Underfitting vs Overfitting
Table Of Contents:
- What is Generalization
- What is Underfitting
- What is Overfitting
- How To Detect Underfitting
- How To Avoid Underfitting
- How To Detect Overfitting
- How To Prevent Overfitting
- Model Prone To Underfitting
(1) What Is Generalization?
- In supervised learning, the main goal is to use training data to build a model that will be able to make accurate predictions based on new, unseen data, which has the same characteristics as the initial training set.
- This is known as generalization. Generalization relates to how effectively the concepts learned by a machine learning model apply to particular examples that were not used throughout the training.
- You want to create a model that can generalize as precisely as possible. However, in the real world, this is a tricky problem.
Advantages Of Generalized Model
Robustness to Noise: The model is less sensitive to noise or irrelevant variations in the training data. It focuses on the essential patterns and relationships and avoids being influenced by random fluctuations.
Ability to Handle Variations: The model can handle variations in the input data, such as different feature values, different data distributions, or new examples from the same problem domain. It can adapt and make accurate predictions even when the new data exhibits slight differences from the training data.
Transfer Learning: The model can transfer the knowledge learned from one task or domain to another related task or domain. It can leverage the learned representations and patterns to make predictions on new, but related, problem instances.
Consistency and Stability: The model produces consistent and stable predictions when presented with slightly perturbed or different versions of the same input. It exhibits similar behaviour across different runs or subsets of the data.
How To Achieve Generalized Model ?
High-Quality and Diverse Training Data: Start with a high-quality and diverse training dataset that represents the variations and complexities present in the real-world problem you are trying to solve. Ensure that the dataset covers a wide range of instances and captures different scenarios and edge cases. The more representative and diverse the training data, the better the chances of your model generalizing well.
Data Preprocessing and Cleaning: Perform thorough data preprocessing and cleaning to handle missing values, outliers, and noisy data. Data preprocessing techniques such as normalization, scaling, and handling categorical variables can help prepare the data for training. Removing irrelevant or redundant features and addressing class imbalance if applicable can also improve generalization.
Split Data into Training and Test Sets: Split your dataset into separate training and test sets. The training set is used for model training, while the test set is used to evaluate the model’s performance on unseen data. The test set should be representative of the real-world scenarios your model will encounter. Typically, a random split, such as an 80-20 or 70-30 split, is used, but other techniques like cross-validation can also be employed.
Cross-Validation: Implement cross-validation techniques, such as k-fold cross-validation, to assess the model’s performance across multiple train-test splits of the data. Cross-validation provides a more robust estimate of the model’s generalization performance by evaluating it on different subsets of the data. It helps detect any potential issues related to overfitting or poor generalization.
Regularization Techniques: Regularization methods, such as L1 or L2 regularization, can help control the complexity of the model and prevent overfitting. Regularization adds a penalty term to the model’s objective function, discouraging excessively complex models and promoting better generalization.
Hyperparameter Tuning: Properly tune the hyperparameters of your model to find the optimal configuration for generalization. Hyperparameters, such as learning rate, regularization strength, or the number of layers in a neural network, can significantly impact the model’s performance. Techniques like grid search or random search can be used to explore different hyperparameter combinations and identify the ones that yield the best generalization performance.
Model Evaluation on Test Set: Evaluate the performance of your model on the test set, which contains unseen data. Assess metrics such as accuracy, precision, recall, or mean squared error, depending on the problem type, to determine how well your model generalizes. Avoid tuning the model based on the test set performance to prevent overfitting to the test set.
Model Validation on New Data: Once your model has performed well on the test set, it is essential to validate its performance on new, unseen data. This can be achieved by collecting additional data or using a separate validation dataset. Assessing the model’s performance on new data helps provide a realistic evaluation of its generalization ability.
Regular Monitoring and Retraining: Continuously monitor the performance of your model in real-world scenarios and retrain it periodically as new data becomes available. This helps ensure that the model continues to generalize well over time and adapts to changes in the problem domain.
What Is Generalization Error?
- Generalization error, also known as generalization loss or out-of-sample error, refers to the difference in performance between a machine learning model’s predictions on the training data and its predictions on new, unseen data.
- It measures how well a trained model can generalize its learned patterns and relationships to make accurate predictions on instances it has not encountered during training.
- The generalization error is a critical metric to evaluate the effectiveness and reliability of a model. It provides insights into how well the model is likely to perform in real-world scenarios where it will encounter data it has not seen before.
- A low generalization error indicates that the model is able to capture the underlying patterns and generalize well to unseen instances, while a high generalization error suggests that the model may be overfitting or underfitting the training data.
A model’s generalization error (also known as a prediction error) can be expressed as the sum of three very different errors: Bias error, variance error, and irreducible error.
Note: The irreducible error occurs due to the noisiness of the data itself. The only way to reduce this part of the error is to clean up the data (e.g., fix the data sources, such as broken sensors, or detect and remove outliers).
(2) What Is Underfitting?
