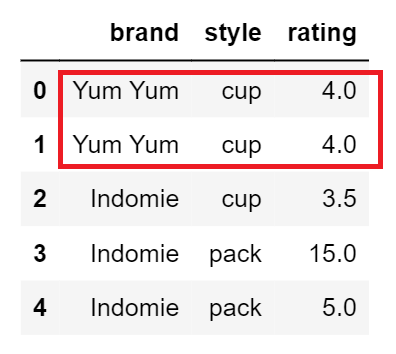
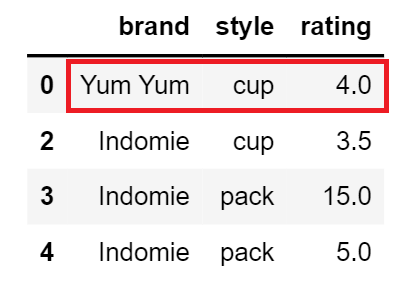
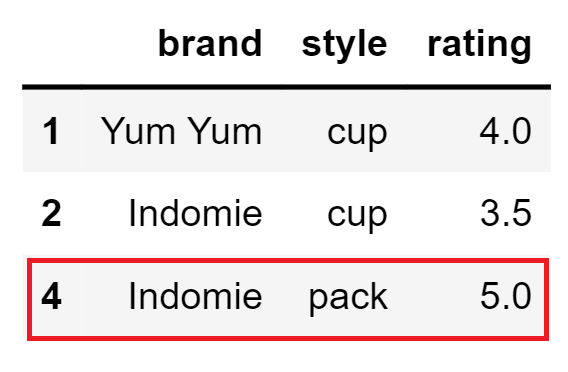
Considering certain columns is optional. Indexes, including time indexes, are ignored.
Parameters:
subset: column label or sequence of labels, optional –
Only consider certain columns for identifying duplicates, by default use all of the columns.
keep: {‘first’, ‘last’, False}, default ‘first’ –
Determines which duplicates (if any) to keep. – first : Drop duplicates except for the first occurrence. – last : Drop duplicates except for the last occurrence. – False : Drop all duplicates.
in place: bool, default False –
Whether to modify the DataFrame rather than create a new one.
ignore_index: bool, default False –
If True, the resulting axis will be labeled 0, 1, …, n – 1.
Returns:
DataFrame or None – DataFrame with duplicates removed or None if inplace=True.