‘saturating regions’, whose derivatives become extremely close to zero.
- The same applies to the Tanh function that saturates at -1 and 1.
- Suppose that we have inputs that lie in any of the saturating regions, we would essentially have no gradient values to propagate back, leading to a zero update in earlier layer weights.
- Usually, this is no big of a concern for shallow networks with just a couple of layers, however, when we add more layers, vanishing gradients in initial layers will result in model training or convergence failure.
- This is due to the effect of multiplying n of these small numbers to compute gradients of the early layers in an n-layer network, meaning that the gradient decreases exponentially with n while the early layers train very slowly and thus the performance of the entire network degrades.
(3) Exploding Gradient
- In contrast to vanishing gradients, the exploding gradients problem occurs when the gradients become larger and larger as they propagate through the layers of the RNN.
- This can cause very large weight updates and lead to the gradient descent diverging [1].
- The exploding gradients problem is often observed when the initial weights assigned to the network generate a large loss, resulting in large gradients that cause unstable updates to the network weights
Moving on to the exploding gradients, in a nutshell, this problem is due to the initial weights assigned to the neural nets creating large losses.
Big gradient values can accumulate to the point where large parameter updates are observed, causing gradient descents to oscillate without coming to global minima.
What’s even worse is that these parameters can be so large that they overflow and return NaN values that cannot be updated anymore.
(4) Why Exploding Gradient Occurs?
- The issue of exploding gradients arises when, during backpropagation, the derivatives or slopes of the neural network’s layers grow progressively larger as we move backward. This is essentially the opposite of the vanishing gradient problem.
- On the other hand, if we keep on multiplying the gradient with a number larger than one. The gradient keeps increasing and can become so large that it makes our network unstable. Sometimes, the parameters can become so large that they result in NaN values. NaN stands for not a number. It represents undefined values.
- The root cause of this problem lies in the weights of the network, rather than the choice of activation function.
- High weight values lead to correspondingly high derivatives, causing significant deviations in new weight values from the previous ones.
- As a result, the gradient fails to converge and can lead to the network oscillating around local minima, making it challenging to reach the global minimum point.
(5) How To Identify A Vanishing Or Exploding Gradients Problem?
- Acknowledging that the gradients’ issues are something we need to avoid or fix when they do happen, how should we know that a model is suffering from vanishing or exploding gradients issues? Following are the few signs.
Vanishing Gradient:
- Large changes are observed in the parameters of later layers, whereas parameters of earlier layers change slightly or stay unchanged
- In some cases, weights of earlier layers can become 0 as the training goes
- The model learns slowly and often times, training stops after a few iterations
- Model performance is poor
Exploding Gradient:
- Contrary to the vanishing scenario, exploding gradients shows itself as unstable, large parameter changes from batch/iteration to batch/iteration
- Model weights can become NaN very quickly
- Model loss also goes to NaN
(5) How Can We Solve Vanishing Or Exploding Gradients Problem?
Using Less Number Of Layers:
- A straightforward approach to solving vanishing and exploding gradient problems is to use less number of layers in our network.
- Using fewer layers will ensure that the gradient is not multiplied too many times.
- This may stop the gradient from vanishing or exploding, but it does cost us the ability of our network to understand complex features.
Careful Weight Initialization:
- We can solve both of these problems partially by carefully choosing our model parameters initially
Using The Correct Activation Functions:
Saturating functions such as sigmoid saturate the larger inputs and cause a vanishing gradient problem.
We can use non-saturating activation functions such as ReLU and its alternatives.
An example of such a non-saturating activation function is leaky ReLU.

Using Batch Normalization:
- This technique normalizes the activations within each mini-batch, effectively scaling the gradients and reducing their variance.
- This helps prevent both vanishing and exploding gradients, improving stability and efficiency.
Gradient Clipping:
- It is a popular method used to solve the exploding gradient problem.
- It limits the size of the gradients so that they never exceed some specified value.

- It sets a maximum threshold for the magnitude of gradients during backpropagation.
- Any gradient exceeding the threshold is clipped to the threshold value, preventing it from growing unbounded.