- Underfitting occurs when a model is not able to make accurate predictions based on training data and hence, doesn’t have the capacity to generalize well on new data.
- Another case of underfitting is when a model is not able to learn enough from training data (Figure 2), making it difficult to capture the dominating trend (the model is unable to create a mapping between the input and the target variable).
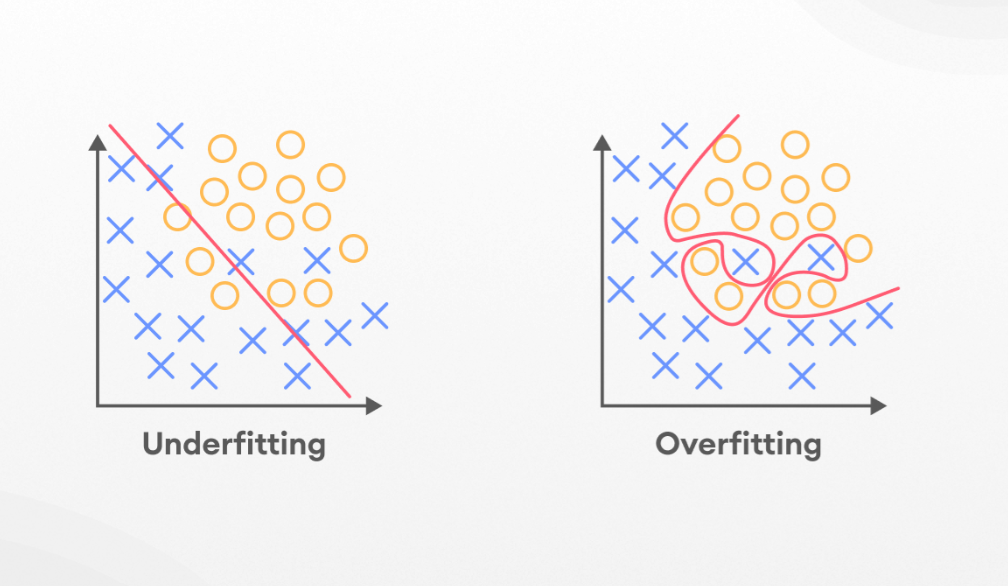
- Machine learning models with underfitting tend to have poor performance both in training and testing sets (like the child who learned only addition and was not able to solve problems related to other basic arithmetic operations both from his math problem book and during the math exam).
- Underfitting models usually have high bias and low variance.
(4) How To Detect Underfitting?
- Here are some indicators that can help you detect underfitting:
Low Training and Test Accuracy: An underfit model tends to have low accuracy or performance on both the training data and the test data. The model fails to learn the patterns in the training data and therefore cannot generalize well to new instances.
High Bias, Low Variance: An underfit model typically exhibits high bias because it oversimplifies the underlying patterns, leading to inadequate performance. Additionally, it has low variance because it is not sensitive to the noise or specific instances in the training data.
Poorly Fitting Decision Boundaries: In classification problems, an underfit model may create decision boundaries that are overly simple and fail to capture the complexities and variations in the data. It may result in inaccurate or overly generalized predictions.
Suboptimal Model Complexity: If the model is too simple or lacks the capacity to represent the underlying patterns in the data, it is likely to underfit. For example, using a linear model for a highly nonlinear problem can lead to underfitting.
(5) How To Overcome Underfitting?
- To address underfitting, you can consider the following steps:
Increase Model Complexity: If you suspect underfitting, consider using a more complex model that has a higher capacity to capture the patterns in the data. For example, using a deep neural network instead of a linear model can provide greater flexibility.
Feature Engineering: Analyze the features in your dataset and consider adding more relevant features or transforming existing features to better represent the underlying patterns. Feature engineering can enhance the model’s ability to capture complex relationships.
Hyperparameter Tuning: Adjusting the hyperparameters of the model can help improve its performance. For example, increasing the number of layers or nodes in a neural network, adjusting the learning rate, or modifying the regularization strength can affect the model’s complexity and generalization ability.
Increase Training Data: Providing more training data can help the model learn the underlying patterns more effectively. A larger and more diverse dataset can enhance the model’s ability to generalize.
Ensemble Methods: Using ensemble methods, such as combining multiple models (e.g., bagging or boosting), can help improve performance by leveraging the strengths of different models.
(6) Models Prone To Underfitting.
- Certain types of models are more prone to underfitting due to their inherent simplicity or limitations. Here are a few examples:
Linear Models: Linear models, such as linear regression or logistic regression, have a straightforward and linear relationship between the input features and the output. They may struggle to capture complex nonlinear patterns in the data and can underfit when faced with highly nonlinear problems.
Shallow Neural Networks: Neural networks with a small number of layers and nodes are considered shallow networks. These networks have limited capacity to learn complex relationships and may underfit when dealing with intricate or high-dimensional data.
Models with Insufficient Parameters: If a model has too few parameters relative to the complexity of the underlying patterns in the data, it may not have the capacity to capture the nuances and variations. This can lead to underfitting.
Oversimplified Decision Trees: Decision trees, when grown with limited depth or few splits, can become overly simplistic and fail to capture the intricate decision boundaries present in the data. This can result in underfitting.
Naive Bayes Classifier: Naive Bayes classifiers assume that the features are conditionally independent given the class label. Although they are computationally efficient and work well in some cases, they can underfit when the independence assumption is violated or when there are complex dependencies among the features.
- It’s important to note that underfitting is not limited to these specific models and can occur with any model if its complexity or capacity is insufficient to capture the underlying patterns in the data.
- Addressing underfitting may involve using more complex models, increasing model capacity, incorporating more relevant features, or adjusting hyperparameters to improve performance and capture the desired patterns.
(7) What Is Overfitting?
- A model is considered overfitting when it does extremely well on training data but fails to perform on the same level on the validation data (like the child who memorized every math problem in the problem book and would struggle when facing problems from anywhere else).
- An overfitting model fails to generalize well, as it learns the noise and patterns of the training data to the point where it negatively impacts the performance of the model on new data (figure 3). If the model is overfitting, even a slight change in the output data will cause the model to change significantly.
- Models that are overfitting usually have low bias and high variance.
- When a model overfits, it essentially memorizes the training data, including the noise and specific instances, rather than learning the general patterns that would enable it to make accurate predictions on new data.
- As a result, the model becomes too sensitive to the idiosyncrasies of the training data and fails to capture the broader patterns that would allow it to generalize well.
(8) How To Detect Overfitting?
- Here are some indicators that can help you detect Overfitting:
High Training Accuracy, Low Test Accuracy: The model achieves high accuracy or performance on the training data but performs poorly on the test data. This discrepancy indicates that the model is not generalizing well and is instead memorizing the training examples.
Overly Complex Model: An overfit model tends to have many parameters or features relative to the size of the training dataset. It becomes excessively intricate to capture even small variations or noise in the data, making it less likely to generalize to new instances.
Overly Flexible Decision Boundaries: In classification problems, an overfit model may create decision boundaries that excessively conform to the training data, resulting in convoluted and intricate boundaries that are driven by specific instances rather than the underlying patterns.
High Variance, Low Bias: An overfit model typically exhibits low bias because it fits the training data very closely. However, it has high variance because it is sensitive to the noise and specific instances in the training data, leading to inconsistent predictions when presented with new data.
(9) How To Overcome Overfitting?
- To address overfitting, you can consider the following steps:
Regularization: Regularization techniques like L1 or L2 regularization can be employed to add a penalty to the model’s objective function, discouraging overly complex models and promoting better generalization.
Cross-Validation: Cross-validation techniques, such as k-fold cross-validation, can help assess the model’s performance on multiple train-test splits of the data, providing a more robust estimate of its generalization ability.
Feature Selection: Removing irrelevant or redundant features can help simplify the model and prevent it from overfitting to noisy or irrelevant data.
Early Stopping: Monitoring the model’s performance on a validation set during training and stopping the training process when the performance starts to degrade can prevent the model from overfitting.
Increasing Training Data: Providing more diverse and representative training data can help the model capture the underlying patterns and reduce the likelihood of overfitting.
(10) Models Prone To Overfitting.
- Certain types of models are more prone to overfitting due to their flexibility and complexity. Here are some examples:
Decision Trees and Random Forests: Decision trees have the ability to create complex decision boundaries and can easily overfit if allowed to grow too deep or if the number of splits is not controlled. Random forests, which are ensembles of decision trees, can also be prone to overfitting if the individual trees are allowed to become too deep or if the ensemble size is too large.
Deep Neural Networks: Deep neural networks with many layers and a large number of parameters have a high capacity to learn intricate patterns. However, when the network becomes too complex relative to the available training data, it can overfit by memorizing the training examples and failing to generalize well to new instances.
Support Vector Machines (SVMs) with High-Dimensional Kernels: SVMs with high-dimensional kernels, such as polynomial or Gaussian radial basis function (RBF) kernels, can create complex decision boundaries. If the kernel parameters are not properly tuned or if the model is over-optimized for the training data, it can lead to overfitting.
K-Nearest Neighbors (KNN): KNN is a non-parametric algorithm that classifies instances based on their proximity to labelled instances. It can be prone to overfitting if the value of K is set too small, resulting in over-reliance on local patterns and noise in the training data.
Gradient Boosting Machines (GBMs): GBMs, such as XGBoost or LightGBM, are powerful ensemble models that sequentially build weak learners to minimize the model’s loss function. If the boosting process continues for too long or the weak learners are too complex, GBMs can overfit the training data and have difficulty generalizing to new data.
- It’s important to note that the propensity for overfitting depends not only on the model but also on the specific dataset and the training procedure.
- Regularization techniques, such as applying dropout in neural networks, limiting the depth of decision trees, or using early stopping during training, can help mitigate overfitting.
- Additionally, techniques like cross-validation and hyperparameter tuning are valuable for finding the right balance between model complexity and generalization.